TCP窗口填满问题排查
踩刀诗人 人气:0问题背景:
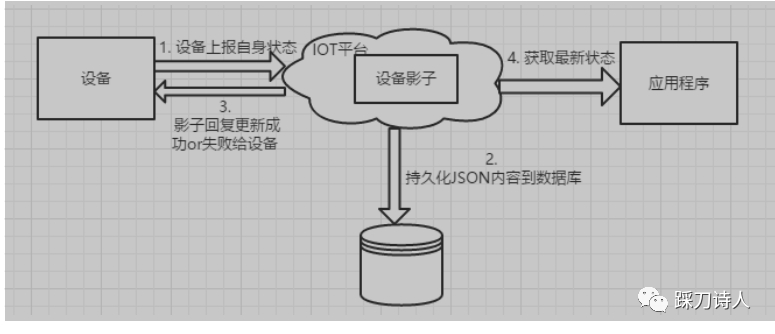
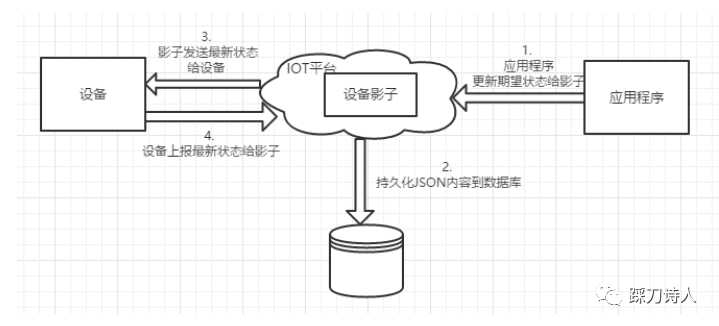
某日17:12左右,收到实施人员投诉,有部分设备不能正常升级、收不到控制台下发的指令等问题,同事查看control工程(后面简称control)那边的日志,发现control没有收到设备上报的影子信息,所以没有下发指令。control工程直接对接设备,根据设备上报的信息对设备下发一些指令及配置信息,包括升级、上报日志等,IoT平台上线之前control依赖心跳上报来获取设备的当前信息,IoT平台上线之后依赖设备影子信息来获取设备的当前信息,control会订阅设备的影子信息,但影子信息是由影子服务(简称IoT)转发过去的,它不直接对接设备影子上报,具体流转细节,
请看这下面两个图:
应用程序(control)获取设备状态
应用程序(control)下发设备指令
得知control收不到影子消息以后,我立马去rabbitmq的控制台查看是否有消息,
确定两个事:
1.设备是否上报了消息
2.rabbitmq是否正常
下面图1、图2是当时截取的rabbitmq控制台的两个图,从图1可以很清楚的确定设备是有消息上报的,但是有很多消息是unacked(说明已经投递给了消费者,只是消费者没有ack而已,理论上等待一段时间就能正常)的,具体是哪个队列堆积unacked的消息请看图2,“spacebridgeiot-shadow”正是我们用来接收设备上报的影子信息的队列,消息都被堆积到队列了所以没有转发到control也是合理的,观察了一段时间发现unacked的数量变成了0,但是total的总数确没有太大变化,给人的感觉像是unacked的消息重新回到了消息队列里等待投递,果然过了几分钟以后又发现有大量unacked的消息,过了几分钟以后这部分unacked的消息重新回到队列里,control那边依然没有收到消息,这时查看IoT那边的日志发现竟然没有影子消息进来,在rabbitmq的控制台查看“spacebridgeiot-shadow”这个队列下居然没有消费者了,如图3所示。
这时查看rabbitmq的日志确实有错误信息,如图4所示,rabbitmq主动关闭了连接。
图1:rabbitmq概览图
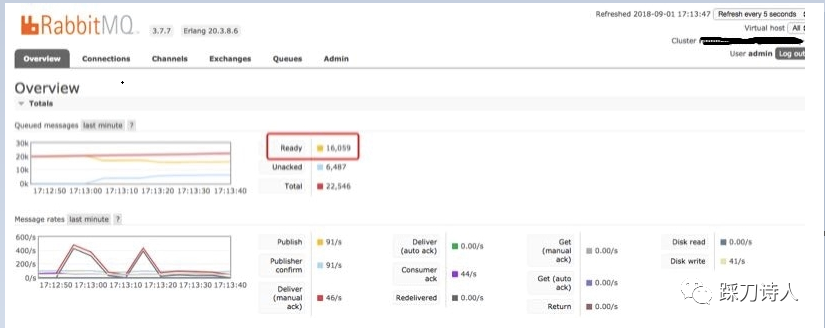
图2:rabbitmq队列统计图

图3:spacebridgeiot-shadow 概览
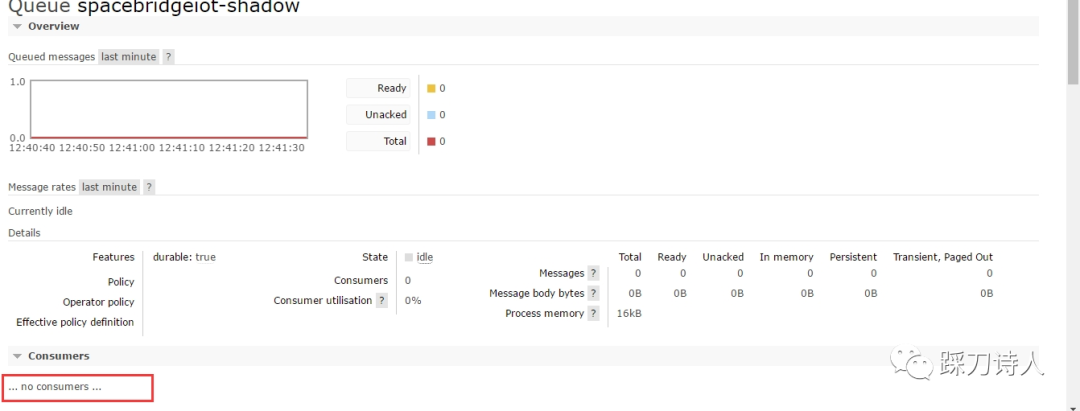
图4:rabbitmq报错信息

临时解决方案:
由于当时已经有大量投诉过来了,所以采用了比较暴力的解决办法“将堆积的消息删除”,删除以后果然正常了(备注:线上问题必须尽快解决,没有时间允许我们去分析日志然后有条不紊的解决,必须快)。
通过线下环境复现问题:
- 1.往10.200.41.166环境的rabbitmq的队列“mirrorTestQueue”堆积大量消息(起码万级)
- 2.停掉mirrorTestQueue的消费者,待堆积完成以后重新启动
- 3.堆积完成,重新启动消费者
和我们设想的一样,几秒内有几千条消息推给了消费者,持续几分钟以后rabbitmq主动关闭了和消费者之间的连接,这时从控制台看不到队列的消费者。
由于我们的消费者设置了自动恢复,所以过一阵又会自动连上,但很快又会被断连,和我们线上遇到的问题基本一样,究竟是什么导致了这个问题呢?说实话当时没有什么思路,网上找了一圈也没找到什么特别满意的答案(当时没有抓到问题的本质,搜的关键词太泛了),后来我们猜测可能是TCP层面出了什么问题,所以决定抓包试试能不能找到什么端倪。
果然,幸运的事情发生了,话不多说,直接上图。


13:06:25.643428之前rabbitmq还一直在给消费者推消息,直到13:06:25.643428这个时间点,开始出现消费者tcp窗口被打满的情况,大概持续了30秒左右,rabbitmq主动断开了连接(发了一个rst包),之后消费者重连,然后窗口又继续被打满,又持续30秒左右继续被断连。


感觉还挺有规律,每次持续30s,感觉是可配置的一个参数,大概总结一下就是“tcp full window导致了服务端主动rst连接,而且还有规律”
这次换了一下搜索的关键词找到了答案,rabbitmq有一个参数叫tcp_listen_options.send_timeout 是来控制写超时的一个参数,当写超时了以后就会触发tcp的RST(https://github.com/rabbitmq/rabbitmq-java-client/issues/341),修改一下试试效果如何:
1. 将写超时时间改成10s
tcp_listen_options.send_timeout = 10000
2.抓包看看是否起作用


可以看到从窗口满到关闭连接持续10s左右,说明这个参数是起作用的。
现象复盘:
由于rabbitmq的消费端没有设置prefetch所以rabbitmq一次性给消费端投递了过多的消息,从而导致消费端的 tcp 窗口被占满,进而触发了rabbitmq 的tcp_listen_options.send_timeout,这个写超时达到一个阈值后会触发rabbitmq断开消费者的tcp 连接。
终极解决方案:
之前删除消息只是迫不得已的方案,虽然解决了问题但太暴力,我们需要找到一个优雅的方案来应对,既然是推给消费者的消息太多造成了tcp窗口被打满,那我们就应该在接收速率上下点功夫,在连接rabbitmq的时候告诉它别给我发太多就行。
后面这段话摘自 https:
rabbitmq有一个属性叫prefetch
prefetch是指单一消费者最多能消费的unacked messages数目。
如何理解呢?mq为每一个 consumer设置一个缓冲区,大小就是prefetch。每次收到一条消息,MQ会把消息推送到缓存区中,然后再推送给客户端。当收到一个ack消息时(consumer 发出baseack指令),mq会从缓冲区中空出一个位置,然后加入新的消息。但是这时候如果缓冲区是满的,MQ将进入堵塞状态。更具体点描述,假设prefetch值设为10,共有两个consumer。也就是说每个consumer每次会从queue中预抓取 10 条消息到本地缓存着等待消费。同时该channel的unacked数变为20。而Rabbit投递的顺序是,先为consumer1投递满10个message,再往consumer2投递10个message。如果这时有新message需要投递,先判断channel的unacked数是否等于20,如果是则不会将消息投递到consumer中,message继续呆在queue中。之后其中consumer对一条消息进行ack,unacked此时等于19,Rabbit就判断哪个consumer的unacked少于10,就投递到哪个consumer中。
具体到代码里就是
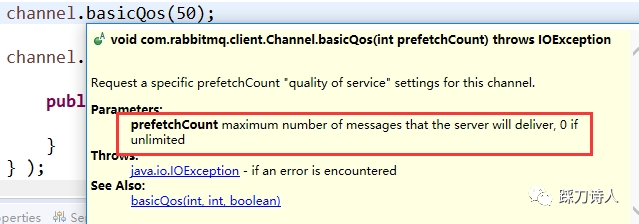
如何评估这个值呢,rabbitmq官方有个文章说的很好,就不细说了,我们的系统中目前设置的是20。
https://www.rabbitmq.com/blog/2012/05/11/some-queuing-theory-throughput-latency-and-bandwidth/
结束语:
对于关键组件的使用一定要熟悉其api,理解各个参数的含义和语法,当出现问题时不要局限于组件层面排查,必要的时候需要深入到底层,比如网络,操作系统等。
加载全部内容