Spring一级缓存、二级缓存和三级缓存
君战 人气:0题记
常常听到别人提起:“一级缓存、二级缓存、三级缓存”。那么它们是什么呢?有什么作用呢?
缓存作用分析
Spring中的一级缓存名为singletonObjects,二级缓存名为earlySingletonObjects,三级缓存名为singletonFactories,除了一级缓存是ConcurrentHashMap之外,二级缓存和三级缓存都是HashMap。它们的定义是在DefaultSingletonBeanRegistry类中。
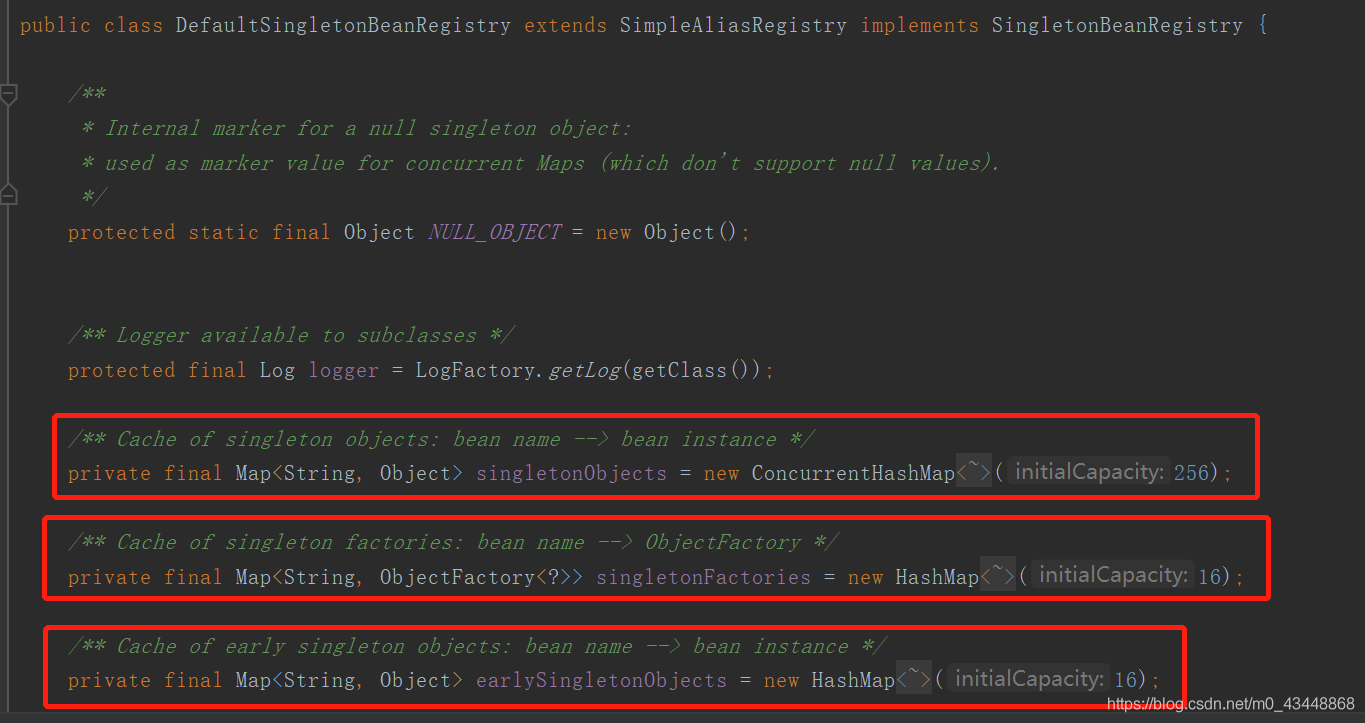
一级缓存-singletonObjects是用来存放就绪状态的Bean。保存在该缓存中的Bean所实现Aware子接口的方法已经回调完毕,自定义初始化方法已经执行完毕,也经过BeanPostProcessor实现类的postProcessorBeforeInitialization、postProcessorAfterInitialization方法处理;
二级缓存-earlySingletonObjects是用来存放早期曝光的Bean,一般只有处于循环引用状态的Bean才会被保存在该缓存中。保存在该缓存中的Bean所实现Aware子接口的方法还未回调,自定义初始化方法未执行,也未经过BeanPostProcessor实现类的postProcessorBeforeInitialization、postProcessorAfterInitialization方法处理。如果启用了Spring AOP,并且处于切点表达式处理范围之内,那么会被增强,即创建其代理对象。
这里额外提一点,普通Bean被增强(JDK动态代理或CGLIB)的时机是在AbstractAutoProxyCreator实现的BeanPostProcessor的postProcessorAfterInitialization方法中,而处于循环引用状态的Bean被增强的时机是在AbstractAutoProxyCreator实现的SmartInstantiationAwareBeanPostProcessor的getEarlyBeanReference方法中。
三级缓存-singletonFactories是用来存放创建用于获取Bean的工厂类-ObjectFactory实例。在IoC容器中,所有刚被创建出来的Bean,默认都会保存到该缓存中。
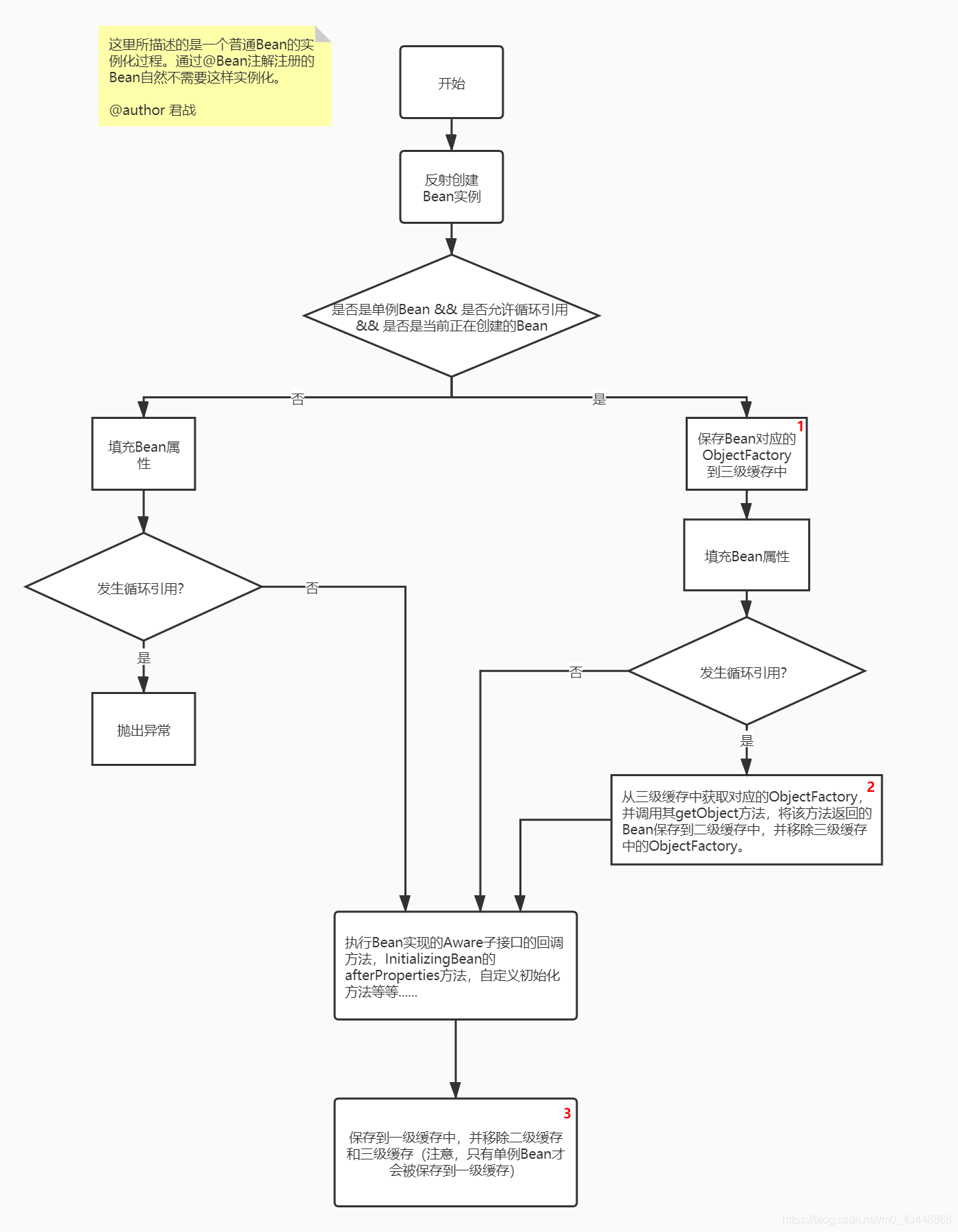
Bean在这三个缓存之间的流转顺序为(存在循环引用):
- 通过反射创建Bean实例。是单例Bean,并且IoC容器允许Bean之间循环引用,保存到三级缓存中。
- 当发生了循环引用时,从三级缓存中取出Bean对应的ObjectFactory实例,调用其getObject方法,来获取早期曝光Bean,从三级缓存中移除,保存到二级缓存中。
- Bean初始化完成,生命周期的相关方法执行完毕,保存到一级缓存中,从二级缓存以及三级缓存中移除。
Bean在这三个缓存之间的流转顺序为(没有循环引用):
- 通过反射创建Bean实例。是单例Bean,并且IoC容器允许Bean之间循环引用,保存到三级缓存中。
- Bean初始化完成,生命周期的相关方法执行完毕,保存到一级缓存中,从二级缓存以及三级缓存中移除。
简略流程图:
一级缓存、二级缓存、三级缓存区别是什么
一级缓存、二级缓存、三级缓存是什么?作用?区别? 首先简单了解一下一级缓存。目前所有主流处理器大都具有一级缓存和二级缓存,少数高端处理器还集成了三级缓存。其中,一级缓存可分为一级指令缓存和一级数据缓存。一级指令缓存用于暂时存储并向CPU递送各类运算指令;一级数据缓存用于暂时存储并向CPU递送运算所需数据,这就是一级缓存的作用。 那么,二级缓存的作用又是什么呢?简单地说,二级缓存就是一级缓存的缓冲器:一级缓存制造成本很高因此它的容量有限,二级缓存的作用就是存储那些CPU处理时需要用到、一级缓存又无法存储的数据。同样道理,三级缓存和内存可以看作是二级缓存的缓冲器,它们的容量递增,但单位制造成本却递减。
需要注意的是,无论是二级缓存、三级缓存还是内存都不能存储处理器操作的原始指令,这些指令只能存储在CPU的一级指令缓存中,而余下的二级缓存、三级缓存和内存仅用于存储CPU所需数据。 根据工作原理的不同,目前主流处理器所采用的一级数据缓存又可以分为实数据读写缓存和数据代码指令追踪缓存2种,它们分别被AMD和Intel所采用。不同的一级数据缓存设计对于二级缓存容量的需求也各不相同,下面让我们简单了解一下这两种一级数据缓存设计的不同之处。
一、AMD一级数据缓存设计 AMD采用的一级缓存设计属于传统的“实数据读写缓存”设计。基于该架构的一级数据缓存主要用于存储CPU最先读取的数据;而更多的读取数据则分别存储在二级缓存和系统内存当中。做个简单的假设,假如处理器需要读取“AMD ATHLON 64 3000+ IS GOOD”这一串数据(不记空格),那么首先要被读取的“AMDATHL”将被存储在一级数据缓存中,而余下的“ON643000+ISGOOD”则被分别存储在二级缓存和系统内存当中(如下图所示)。 需要注意的是,以上假设只是对AMD处理器一级数据缓存的一个抽象描述,一级数据缓存和二级缓存所能存储的数据长度完全由缓存容量的大小决定,而绝非以上假设中的几个字节。“实数据读写缓存”的优点是数据读取直接快速,但这也需要一级数据缓存具有一定的容量,增加了处理器的制造难度(一级数据缓存的单位制造成本较二级缓存高)。
二、Intel一级数据缓存设计 自P4时代开始,Intel开始采用全新的“数据代码指令追踪缓存”设计。基于这种架构的一级数据缓存不再存储实际的数据,而是存储这些数据在二级缓存中的指令代码(即数据在二级缓存中存储的起始地址)。假设处理器需要读取“INTEL P4 IS GOOD”这一串数据(不记空格),那么所有数据将被存储在二级缓存中,而一级数据代码指令追踪缓存需要存储的仅仅是上述数据的起始地址。
由于一级数据缓存不再存储实际数据,因此“数据代码指令追踪缓存”设计能够极大地降CPU对一级数据缓存容量的要求,降低处理器的生产难度。但这种设计的弊端在于数据读取效率较“实数据读写缓存设计”低,而且对二级缓存容量的依赖性非常大。 在了解了一级缓存、二级缓存的大致作用及其分类以后,下面我们来回答以下硬件一菜鸟网友提出的问题。
从理论上讲,二级缓存越大处理器的性能越好,但这并不是说二级缓存容量加倍就能够处理器带来成倍的性能增长。目前CPU处理的绝大部分数据的大小都在0-256KB之间,小部分数据的大小在256KB-512KB之间,只有极少数数据的大小超过512KB。所以只要处理器可用的一级、二级缓存容量达到256KB以上,那就能够应付正常的应用;512KB容量的二级缓存已经足够满足绝大多数应用的需求。 这其中,对于采用“实数据读写缓存”设计的AMD Athlon 64、Sempron处理器而言,由于它们已经具备了64KB一级指令缓存和64KB一级数据缓存,只要处理器的二级缓存容量大于等于128KB就能够存储足够的数据和指令,因此它们对二级缓存的依赖性并不大。这就是为什么主频同为1.8GHz的Socket 754 Sempron 3000+(128KB二级缓存)、Sempron 3100+(256KB二级缓存)以及Athlon 64 2800+(512KB二级缓存)在大多数评测中性能非常接近的主要原因。所以对于普通用户而言754 Sempron 2600+是值得考虑的。 反观Intel目前主推的P4、赛扬系列处理器,它们都采用了“数据代码指令追踪缓存”架构,其中Prescott内核的一级缓存中只包含了12KB一级指令缓存和16KB一级数据缓存,而Northwood内核更是只有12KB一级指令缓存和8KB一级数据缓存。
因此,P4、赛隆系列处理器非常依赖于二级缓存,赛扬D 320(256KB二级缓存)和赛扬2.4GHz(128kb二级缓存)的性能差距是很好的证明;Cayon D和P4E处理器之间的性能差距也非常明显。最后,如果你是一个狂热的游戏爱好者或者一个专业的多媒体用户,一个带有1MB二级缓存的P4处理器和一个512Kb/1MB二级缓存的Athon 64处理器是你的理想选择。由于CPU的主存和二级缓存在重计算负载下几乎是“满”的,大的二级缓存可以为处理器提供大约5%到10%的性能改进,这对于要求苛刻的用户是绝对必要的。一级缓存是在CPU内的,用来存放内部指令,2级缓存和CPU封装在一起,也是用来存放指令数据的,三级和四级缓存只在高端的服务器CPU里有,作用差不多,速度更快,更稳定,更有效 并不是缓存越大越好,譬如AMD和INTER就有不同的理论,AMD认为一级缓存越大越好,所以一级比较大,而INTER认为过大会有更长的指令执行时间,所以一级很小,二级缓存那两个公司的理论又反过来了,AMD的小,INTER的大,一般主流的INTERCPU的2级缓存都在2M左右 我们通常用(L1,L2)来称呼缓存又叫高速缓冲存储器其作用在于缓解主存速度慢、跟不上CPU读写速度要求的矛盾。它的实现原理,是把CPU最近最可能用到的少量信息(数据或指令)从主存复制到CACHE中,当CPU下次再用这些信息时,它就不必访问慢速的主存,而直接从快速的CACHE中得到,从而提高了得到这些信息的速度,使CPU有更高的运行效率。
总结
通过以上分析,我们可以得知Bean在一级缓存、二级缓存、三级缓存中的流转顺序为:三级缓存->二级缓存->一级缓存。但是并不是所有Bean都会经历这个过程,例如对于原型Bean(Prototype),IoC容器不会将其保存到任何一个缓存中的,另外即便是单例Bean(Singleton),如果没有循环引用关系,也不会被保存到二级缓存中的。
加载全部内容