MySQL 分页查询优化
Java后端何哥 人气:0前言:在数据库开发过程中我们经常会使用分页,核心技术是使用用limit start, count分页语句进行数据的读取。
一、MySQL分页起点越大查询速度越慢
直接用limit start, count分页语句,表示从第start条记录开始选择count条记录 :
select * from product limit start, count
当起始页较小时,查询没有性能问题,我们分别看下从10, 1000, 10000, 100000开始分页的执行时间(每页取20条)。
select * from product limit 10, 20 0.002秒 select * from product limit 1000, 20 0.011秒 select * from product limit 10000, 20 0.027秒 select * from product limit 100000, 20 0.057秒
我们已经看出随着起始记录的增加,时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为100w看下:
select * from product limit 1000000, 20 0.682秒
我们惊讶的发现MySQL在数据量大的情况下分页起点越大查询速度越慢,300万条起的查询速度已经需要1.368秒钟。这是为什么呢?因为limit 3000000,10的语法实际上是mysql扫描到前3000020条数据,之后丢弃前面的3000000行,这个步骤其实是浪费掉的。
select * from product limit 3000000, 20 1.368秒
从中我们也能总结出两件事情:
- limit语句的查询时间与起始记录的位置成正比
- mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
二、 limit大分页问题的性能优化方法
(1)利用表的覆盖索引来加速分页查询
MySQL的查询完全命中索引的时候,称为覆盖索引,是非常快的。因为查询只需要在索引上进行查找,之后可以直接返回,而不用再回表拿数据。在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何。
select id from product limit 1000000, 20 0.2秒
那么如果我们也要查询所有列,如何优化?
优化的关键是要做到让MySQL每次只扫描20条记录,我们可以使用limit n,这样性能就没有问题,因为MySQL只扫描n行。我们可以先通过子查询先获取起始记录的id,然后根据Id拿数据:
select * from vote_record where id>=(select id from vote_record limit 1000000,1) limit 20;
(2)用上次分页的最大id优化
先找到上次分页的最大ID,然后利用id上的索引来查询,类似于:
select * from user where id>1000000 limit 100
三、MySQL百万数据快速生成
利用mysql内存表插入速度快的特点,先利用函数和存储过程在内存表中生成数据,然后再从内存表插入普通表中
3.1、创建内存表及普通表
//内存表 CREATE TABLE `vote_record_memory` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `user_id` VARCHAR (20) NOT NULL, `vote_id` INT (11) NOT NULL, `group_id` INT (11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `index_id` (`user_id`) ) ENGINE = MEMORY AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8 //普通表 CREATE TABLE `vote_record` ( `id` INT (11) NOT NULL AUTO_INCREMENT, `user_id` VARCHAR (20) NOT NULL, `vote_id` INT (11) NOT NULL, `group_id` INT (11) NOT NULL, `create_time` datetime NOT NULL, PRIMARY KEY (`id`), KEY `index_user_id` (`user_id`) ) ENGINE = INNODB AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8
3.2、创建函数
//创建函数 CREATE FUNCTION `rand_string`(n INT) RETURNS varchar(255) CHARSET latin1 BEGIN DECLARE chars_str varchar(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789'; DECLARE return_str varchar(255) DEFAULT '' ; DECLARE i INT DEFAULT 0; WHILE i < n DO SET return_str = concat(return_str,substring(chars_str , FLOOR(1 + RAND()*62 ),1)); SET i = i +1; END WHILE; RETURN return_str; END
3.3、创建插入内存表数据的存储过程
#创建插入内存表数据存储过程,入参n是多少就插入多少条数据 CREATE PROCEDURE `add_vote_memory`(IN n int) BEGIN DECLARE i INT DEFAULT 1; WHILE (i <= n) DO INSERT into vote_record_memory (user_id,vote_id,group_id,create_time ) VALUEs (rand_string(20),FLOOR(RAND() * 1000),FLOOR(RAND() * 100) ,now() ); set i=i+1; END WHILE; END
3.4、创建内存表数据插入普通表的存储过程
此处利用对内存表的循环插入和删除来实现批量生成数据,这样可以不需要更改mysql默认的max_heap_table_size值也照样可以生成百万或者千万的数据。
- max_heap_table_size默认值是16M。
- max_heap_table_size的作用是配置用户创建内存临时表的大小,配置的值越大,能存进内存表的数据就越多。
#循环从内存表获取数据插入普通表 #参数描述 n表示循环调用几次;count表示每次插入内存表和普通表的数据量 CREATE PROCEDURE `add_vote_memory_to_common`(IN n int, IN count int) BEGIN DECLARE i INT DEFAULT 1; WHILE (i <= n) DO CALL add_vote_memory(count); INSERT INTO vote_record SELECT * FROM vote_record_memory; delete from vote_record_memory; SET i = i + 1; END WHILE; END
3.5、运行存储过程插入数据
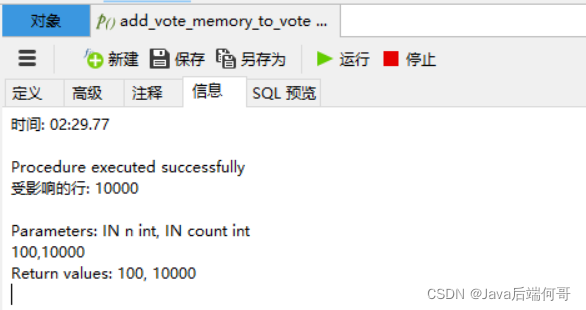
#循环调用100次,每次插入1W条数据 add_vote_memory_to_vote(100,10000);
插入一百万条数据,花了2分半钟:
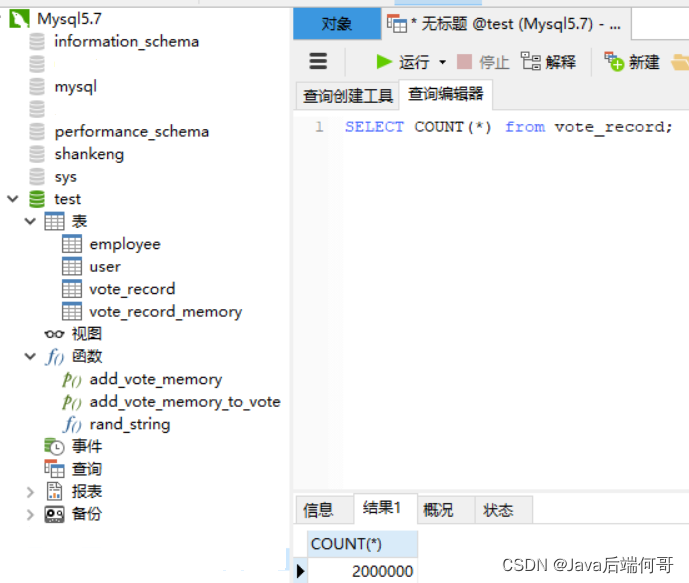
我执行了两次,查询vote_record表的行记录总数为两百万条:
参考链接:
加载全部内容