pandas数据合并与拼接
xiejava1018 人气:0前言
在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集。pandas提供了多种方法完全可以满足数据处理的常用需求。具体来说包括有join、merge、concat、append等。

一般来说
| 方法 | 说明 |
|---|---|
| join | 最简单,主要用于基于索引的横向合并拼接 |
| merge | 最常用,主要用户基于指定列的横向合并拼接 |
| concat | 最强大,可用于横向和纵向合并拼接 |
| append | 主要用于纵向追加 |
| combine_first | 合并重叠数据,填充缺失值 |
| update | 将一个数据集的值更新到另一个数据集 |
下面就来逐一介绍每个方法
一、join
join主要用于基于索引的横向合并拼接
在介绍pandas的join之前我们来看一下SQL对数据集join的几种模式。如果大家对SQL比较熟悉的话应该对SQL操作数据集进行各种合并拼接印象深刻。SQL中各种JOIN的方法如下:
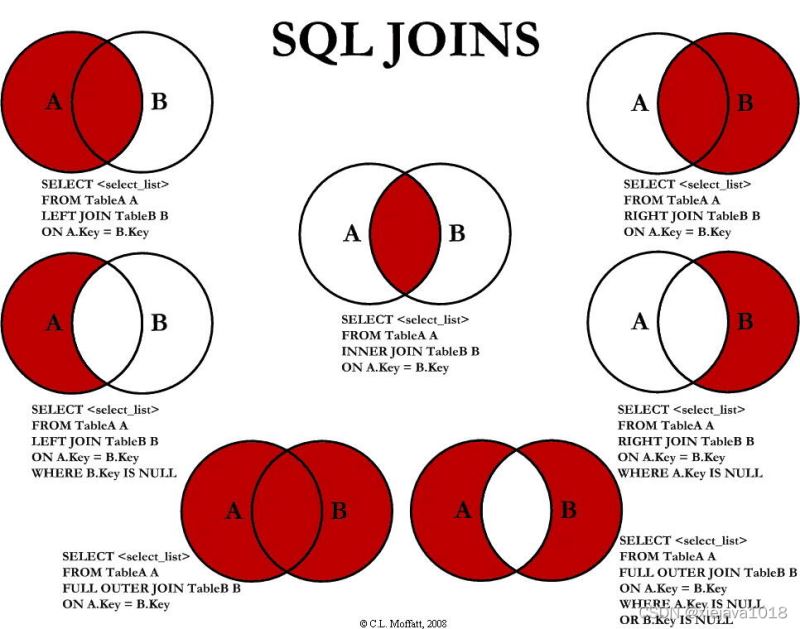
pandas的join实现了left join、right jion、inner join、out jion常用的4中join方法
来自官网的参数说明:
dataframe.join(other, # 待合并的另一个数据集
on=None, # 连接的键
how='left', # 连接方式:‘left', ‘right', ‘outer', ‘inner' 默认是left
lsuffix='', # 左边(第一个)数据集相同键的后缀
rsuffix='', # 第二个数据集的键的后缀
sort=False) # 是否根据连接的键进行排序;默认False
我们来看下实例,有两个数据集一个是人员姓名,一个是人员的工资
left=pd.DataFrame(['张三','李四','王五','赵六','钱七'], index=[3,4,5,6,7],columns=['姓名']) right=pd.DataFrame([13000,15000,9000,8600,10000], index=[3,4,5,6,8],columns=['工资'])

注意,left和right的数据集分别都指定了index,因为join主要用于基于索引的横向合并拼接。
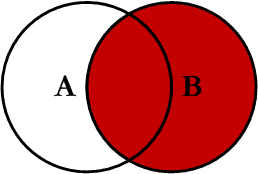
1、left join
left.join(right) #默认how='left'
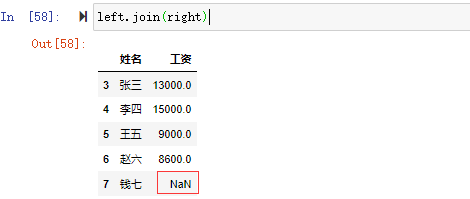
jion操作默认是left jion的操作,可以看到left索引为7姓名为钱七,在right中没有索引为7的对应所以显示left的姓名但right的工资为NaN,right中索引为8的数据在left中没有索引为8的,所以没有显示。left join合并left的数据
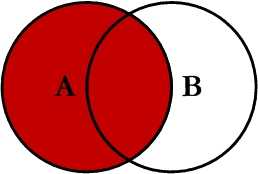
left join 如下图所示
2、right join
left.join(right,how='right')
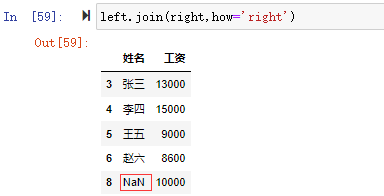
右链接合并时可以看到,left的数据集没有索引为8的项,所以索引为8的项显示right数据集的工资数据但姓名为NaN,在left中索引为7的项因为right中不存在,所以没有显示。right join合并right的数据
right join 如下图所示
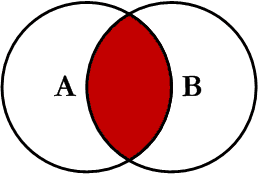
3、inner join
left.join(right,how='inner')

内链接合并时,可以看到left数据集中的索引为7姓名为钱七因为在right数据集中找不到对应的索引,right数据集中索引为8的在left找不到对应的索引所以内连接合并时索引7和8都没有进行合并,inner join只合并两个数据集共有的数据
inner join 如下图所示
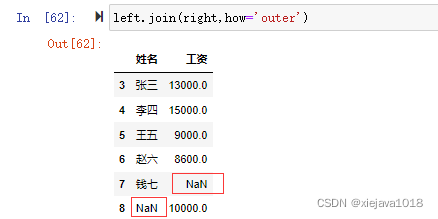
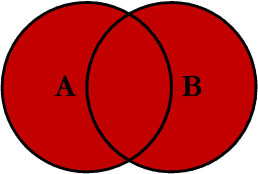
4、out join
left.join(right,how='outer')
外链接合并时,可以看到不管是left中的数据还是right中的数据都进行了合并。right join合并两个数据集中所有的数据。
outer join 如下图所示
join很简单,但是它有局限性,因为它只能根据索引来合并。不能指定键来进行合并。比如我要根据编号和姓名来合并,join就比较难办了。但是pandas提供了merge的方法,可以指定列来进行合并拼接。
二、merge
merge最常用,主要用户基于指定列和横向合并拼接,语法如下:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,suffixes=('_x', '_y'), copy=True)
| 参数名称 | 说明 |
|---|---|
| left/right | 两个不同的 DataFrame 对象。 |
| on | 指定用于连接的键(即列标签的名字),该键必须同时存在于左右两个 DataFrame 中,如果没有指定,并且其他参数也未指定, 那么将会以两个 DataFrame 的列名交集做为连接键。 |
| left_on | 指定左侧 DataFrame 中作连接键的列名。该参数在左、右列标签名不相同,但表达的含义相同时非常有用。 |
| right_on | 指定左侧 DataFrame 中作连接键的列名。 |
| left_index | 布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键,若 DataFrame 具有多层索引(MultiIndex),则层的数量必须与连接键的数量相等。 |
| right_index | 布尔参数,默认为 False。如果为 True 则使用左侧 DataFrame 的行索引作为连接键。 |
| how | 要执行的合并类型,从 {‘left’, ‘right’, ‘outer’, ‘inner’} 中取值,默认为“inner”内连接。 |
| sort | 布尔值参数,默认为True,它会将合并后的数据进行排序;若设置为 False,则按照 how 给定的参数值进行排序。 |
| suffixes | 字符串组成的元组。当左右 DataFrame 存在相同列名时,通过该参数可以在相同的列名后附加后缀名,默认为(’_x’,’_y’)。 |
| copy | 默认为 True,表示对数据进行复制。 |
我们来看下面的数据集,在上面的数据集中left数据集加入了员工的编号,right数据集加入了编号及姓名。索引就按默认的索引。
left=pd.DataFrame([[3,'张三'],[4,'李四'],[5,'王五'],[6,'赵六'],[7,'钱七']], columns=['编号','姓名']) right=pd.DataFrame([[3,'张三',13000],[4,'李四',15000],[5,'王五',9000],[6,'赵六',8600],[8,'孙八',10000]], columns=['编号','姓名','工资'])
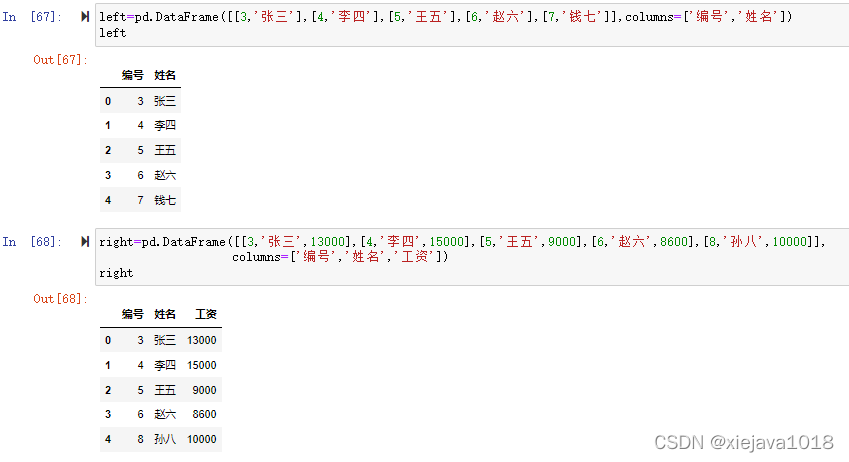
pd.merge(left,right)
没有指定连接键,默认用重叠列名,没有指定连接方式,默认inner内连接(取left和right编号和姓名的交集)
和join一样通过how来指定连接方式如:
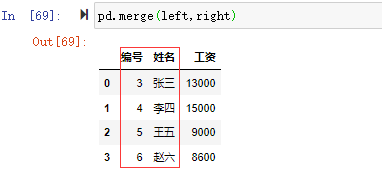
pd.merge(left,right,how='left')
how的连接方式和join一样支持left、right、inner、outer
merge还可以指定多个列进行合并链接,也就是和SQL一样设置多个关联的列。
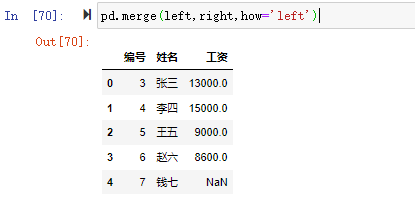
pd.merge(left,right,how='outer',on=['编号','姓名'])
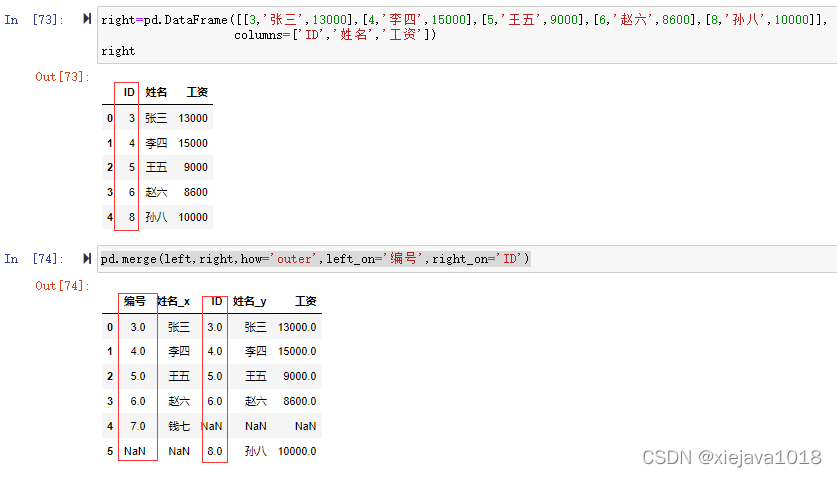
如果两个对象的列名不同,可以使用left_on,right_on分别指定,如我们把right数据集的“编码”列标签改成“ID”后如果需要left数据集的"编号"和right数据集的"ID"进行关联
right=pd.DataFrame([[3,'张三',13000],[4,'李四',15000],[5,'王五',9000],[6,'赵六',8600],[8,'孙八',10000]],columns=['ID','姓名','工资']) pd.merge(left,right,how='outer',left_on='编号',right_on='ID')
虽然说merge已经很强大了,但是pandas愿意给你更多,它提供了concat,可以实现横向和纵向的合并与拼接。也就是说不但实现了SQL中的join还实现了union
三、concat
concat() 函数用于沿某个特定的轴执行连接操作,语法如下:
pd.concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False)
| 参数名称 | 说明 |
|---|---|
| objs | 一个序列或者是Series、DataFrame对象。 |
| axis | 表示在哪个轴方向上(行或者列)进行连接操作,默认 axis=0 表示行方向。 |
| join | 指定连接方式,取值为{“inner”,“outer”},默认为 outer 表示取并集,inner代表取交集。 |
| ignore_index | 布尔值参数,默认为 False,如果为 True,表示不在连接的轴上使用索引。 |
| join_axes | 表示索引对象的列表。 |
来看具体的例子
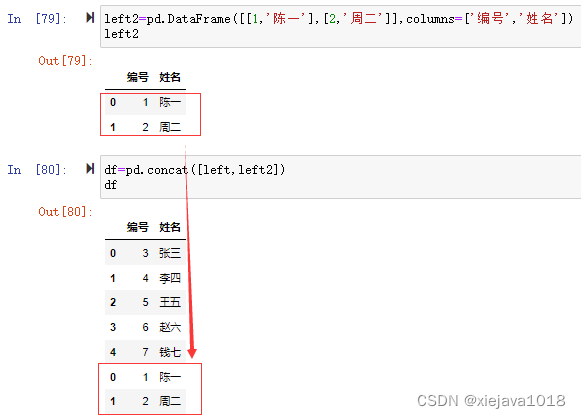
left2=pd.DataFrame([[1,'陈一'],[2,'周二']],columns=['编号','姓名'])

1、纵向合并
concat默认纵向拼接,我们要在left1数据集的基础上把left2数据集给合并上去,很简单用concat直接就可以合并。
df=pd.concat([left,left2])
2、横向合并
df_outer=pd.concat([left,right],axis=1,join='outer')#外链接 df_inner=pd.concat([left,right],axis=1,join='inner')#内链接
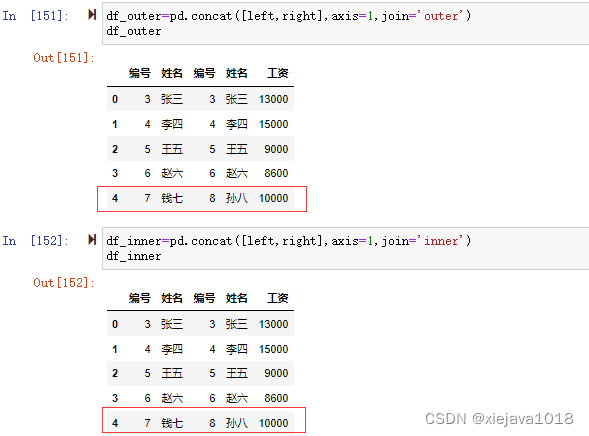
注意:因为concat的链接和join一样是通过索引来链接合并,并不能指定通过某个特定的列来链接进行合并,所以看到的合并后的数据集left和right的编号和姓名是错位的。
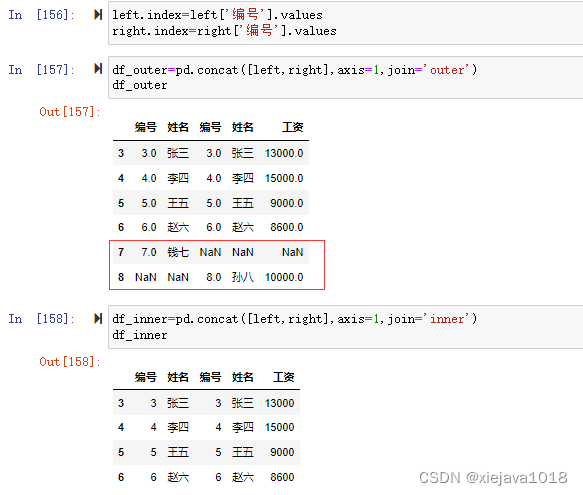
如果要根据编号来关联可以指定编号作为索引再进行横向合并,这样就没有问题了。
left.index=left['编号'].values right.index=right['编号'].values df_outer=pd.concat([left,right],axis=1,join='outer') df_inner=pd.concat([left,right],axis=1,join='inner')
四、append
df.append 可以将其他行附加到调用方的末尾,并返回一个新对象。它是最简单常用的数据合并方式。语法如下:
df.append(self, other, ignore_index=False,verify_integrity=False, sort=False)
其中:
- other 是它要追加的其他 DataFrame 或者类似序列内容
- ignore_index 如果为 True 则重新进行自然索引
- verify_integrity 如果为 True 则遇到重复索引内容时报错
- sort 进行排序
来看下面的例子:
1、同结构数据追加
将同结构的数据追加在原数据后面,在left数据集后面追加left2数据集,left2的数据集内容如下:
left2=pd.DataFrame([[1,'陈一'],[2,'周二']],columns=['编号','姓名']) left2

left.append(left2)
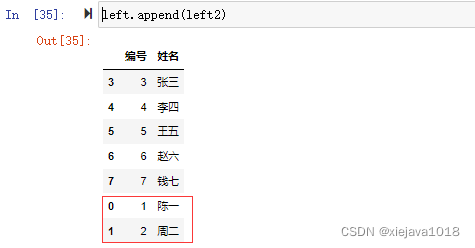
2、不同结构数据追加
不同结构数据追加,原数据没有的列会增加,没有对应内容的会为空NaN。
如:left3的数据集列有"编号"、“姓名”、“工资”
left3=pd.DataFrame([[8,'孙八',10000],[9,'何九',15000]],columns=['编号','姓名','工资']) left3

left.append(left3)
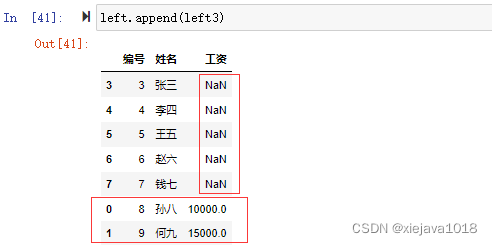
当left后追加left3后的数据集会增加“工资列”,没有对应内容的会为空。
3、追加合并多个数据集
append参数可带数据集列表,可以将多个数据集追加到原数据集
如我们将left2和left3都追加到left
left.append([left2,left3])
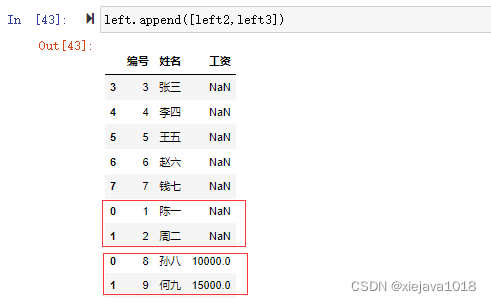
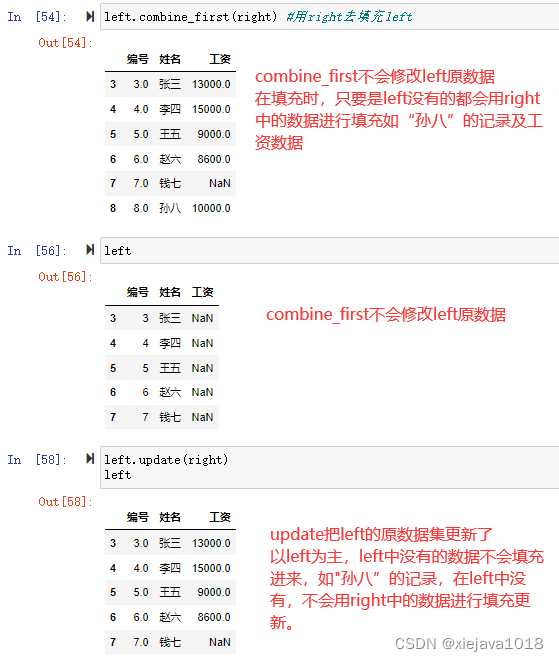
五、combine_first
combine_first可用于合并重复数据,用其他数据集填充没有的数据。如一个DataFrame数据集中出现了缺失数据,就可以用其他DataFrame数据集中的数据进行填充。语法格式如下:
combine_first(other) #只有一个参数other,该参数用于接收填充缺失值的DataFrame对象。
如left数据集中没有"工资"的数据,我们可以用right数据集有的数据去填充left数据集中的数据。
left.combine_first(right) #用right去填充left
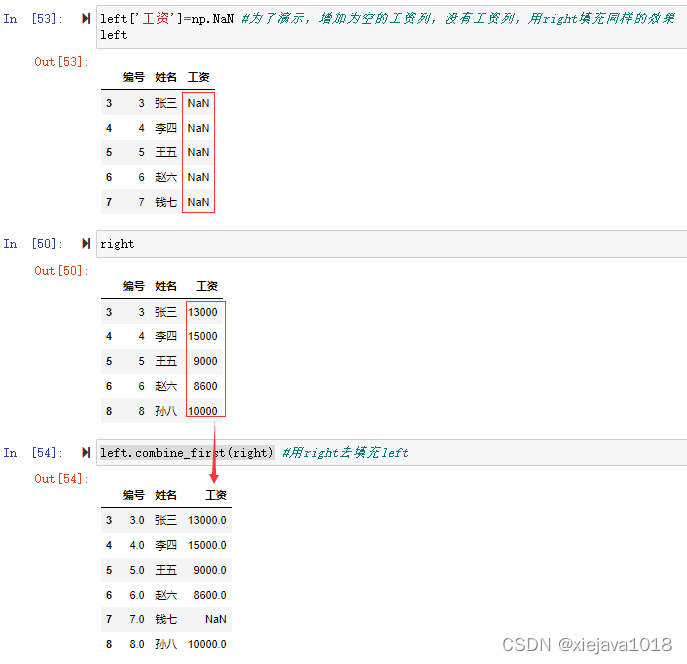
六、update
update和combine_first比较类似,区别在于:
1、填充合并方式稍有差异
combine_first:如果s1中c的值为空,用s2的值替换,否则保留s1的值
update:如果s2中的值不为空,那么替换s1,否则保留s1的值
2、update是更新原数据,combine_first会返回一个填充后的新数据集,对原数据不做更新。
left.update(right) #用right的数据更新left中的数据。
至此,本文介绍了pandas的多种数据合并与拼接方法,并介绍了每种方法的异同,通过pandas的数据处理可以应付日常数据处理中大部分的数据处理工作。
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
总结
加载全部内容