MariaDB公用表表达式CTE
骏马金龙 人气:0前言
公用表表达式(Common Table Expression,CTE)和派生表类似,都是虚拟的表,但是相比于派生表,CTE具有一些优势和方便之处。
CTE有两种类型:非递归的CTE和递归CTE。
CTE是标准SQL的特性,属于表表达式的一种,MariaDB支持CTE,MySQL 8才开始支持CTE。
1.非递归CTE
CTE是使用WITH子句定义的,包括三个部分:CTE名称cte_name、定义CTE的查询语句inner_query_definition和引用CTE的外部查询语句outer_query_definition。
它的格式如下:
WITH cte_name1[(column_name_list)] AS (inner_query_definition_1) [,cte_name2[(column_name_list)] AS (inner_query_definition_2)] [,...] outer_query_definition
其中column_name_list指定inner_query_definition中的列列表名,如果不写该选项,则需要保证在inner_query_definition中的列都有名称且唯一,即对列名有两种命名方式:内部命名和外部命名。
注意,outer_quer_definition必须和CTE定义语句同时执行,因为CTE是临时虚拟表,只有立即引用它,它的定义才是有意义的。

下面语句是一个简单的CTE的用法。首先定义一张虚拟表,也就是CTE,然后在外部查询中引用它。
CREATE OR REPLACE TABLE t(id INT NOT NULL PRIMARY KEY,sex CHAR(3),NAME CHAR(20));
INSERT INTO t VALUES (1,'nan','David'),(2,'nv','Mariah'),(3,'nv','gaoxiaofang'),(4,'nan','Jim'),
(5,'nv','Selina'),(6,'nan','John'),(7,'nan','Monty'),(8,'nv','xiaofang');
# 定义CTE,顺便为每列重新命名,且使用ORDER BY子句
WITH nv_t(myid,mysex,myname) AS (
SELECT * FROM t WHERE sex='nv' ORDER BY id DESC
)
# 使用CTE
SELECT * FROM nv_t;
+------+-------+-------------+
| myid | mysex | myname |
+------+-------+-------------+
| 2 | nv | Mariah |
| 3 | nv | gaoxiaofang |
| 5 | nv | Selina |
| 8 | nv | xiaofang |
+------+-------+-------------+从结果中可以看到,在CTE的定义语句中使用ORDER BY子句是没有任何作用的。
在这里可以发现,CTE和派生表需要满足的几个共同点:每一列要求有列名,包括计算列;列名必须唯一;不能使用ORDER BY子句,除非使用了TOP关键字(标准SQL严格遵守不能使用ORDER BY的规则,但MySQL/MariaDB中允许)。不仅仅是CTE和派生表,其他表表达式(内联表值函数(sql server才支持)、视图)也都要满足这些条件。究其原因,表表达式的本质是表,尽管它们是虚拟表,也应该满足形成表的条件。
一方面,在关系模型中,表对应的是关系,表中的行对应的是关系模型中的元组,表中的字段(或列)对应的是关系中的属性。属性由三部分组成:属性的名称、属性的类型和属性值。因此要形成表,必须要保证属性的名称,即每一列都有名称,且唯一。
另一方面,关系模型是基于集合的,在集合中是不要求有序的,因此不能在形成表的时候让数据按序排列,即不能使用ORDER BY子句。之所以在使用了TOP后可以使用ORDER BY子句,是因为这个时候的ORDER BY只为TOP提供数据的逻辑提取服务,并不提供排序服务。例如使用ORDER BY帮助TOP选择出前10行,但是这10行数据在形成表的时候不保证是顺序的。
相比派生表,CTE有几个优点:
1.多次引用:避免重复书写。
2.多次定义:避免派生表的嵌套问题。
3.可以使用递归CTE,实现递归查询。
例如:
# 多次引用,避免重复书写
WITH nv_t(myid,mysex,myname) AS (
SELECT * FROM t WHERE sex='nv'
)
SELECT t1.*,t2.*
FROM nv_t t1 JOIN nv_t t2
WHERE t1.myid = t2.myid+1;
# 多次定义,避免派生表嵌套
WITH
nv_t1 AS ( /* 第一个CTE */
SELECT * FROM t WHERE sex='nv'
),
nv_t2 AS ( /* 第二个CTE */
SELECT * FROM nv_t1 WHERE id>3
)
SELECT * FROM nv_t2;如果上面的语句不使用CTE而使用派生表的方式,则它等价于:
SELECT * FROM (SELECT * FROM (SELECT * FROM t WHERE sex='nv') AS nv_t1) AS nv_t2;
2.递归CTE
SQL语言是结构化查询语言,它的递归特性非常差。使用递归CTE可稍微改善这一缺陷。
公用表表达式(CTE)具有一个重要的优点,那就是能够引用其自身,从而创建递归CTE。递归CTE是一个重复执行初始CTE以返回数据子集直到获取完整结果集的公用表表达式。
当某个查询引用递归CTE时,它即被称为递归查询。递归查询通常用于返回分层数据,例如:显示某个组织图中的雇员或物料清单方案(其中父级产品有一个或多个组件,而那些组件可能还有子组件,或者是其他父级产品的组件)中的数据。
递归CTE可以极大地简化在SELECT、INSERT、UPDATE、DELETE或CREATE VIEW语句中运行递归查询所需的代码。
也就是说,递归CTE通过引用自身来实现。它会不断地重复查询每一次递归得到的子集,直到得到最后的结果。这使得它非常适合处理"树状结构"的数据或者有"层次关系"的数据。
2.1 语法
递归cte中包含一个或多个定位点成员,一个或多个递归成员,最后一个定位点成员必须使用"union [all]"(mariadb中的递归CTE只支持union [all]集合算法)联合第一个递归成员。
以下是单个定位点成员、单个递归成员的递归CTE语法:
with recursive cte_name as (
select_statement_1 /* 该cte_body称为定位点成员 */
union [all]
cte_usage_statement /* 此处引用cte自身,称为递归成员 */
)
outer_definition_statement /* 对递归CTE的查询,称为递归查询 */其中:
select_statement_1:称为"定位点成员",这是递归cte中最先执行的部分,也是递归成员开始递归时的数据来源。
cte_usage_statement:称为"递归成员",该语句中必须引用cte自身。它是递归cte中真正开始递归的地方,它首先从定位点成员处获取递归数据来源,然后和其他数据集结合开始递归,每递归一次都将递归结果传递给下一个递归动作,不断重复地查询后,当最终查不出数据时才结束递归。
outer_definition_statement:是对递归cte的查询,这个查询称为"递归查询"。
2.2 递归CTE示例(1)
举个最经典的例子:族谱。
例如,下面是一张族谱表
CREATE OR REPLACE TABLE fork(id INT NOT NULL UNIQUE,NAME CHAR(20),father INT,mother INT);
INSERT INTO fork VALUES
(1,'chenyi',2,3),(2,'huagner',4,5),(3,'zhangsan',NULL,NULL),
(4,'lisi',6,7),(5,'wangwu',8,9),(6,'zhaoliu',NULL,NULL),(7,'sunqi',NULL,NULL),
(8,'songba',NULL,NULL),(9,'yangjiu',NULL,NULL);
MariaDB [test]> select * from fork;
+----+----------+--------+--------+
| id | name | father | mother |
+----+----------+--------+--------+
| 1 | chenyi | 2 | 3 |
| 2 | huagner | 4 | 5 |
| 3 | zhangsan | NULL | NULL |
| 4 | lisi | 6 | 7 |
| 5 | wangwu | 8 | 9 |
| 6 | zhaoliu | NULL | NULL |
| 7 | sunqi | NULL | NULL |
| 8 | songba | NULL | NULL |
| 9 | yangjiu | NULL | NULL |
+----+----------+--------+--------+该族谱表对应的结构图:

如果要找族谱中某人的父系,首先在定位点成员中获取要从谁开始找,例如上图中从"陈一"开始找。那么陈一这个记录就是第一个递归成员的数据源,将这个数据源联接族谱表,找到陈一的父亲黄二,该结果将通过union子句结合到上一个"陈一"中。再次对黄二递归,找到李四,再对李四递归找到赵六,对赵六递归后找不到下一个数据,所以这一分支的递归结束。
递归cte的语句如下:
WITH recursive fuxi AS (
SELECT * FROM fork WHERE `name`='chenyi'
UNION
SELECT f.* FROM fork f JOIN fuxi a WHERE f.id=a.father
)
SELECT * FROM fuxi;演变结果如下:
首先执行定位点部分的语句,得到定位点成员,即结果中的第一行结果集:

根据该定位点成员,开始执行递归语句:

递归时,按照f.id=a.father的条件进行筛选,得到id=2的结果,该结果通过union和之前的数据结合起来,作为下一次递归的数据源fuxi。
再进行第二次递归:

第三次递归:

由于第三次递归后,id=6的father值为null,因此第四次递归的结果为空,于是递归在第四次之后结束。
2.2 递归CTE示例(2)
该CTE示例主要目的是演示切换递归时的字段名称。
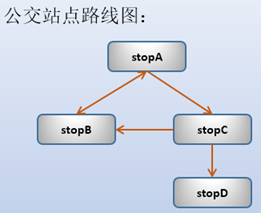
例如,有几个公交站点,它们之间的互通性如下图:

对应的表为:
CREATE OR REPLACE TABLE bus_routes (src char(50), dst char(50));
INSERT INTO bus_routes VALUES
('stopA','stopB'),('stopB','stopA'),('stopA','stopC'),('stopC','stopB'),('stopC','stopD');
MariaDB [test]> select * from bus_routes;
+-------+-------+
| src | dst |
+-------+-------+
| stopA | stopB |
| stopB | stopA |
| stopA | stopC |
| stopC | stopB |
| stopC | stopD |
+-------+-------+要计算以stopA作为起点,能到达哪些站点的递归CTE如下:
WITH recursive dst_stop AS (
SELECT src AS dst FROM bus_routes WHERE src='stopA' /* note: src as dst */
UNION
SELECT b.dst FROM bus_routes b
JOIN dst_stop d
WHERE d.dst=b.src
)
SELECT * FROM dst_stop;结果如下:
+-------+ | dst | +-------+ | stopA | | stopB | | stopC | | stopD | +-------+
首先执行定位点语句,得到定位点成员stopA,字段名为dst。
再将定位点成员结果和bus_routes表联接进行第一次递归,如下图:

再进行第二次递归:

再进行第三次递归,但第三次递归过程中,stopD找不到对应的记录,因此递归结束。
2.2 递归CTE示例(3)
仍然是公交路线图:
计算以stopA为起点,可以到达哪些站点,并给出路线图。例如:stopA-->stopC-->stopD。
以下是递归CTE语句:
WITH recursive bus_path(bus_path,bus_dst) AS (
SELECT src,src FROM bus_routes WHERE src='stopA'
UNION
SELECT CONCAT(b2.bus_path,'-->',b1.dst),b1.dst
FROM bus_routes b1
JOIN bus_path b2
WHERE b2.bus_dst = b1.src AND LOCATE(b1.dst,b2.bus_path)=0
)
SELECT * FROM bus_path;首先获取起点stopA,再获取它的目标stopB和stopC,并将起点到目标使用"-->"连接,即concat(src,"-->","dst")。再根据stopB和stopC,获取它们的目标。stopC的目标为stopD和stopB,stopB的目标为stopA。如果连接成功,那么路线为:
stopA-->stopB-->stopA 目标:stopA stopA-->stopC-->stopD 目标:stopD stopA-->stopC-->stopB 目标:stopB
这样会无限递归下去,因此我们要判断何时结束递归。判断的方法是目标不允许出现在路线中,只要出现,说明路线会重复计算。
总结
加载全部内容