python pandas库读取行或列
Westin_Li 人气:0引言
关键!!!!使用loc函数来查找。
话不多说,直接演示:
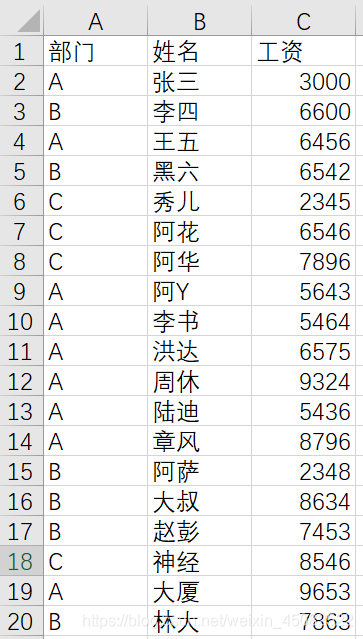
有以下名为try.xlsx表:
1.根据index查询
条件:首先导入的数据必须的有index
或者自己添加吧,方法简单,读取excel文件时直接加index_col
代码示例:
import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入excel数据 data = pd.read_excel(excel_file, index_col='姓名') #这个的index_col就是index,可以选择任意字段作为索引index,读入数据 print(data.loc['李四'])
打印结果就是
部门 B
工资 6600
Name: 李四, dtype: object
(注意点:索引)
2.已知数据在第几行找到想要的数据
假如我们的表中,有某个员工的工资数据为空了,那我们怎么找到自己想要的数据呢。
代码如下:
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]:
bumen = data.iloc[j, [0]] #找出缺失值所在的部门
data[i][j] = charuzhi(bumen)
原理很简单,首先检索全部的数据,然后我们可以用pandas中的iloc函数。上面的iloc[j, [2]]中j是具体的位置,【0】是你要得到的数据所在的column
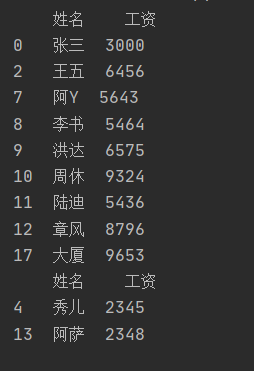
3.根据条件查询找到指定行数据
例如查找A部门所有成员的的姓名和工资或者工资低于3000的人:
代码如下:
"""根据条件查询某行数据""" import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入文件 data = pd.read_excel(excel_file) #读入数据 print(data.loc[data['部门'] == 'A', ['姓名', '工资']]) #部门为A,打印姓名和工资 print(data.loc[data['工资'] < 3000, ['姓名','工资']]) #查找工资小于3000的人
结果如下:
若要把这些数据独立生成excel文件或者csv文件:
添加以下代码
"""导出为excel或csv文件"""
#单条件
dataframe_1 = data.loc[data['部门'] == 'A', ['姓名', '工资']]
#单条件
dataframe_2 = data.loc[data['工资'] < 3000, ['姓名', '工资']]
#多条件
dataframe_3 = data.loc[(data['部门'] == 'A')&(data['工资'] < 3000), ['姓名', '工资']]
#导出为excel
dataframe_1.to_excel('dataframe_1.xlsx')
dataframe_2.to_excel('dataframe_2.xlsx')
4.找出指定列
data['columns'] #columns即你需要的字段名称即可 #注意这列的columns不能是index的名称 #如果要打印index的话就data.index data.columns #与上面的一样
以上全过程用到的库:
pandas,xlrd , openpyxl
5.找出指定的行和指定的列
主要使用的就是函数iloc
data.iloc[:,:2] #即全部行,前两列的数据
逗号前是行,逗号后是列的范围,很容易理解
6.在规定范围内找出符合条件的数据
data.iloc[:10,:][data.工资>6000]
这样即可找出前11行里工资大于6000的所有人的信息了
总结
加载全部内容