python爬取电脑壁纸
密发渐消 人气:0前言
听说好的编程习惯是从写文章敲代码开始的,下面给大家介绍一个简单的python爬取图片的过程,超简单。我都不好意思写,但是主要是捋一下爬取过程。本文只是技术交流的,请不要商业用途哈
一、用到的工具



使用python爬虫工具,我使用的工具就是学习python都会用的的工具,一个是pycharm,一个是chrome,使用chrome只是我的个人习惯,也可以用其他的浏览器,我除了这两个软件还用到了window自带的浏览器。
二、爬取步骤与过程
1.用到的库
爬取图片我主要用到了爬虫初学的requests请求模块和xpath模块,这用xpath只是为了方便找图片的链接和路径的,当然也可以用re模块和Beautiful Soup模块这些。time模块是为了后续下载图片做延时的,毕竟要保护下网站,Pinyin模块里面有个程序要将中文转成拼音。
import time import pinyin import requests from lxml import etree #这是导入xpath模块
2.解析代码
首先输入选择图片类型和图片的也网址页码,因为一种类型的图片有很多图片的,一个网页是放不下的这就需要选择多个页码。
type=input("请输入图片的类型:")
type=pinyin.get(f"{type}",format="strip") #这是将输入的中文转成拼音,format是为了去掉拼音的声标
m=input("请输入图片的页码:") #图片类型所在网页的页码接下来就请求网址了,其中先获取网址的源代码,然后通过xpath获取图片的链接和名字,为什么是小图片呢,因为一个网页要显示很多图片,如果是大图片,一个网页只能放一张的。


url=f"http://pic.netbian.com/4k{type}/index_{m}.html"
header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
resp=requests.get(url=url,headers=header)
resp.encoding="gbk"
tree=etree.HTML(resp.text)
tu_links=tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') #小图片的链接
tu_names=tree.xpath('//*[@id="main"]/div[3]/ul/li/a/b/text()') #图片的名字接下来就是一层一层的找图片的链接,和下载地址,也就是一个查找的循环操作。
tu_link.split()
child_url = url.split(f'/4k{type}/')[0] + tu_link #将小图片的部分链接和主链接拼接起来
resp1 = requests.get(url=child_url, headers=header) #打开小图片的网址
resp1.encoding = 'gbk'
tree1 = etree.HTML(resp1.text)
child_tu_link= tree1.xpath('/html/body/div[2]/div[1]/div[2]/div[1]/div[2]/a/img/@src') #获取大图片的部分链接
child_tu_link=child_tu_link[0]
child_tu_link_over=url.split(f'/4k{type}/')[0]+child_tu_link #将大图片链接拼接起来
resp2=requests.get(child_tu_link_over,headers=header) #获取大图片最后就是下载图片啦
with open(f"壁纸图片/{name}.jpg",mode="wb") as f: #接下来就是下载了
f.write(resp2.content)来看看最后的效果吧
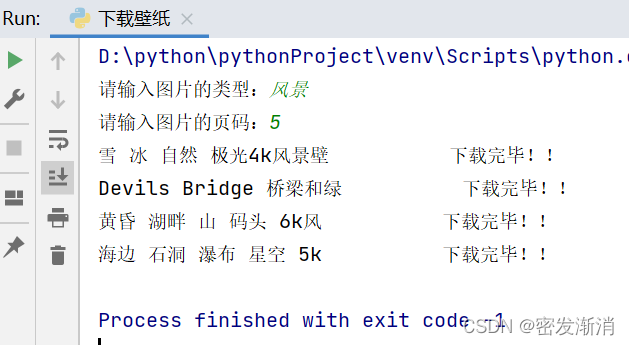


3.最后上全部的代码啦
这就是简简单单的爬取图片的代码,完全没有用到什么复杂的知识,简简单单,你值得拥有哈哈
import time
import pinyin
import requests
from lxml import etree #这是导入xpath模块
type=input("请输入图片的类型:")
type=pinyin.get(f"{type}",format="strip") #这是将输入的中文转成拼音,format是为了去掉拼音的声标
m=input("请输入图片的页码:") #图片类型所在网页的页码
url=f"http://pic.netbian.com/4k{type}/index_{m}.html"
header={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36"
}
resp=requests.get(url=url,headers=header)
resp.encoding="gbk"
tree=etree.HTML(resp.text)
tu_links=tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href') #小图片的部分链接
tu_names=tree.xpath('//*[@id="main"]/div[3]/ul/li/a/b/text()') #图片的名字
n=0
for tu_link in tu_links:
tu_link.split()
child_url = url.split(f'/4k{type}/')[0] + tu_link #将小图片的部分链接和主链接拼接起来
resp1 = requests.get(url=child_url, headers=header) #打开小图片的网址
resp1.encoding = 'gbk'
tree1 = etree.HTML(resp1.text)
child_tu_link= tree1.xpath('/html/body/div[2]/div[1]/div[2]/div[1]/div[2]/a/img/@src') #获取大图片的部分链接
child_tu_link=child_tu_link[0]
child_tu_link_over=url.split(f'/4k{type}/')[0]+child_tu_link #将大图片链接拼接起来
resp2=requests.get(child_tu_link_over,headers=header) #获取大图片
name=tu_names[n]
with open(f"壁纸图片/{name}.jpg",mode="wb") as f: #接下来就是下载了
f.write(resp2.content)
print(f"{name} 下载完毕!!")
n+=1 #每下载一张图片n就加1
time.sleep(1.5)
resp1.close()
print("全部下载完毕!!") #over!over!
resp.close() #最后记得要把所有请求的响应关闭
注意:本文章只用于技术交流,请勿用于商用,如有违反,吾概不负责!!!
总结
加载全部内容