nacos客户端一致性hash负载
自成溪 人气:0最近接到一个需求,由于文件服务器上传文件后,不同节点之间共享文件需要延迟,上游上传文件后立刻去下载,如果负载到其他节点上可能会找不到文件,所以使用文件服务器接入nacos根据相同的trace_id路由到一个节点上,这样保证上传后立刻下载的请求都能路由到同一个节点上,研究了两天nacos原生的client发现并没有提供相关功能,于是便产生了一个想法,手撸一个客户端负载。
要想同一个trace_id需要路由到相同的节点上,首先想到的方法就是利用hash算法,目前常用于分布式系统中负载的哈希算法分为两种:
1.普通hash取模
2.一致性hash
普通hash虽然开发起来快,看起来也满足需求,但是当集群扩容或者缩容的时候,就会造成trace_id的hash结果与之前不同,可能不会路由到一个节点上。
而一致性hash在扩容缩容时只会影响哈希环中顺时针方向的相邻的节点, 对其他节点无影响。但是缺点时数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,不过根据选择适当的hash算法也可以避免这个缺点,让数据相对均匀的在hash环上分布。
网上关于一致性hash的讨论已经有很多了,在这里就放一张图便于大家理解。
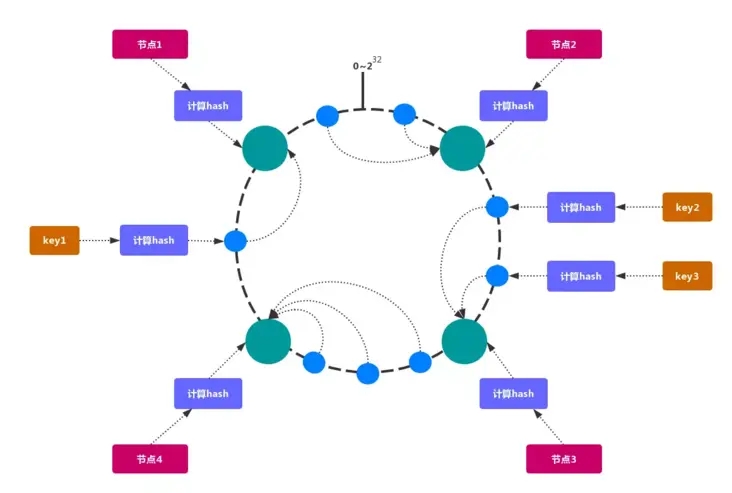
其他的不说,先上代码
1.首先创建NacosClient,监听对应的服务:
public class NacosClient {
//nacos监听器,处理初始化hash环等逻辑
private Nodelistener nodelistener;
//初始化nacosClient,并且监听服务
public void init() {
NamingService naming = null;
try {
System.out.println(System.getProperty("serveAddr"));
naming = NamingFactory.createNamingService(System.getProperty("serveAddr"));
//注册监听器,当集群节点变化的时候调用nodelistener处理节点信息
naming.subscribe("test", event -> {
if (event instanceof NamingEvent) {
nodelistener.handlerChange((NamingEvent)event);
}
});
} catch (NacosException e) {
e.printStackTrace();
}
}
}2.创建Nodelistener,主要处理构建hash环等逻辑:
public class Nodelistener {
private List<Instance> servers;
//利用treeMap构建hash环
private volatile SortedMap<Long, Instance> sortedMap = new TreeMap<Long, Instance>();
//虚拟节点
private int virtualNodeCount = 100;
public synchronized void handlerChange(NamingEvent event) {
List<Instance> servers = new ArrayList<Instance>();
event.getInstances().stream().filter(instance -> {
return instance.isEnabled() && instance.isHealthy();
}).forEach(instance -> servers.add(instance));
this.onChange(servers);
}
//每次集群节点变化时,重新构建hash环
public void onChange(List<Instance> servers) {
//只有一个节点的时候这里暂不考虑,读者可以自行处理
if(servers.size() != 1) {
SortedMap<Long, Instance> newSortedMap = new TreeMap<Long, Instance>();
for (int i = 0; i < servers.size(); i ++) {
for (int j = 0; j < this.virtualNodeCount; j++) {
//计算虚拟节点的hash,这里用到的是MurMurHash,网上还有很多其他hash实现,
//有兴趣可以自行查阅,具体实现细节就不列出了
Long hash = HashUtil.getHash(servers.get(i).getIp() + ":" +
servers.get(i).getPort() + j);
//把虚拟节点加入hash环
sortedMap.put(hash, servers.get(i));
}
}
sortedMap = newSortedMap;
}
this.servers = servers;
}
//根据传入的key获取hash环上顺时针到hash环尾部部分所有节点
public Instance getInstance(String str) {
Long hash = HashUtil.getHash(str);
SortedMap<Long, Instance> map = sortedMap.tailMap(hash);
//这里证明刚好获取的是尾部,所以返回所有的节点,其实是获取第一个节点
if (map.isEmpty()) {
map = sortedMap;
}
return map.get(map.firstKey());
}
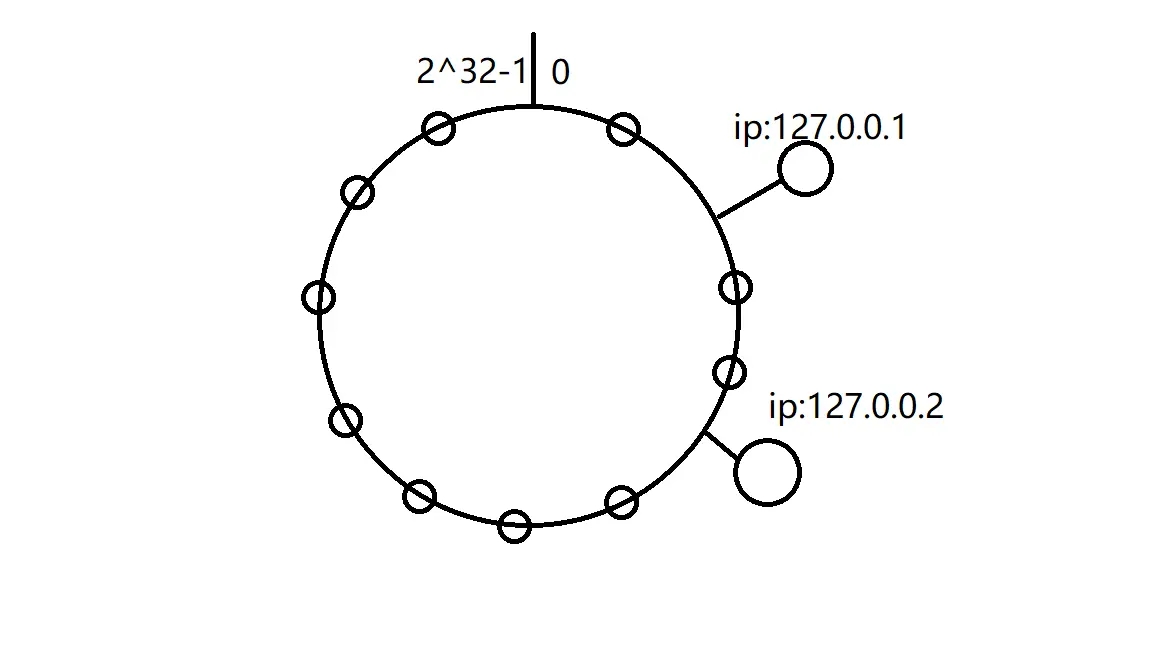
}其中,虚拟节点是一致性hash经常用到的,主要是用于解决hash倾斜问题,即节点数比较少时,数据落在hash环上会造成不均衡,下图即没有虚拟节点的情况:
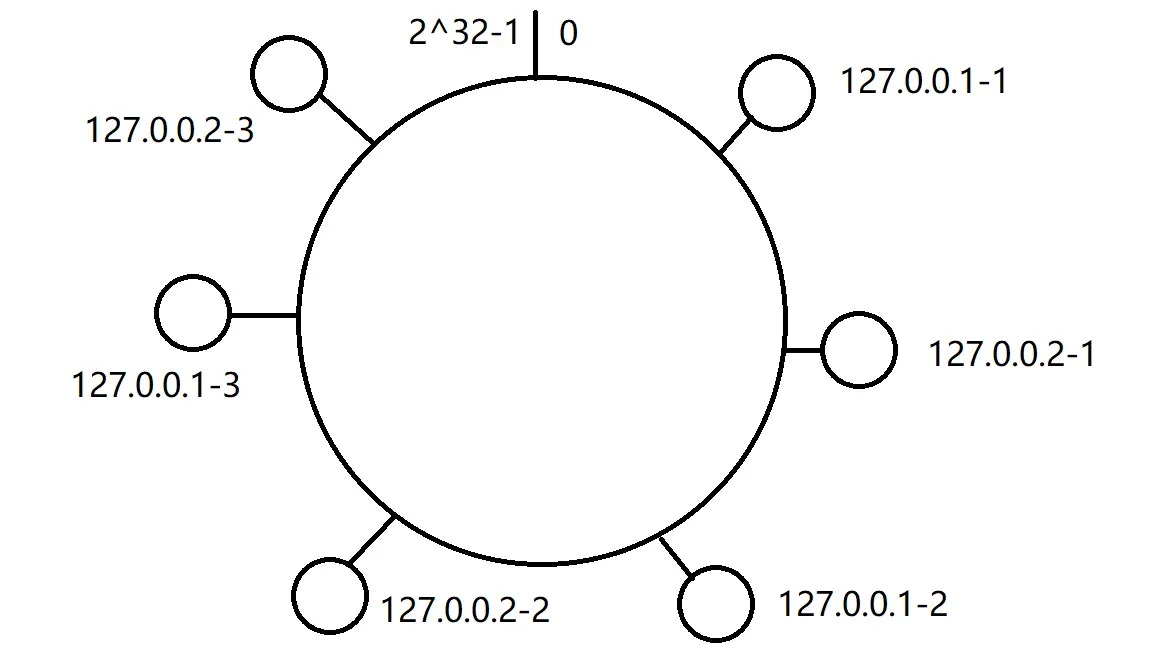
有虚拟节点的情况,这样hash环就均匀分割,相应数据落入的区间也会平衡:
3.负载均衡器:
public class LoadBalance {
private Nodelistener nodelistener;
//只需要简单的从hash环中获取第一个节点
public Instance doSelect(String key) {
return nodelistener.getInstance(key);
}
}测试下结果:
public void test2() {
Map<String, Integer> map = new HashMap<String, Integer>();
Random random = new Random();
for (int i = 0; i < 10000; i ++) {
String key = String.valueOf(random.nextLong());
Instance instance = loadBalance.doSelect(key);
if(!map.containsKey(instance.getIp())) {
map.put(instance.getIp(), 0);
}else {
map.put(instance.getIp(), map.get(instance.getIp()) + 1);
}
System.out.println("test2 count :" + i);
System.out.printf("select IP is :" + instance.getIp());
}
System.out.println(map.toString());
}此处为了方便就直接用随机数模拟trace_id,结果如下:
select IP is :127.0.0.0{127.0.0.4=2031, 127.0.0.3=2144, 127.0.0.2=1925, 127.0.0.1=1931, 127.0.0.0=1964}
可以看到10000次请求被均匀的分布到了4个节点上。
思考:
1. 本次我们使用到了treeMap构建hash环,那么treeMap构建的hash具体的查找效率如何呢?
treeMap是由红黑树构成的,其 containsKey(),get(),put(), remove() 方法时间复杂度均为O(logn),均是对数阶,已经算相当不错了。
2.在Nodelistener 中我们两个方法都使用了synchronized 这样会有什么影响?
首先因为treeMap是线程不安全的,所以我们都使用了方法级别的synchronized,所以两个方法不会同时执行,这样使用treeMap时,不会造成线程不安全问题,其次可以保证我们在获取hash环中节点的时候,treeMap不会因为节点变化而变化。但是这样处理的话就会产生一个问题,我们正在计算trace_id的路由节点时,机器不巧缩容了,treeMap还没进行更新,刚好路由到的节点时下线的机器,那么就会访问失败,笔者这里解决这个问题的思路是重试,如果失败获取下一个节点,此时文件服务器不同节点之间文件已经同步完毕,所以不同节点访问是没问题的。
public void test(String key) throws InterruptedException {
//这里可以设置重试次数
for (;;) {
Instance instance = loadBalance.doSelect(key);
String addr = instance.getIp() + ":" + instance.getPort();
//测试请求
if(post(addr)) {
//成功逻辑
.....
break;
}else {
//等待两秒,即可以使文件服务器不同节点之间同步文件,还可以等待更新本地hash环
Thread.sleep(2000);
//失败则选取下一个节点
instance = loadBalance.doSelect(key);
//此处可以增加重试次数逻辑和如果重试到hash环上最后一个节点则重新获取hash环第一个节点逻辑,
// 在此就不做论述,读者可以自由发挥
continue;
}
}
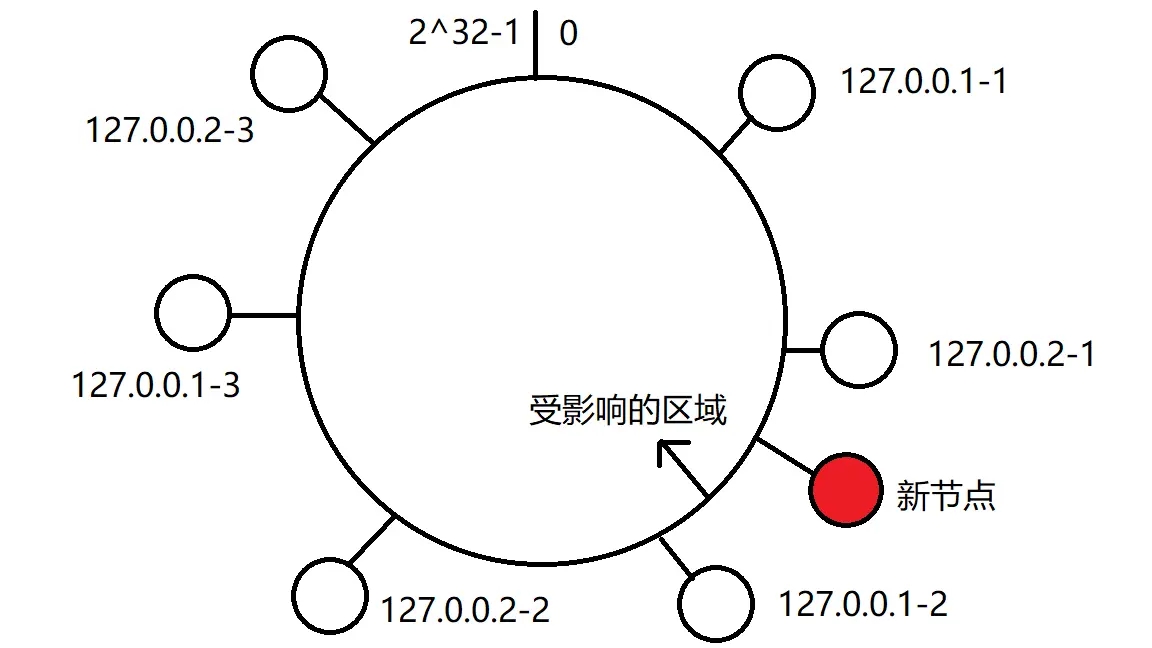
}那么我们考虑当我们计算trace_id路由时,正好扩容的情况,此时treeMap还没有进行更新,情况如下图,我们路由到的节点如果不是图中标记的受影响区域则不会有影响,如果是图中受影响的区域计算得出的路由是扩容前的也就是 127.0.0.2-1(真实节点是127.0.0.2),那么下次相同的trace_id则会路由到新节点,此时会出现同一个trace_id路由到的节点不一样的问题,笔者在此处也使用的重试机制。(其实这个地方可以使用缓存Key和节点的关系,扩容后关系改变之后再改变图中受影响的hash环,但是因为trace_id比较特殊,并不适合缓存所有,所以使用了重试机制)
3.每次探知到服务器节点变化的时候都需要重新构建hash环,这样操作会比较耗时,可以修改成每次节点变化只需要改变对应虚拟节点信息,更新本地hash环时间,可以将onChange方法改造下。
public void onChange(List<Instance> newServers) {
//单节点时这里暂不考虑
if(servers.size() != 1 ) {
//TODO ..
}
Map<String, Instance> oldAddrs =
this.servers.stream()
.collect(Collectors.toMap(Instance::toInetAddr, instance -> instance));
Map<String, Instance> newAddrs =
newServers.stream()
.collect(Collectors.toMap(Instance::toInetAddr, instance -> instance));
//remove
oldAddrs.forEach((key, value) -> {
if (!newAddrs.containsKey(key)) {
for(int j = 0; j < virtualNodeCount; j++) {
Long hash = HashUtil.getHash( value.toInetAddr() + "&&VM"+ j);
sortedMap.remove(hash);
}
}
});
//add
newAddrs.forEach((key, value) -> {
if (!oldAddrs.containsKey(key)) {
for(int j = 0; j < virtualNodeCount; j++) {
Long hash = HashUtil.getHash(value.toInetAddr() + "&&VM" + j);
sortedMap.put(hash, value);
}
}
});
this.servers = newServers;
}加载全部内容