Java List集合介绍
偏偏爱吃梨 人气:01,Java集合介绍
作为一个程序猿,Java集合类可以说是我们在工作中运用最多、最频繁的类。相比于数组(Array)来说,集合类的长度可变,更加方便开发。
Java集合就像一个容器,可以存储任何类型的数据,也可以结合泛型来存储具体的类型对象。在程序运行时,Java集合可以动态的进行扩展,随着元素的增加而扩大。在Java中,集合类通常存在于java.util包中。
Java集合主要由2大体系构成,分别是Collection体系和Map体系,其中Collection和Map分别是2大体系中的顶层接口。
Collection主要有三个子接口,分别为List(列表)、Set(集)、Queue(队列)。其中,List、Queue中的元素有序可重复,而Set中的元素无序不可重复。
List中主要有ArrayList、LinkedList两个实现类;Set中则是有HashSet实现类;而Queue是在JDK1.5后才出现的新集合,主要以数组和链表两种形式存在。
Map同属于java.util包中,是集合的一部分,但与Collection是相互独立的,没有任何关系。Map中都是以key-value的形式存在,其中key必须唯一,主要有HashMap、HashTable、treeMap三个实现类。

2,List介绍
在Collection中,List集合是有序的,可对其中每个元素的插入位置进行精确地控制,可以通过索引来访问元素,遍历元素。
在List集合中,我们常用到ArrayList和LinkedList这两个类。
2.1 ArrayList集合
1,ArrayList底层通过数组实现,随着元素的增加而动态扩容。
2,ArrayList是Java集合框架中使用最多的一个类,是一个数组队列,线程不安全集合。
它继承于AbstractList,实现了List, RandomAccess, Cloneable, Serializable接口。
1,ArrayList实现List,得到了List集合框架基础功能;
2,ArrayList实现RandomAccess,获得了快速随机访问存储元素的功能,RandomAccess是一个标记接口,没有任何方法;
3,ArrayList实现Cloneable,得到了clone()方法,可以实现克隆功能;
4,ArrayList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
ArrayList集合的特点:
- 容量不固定,随着容量的增加而动态扩容(阈值基本不会达到)
- 有序集合(插入的顺序==输出的顺序)
- 插入的元素可以为null
- 增删改查效率更高(相对于LinkedList来说)
- 线程不安全
ArrayList的底层数据结构:

2.2 LinkedList集合
1,LinkedList底层通过链表来实现,随着元素的增加不断向链表的后端增加节点。
2,LinkedList是一个双向链表,每一个节点都拥有指向前后节点的引用。相比于ArrayList来说,LinkedList的随机访问效率更低。
它继承AbstractSequentialList,实现了List, Deque, Cloneable, Serializable接口。
1,LinkedList实现List,得到了List集合框架基础功能;
2,LinkedList实现Deque,Deque 是一个双向队列,也就是既可以先入先出,又可以先入后出,说简单点就是既可以在头部添加元素,也可以在尾部添加元素;
3,LinkedList实现Cloneable,得到了clone()方法,可以实现克隆功能;
4,LinkedList实现Serializable,表示可以被序列化,通过序列化去传输,典型的应用就是hessian协议。
LinkedList集合的底层数据结构:

3,List常用方法
A:添加功能 boolean add(E e):向集合中添加一个元素 void add(int index, E element):在指定位置添加元素 boolean addAll(Collection<? extends E> c):向集合中添加一个集合的元素。 B:删除功能 void clear():删除集合中的所有元素 E remove(int index):根据指定索引删除元素,并把删除的元素返回 boolean remove(Object o):从集合中删除指定的元素 boolean removeAll(Collection<?> c):从集合中删除一个指定的集合元素。 C:修改功能 E set(int index, E element):把指定索引位置的元素修改为指定的值,返回修改前的值。 D:获取功能 E get(int index):获取指定位置的元素 Iterator iterator():就是用来获取集合中每一个元素。 E:判断功能 boolean isEmpty():判断集合是否为空。 boolean contains(Object o):判断集合中是否存在指定的元素。 boolean containsAll(Collection<?> c):判断集合中是否存在指定的一个集合中的元素。 F:长度功能 int size():获取集合中的元素个数 G:把集合转换成数组 Object[] toArray():把集合变成数组。
3.1 ArrayList 基本操作
public class ArrayListTest {
public static void main(String[] agrs){
//创建ArrayList集合:
List<String> list = new ArrayList<String>();
System.out.println("ArrayList集合初始化容量:"+list.size());
// ArrayList集合初始化容量:0
//添加功能:
list.add("Hello");
list.add("world");
list.add(2,"!");
System.out.println("ArrayList当前容量:"+list.size());
// ArrayList当前容量:3
//修改功能:
list.set(0,"my");
list.set(1,"name");
System.out.println("ArrayList当前内容:"+list.toString());
// ArrayList当前内容:[my, name, !]
//获取功能:
String element = list.get(0);
System.out.println(element);
// my
//迭代器遍历集合:(ArrayList实际的跌倒器是Itr对象)
Iterator<String> iterator = list.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
/**
my
name
!
*/
//for循环迭代集合:
for(String str:list){
System.out.println(str);
}
/**
my
name
!
*/
//判断功能:
boolean isEmpty = list.isEmpty();
boolean isContain = list.contains("my");
//长度功能:
int size = list.size();
//把集合转换成数组:
String[] strArray = list.toArray(new String[]{});
//删除功能:
list.remove(0);
list.remove("world");
list.clear();
System.out.println("ArrayList当前容量:"+list.size());
// ArrayList当前容量:0
}
}
3.2 LinkedList 基本操作
public class LinkedListTest {
public static void main(String[] agrs){
List<String> linkedList = new LinkedList<String>();
System.out.println("LinkedList初始容量:"+linkedList.size());
// LinkedList初始容量:0
//添加功能:
linkedList.add("my");
linkedList.add("name");
linkedList.add("is");
linkedList.add("jiaboyan");
System.out.println("LinkedList当前容量:"+ linkedList.size());
// LinkedList当前容量:4
//修改功能:
linkedList.set(0,"hello");
linkedList.set(1,"world");
System.out.println("LinkedList当前内容:"+ linkedList.toString());
// LinkedList当前内容:[hello, world, is, jiaboyan]
//获取功能:
String element = linkedList.get(0);
System.out.println(element);
// hello
//遍历集合:(LinkedList实际的迭代器是ListItr对象)
Iterator<String> iterator = linkedList.iterator();
while(iterator.hasNext()){
String next = iterator.next();
System.out.println(next);
}
/**
hello
world
is
jiaboyan
*/
//for循环迭代集合:
for(String str:linkedList){
System.out.println(str);
}
/**
hello
world
is
jiaboyan
*/
//判断功能:
boolean isEmpty = linkedList.isEmpty();
boolean isContains = linkedList.contains("jiaboyan");
//长度功能:
int size = linkedList.size();
//删除功能:
linkedList.remove(0);
linkedList.remove("jiaboyan");
linkedList.clear();
System.out.println("LinkedList当前容量:" + linkedList.size());
// LinkedList当前容量:0
}
}
4,ArrayList和LinkedList比较
(1)元素新增性能比较
网上很多说的是,在做新增操作时,ArrayList的效率远不如LinkedList,因为Arraylist底层时数组实现的,在动态扩容时,性能会有所损耗,而LinkedList不存在数组扩容机制,所以LinkedList的新增性能较好。究竟时哪个好呢,我们用实践得到结果。
public class ListTest{
// 迭代次数
public static int ITERATION_NUM = 100000;
public static void main(String[] args) {
try{
insertPerformanceCompare();
}catch (Exception e){}
}
//新增性能比较:
public static void insertPerformanceCompare() throws InterruptedException {
Thread.sleep(5000);
System.out.println("LinkedList新增测试开始");
long start = System.nanoTime();
List<Integer> linkedList = new LinkedList<Integer>();
for (int x = 0; x < ITERATION_NUM; x++) {
linkedList.add(x);
}
long end = System.nanoTime();
System.out.println(end - start);
System.out.println("ArrayList新增测试开始");
start = System.nanoTime();
List<Integer> arrayList = new ArrayList<Integer>();
for (int x = 0; x < ITERATION_NUM; x++) {
arrayList.add(x);
}
end = System.nanoTime();
System.out.println(end - start);
}
}
测试结果:
第一次:
LinkedList新增测试开始
10873720
ArrayList新增测试开始
5535277
第二次:
LinkedList新增测试开始
13097503
ArrayList新增测试开始
6046139
第三次:
LinkedList新增测试开始
12004669
ArrayList新增测试开始
6509783
结果与预想的有些不太一样,ArrayList的新增性能并不低。
原因:
可能是经过JDK近几年的更新发展,对于数组复制的实现进行了优化,以至于ArrayList的性能也得到了提高。
(2)元素获取比较
由于LinkedList是链表结构,没有角标的概念,没有实现RandomAccess接口,不具备随机元素访问功能,所以在get方面表现的差强人意,ArrayList再一次完胜。
public class ListTest {
//迭代次数,集合大小:
public static int ITERATION_NUM = 100000;
public static void main(String[] agrs) {
try{
getPerformanceCompare();
}catch (Exception e){}
}
//获取性能比较:
public static void getPerformanceCompare()throws InterruptedException {
Thread.sleep(5000);
//填充ArrayList集合:
List<Integer> arrayList = new ArrayList<Integer>();
for (int x = 0; x < ITERATION_NUM; x++) {
arrayList.add(x);
}
//填充LinkedList集合:
List<Integer> linkedList = new LinkedList<Integer>();
for (int x = 0; x < ITERATION_NUM; x++) {
linkedList.add(x);
}
//创建随机数对象:
Random random = new Random();
System.out.println("LinkedList获取测试开始");
long start = System.nanoTime();
for (int x = 0; x < ITERATION_NUM; x++) {
int j = random.nextInt(x + 1);
int k = linkedList.get(j);
}
long end = System.nanoTime();
System.out.println(end - start);
System.out.println("ArrayList获取测试开始");
start = System.nanoTime();
for (int x = 0; x < ITERATION_NUM; x++) {
int j = random.nextInt(x + 1);
int k = arrayList.get(j);
}
end = System.nanoTime();
System.out.println(end - start);
}
}
测试结果:
第一次:
LinkedList获取测试开始
8190063123
ArrayList获取测试开始
8590205
第二次:
LinkedList获取测试开始
8100623160
ArrayList获取测试开始
11948919
第三次:
LinkedList获取测试开始
8237722833
ArrayList获取测试开始
6333427
从结果可以看出,ArrayList在随机访问方面表现的十分优秀,比LinkedList强了很多。
原因:
这主要是LinkedList的代码实现所致,每一次获取都是从头开始遍历,一个个节点去查找,每查找一次就遍历一次,所以性能自然得不到提升。
5,ArrayList源码分析
接下来,我们对ArrayList集合进行源码分析,其中先来几个问题:
(1)ArrayList的构造
(2)增删改查的实现
(3)迭代器——modCount
(4)为什么数组对象要使用transient修饰符
(5)System.arraycopy()参数含义 Arrays.copyOf()参数含义
我们通过上面几个问题,对ArrayList的源码进行一步一步的解析。
ArrayList构造器
1,在JDK1.7版本中,ArrayList的无参构造方法并没有生成容量为10的数组。
2,elementData对象是ArrayList集合底层保存元素的实现。
3,size属性记录了ArrayList集合中实际元素的个数。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
//实现Serializable接口,生成的序列版本号:
private static final long serialVersionUID = 8683452581122892189L;
//ArrayList初始容量大小:在无参构造中不使用了
private static final int DEFAULT_CAPACITY = 10;
//空数组对象:初始化中默认赋值给elementData
private static final Object[] EMPTY_ELEMENTDATA = {};
//ArrayList中实际存储元素的数组:
private transient Object[] elementData;
//集合实际存储元素长度:
private int size;
//ArrayList有参构造:容量大小
public ArrayList(int initialCapacity) {
//即父类构造:protected AbstractList() {}空方法
super();
//如果传递的初始容量小于0 ,抛出异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
//初始化数据:创建Object数组
this.elementData = new Object[initialCapacity];
}
//ArrayList无参构造:
public ArrayList() {
//即父类构造:protected AbstractList() {}空方法
super();
//初始化数组:空数组,容量为0
this.elementData = EMPTY_ELEMENTDATA;
}
//ArrayList有参构造:Java集合
public ArrayList(Collection<? extends E> c) {
//将集合转换为数组:
elementData = c.toArray();
//设置数组的长度:
size = elementData.length;
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
}
}
add() 添加
1,在JDK1.7当中,当第一个元素添加时,ensureCapacityInternal()方法会计算ArrayList的扩容大小,默认为10。
2,其中grow()方法最为重要,如果需要扩容,那么扩容后的大小是原来的1.5倍,实际上最终调用了Arrays.copyOf()方法得以实现。
//添加元素e
public boolean add(E e) {
ensureCapacityInternal(size + 1);
//将对应角标下的元素赋值为e:
elementData[size++] = e;
return true;
}
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
//如果此时ArrayList是空数组,则将最小扩容大小设置为10:
if (elementData == EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//判断是否需要扩容:
ensureExplicitCapacity(minCapacity);
}
//判断是否需要扩容
private void ensureExplicitCapacity(int minCapacity) {
//操作数+1
modCount++;
//判断最小扩容容量-数组大小是否大于0:
if (minCapacity - elementData.length > 0)
//扩容:
grow(minCapacity);
}
//ArrayList动态扩容的核心方法:
private void grow(int minCapacity) {
//获取现有数组大小:
int oldCapacity = elementData.length;
//位运算,得到新的数组容量大小,为原有的1.5倍:
int newCapacity = oldCapacity + (oldCapacity >> 1);
//如果新扩容的大小依旧小于传入的容量值,那么将传入的值设为新容器大小:
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果新容器大小,大于ArrayList最大长度:
if (newCapacity - MAX_ARRAY_SIZE > 0)
//计算出最大容量值:
newCapacity = hugeCapacity(minCapacity);
//数组复制:
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 计算ArrayList最大容量:
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0)
throw new OutOfMemoryError();
//如果新的容量大于MAX_ARRAY_SIZE。将会调用hugeCapacity将int的最大值赋给newCapacity:
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
remove() 删除
1,remove(int index)是针对于角标来进行删除,不需要去遍历整个集合,效率更高。
2,而remove(Object o)是针对于对象来进行删除,需要遍历整个集合进行equals()方法比对,所以效率较低。
3,不过,无论是哪种形式的删除,最终都会调用System.arraycopy()方法进行数组复制操作,所以效率都会受到影响。
//在ArrayList的移除index位置的元素
public E remove(int index) {
//检查角标是否合法:不合法抛异常
rangeCheck(index);
//操作数+1:
modCount++;
//获取当前角标的value:
E oldValue = elementData(index);
//获取需要删除元素 到最后一个元素的长度,也就是删除元素后,后续元素移动的个数;
int numMoved = size - index - 1;
//如果移动元素个数大于0 ,也就是说删除的不是最后一个元素:
if (numMoved > 0)
// 将elementData数组index+1位置开始拷贝到elementData从index开始的空间
System.arraycopy(elementData, index+1, elementData, index, numMoved);
//size减1,并将最后一个元素置为null
elementData[--size] = null;
//返回被删除的元素:
return oldValue;
}
//在ArrayList的移除对象为O的元素,不返回被删除的元素:
public boolean remove(Object o) {
//如果o==null,则遍历集合,判断哪个元素为null:
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
//快速删除,和前面的remove(index)一样的逻辑
fastRemove(index);
return true;
}
} else {
//同理:
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
//快速删除:
private void fastRemove(int index) {
//操作数+1
modCount++;
//获取需要删除元素 到最后一个元素的长度,也就是删除元素后,后续元素移动的个数;
int numMoved = size - index - 1;
//如果移动元素个数大于0 ,也就是说删除的不是最后一个元素:
if (numMoved > 0)
// 将elementData数组index+1位置开始拷贝到elementData从index开始的空间
System.arraycopy(elementData, index+1, elementData, index, numMoved);
//size减1,并将最后一个元素置为null
elementData[--size] = null;
}
set() 修改
由于ArrayList实现了RandomAccess,所以具备了随机访问特性,调用elementData()可以获取到对应元素的值。
//设置index位置的元素值了element,返回该位置的之前的值
public E set(int index, E element) {
//检查index是否合法:判断index是否大于size
rangeCheck(index);
//获取该index原来的元素:
E oldValue = elementData(index);
//替换成新的元素:
elementData[index] = element;
//返回旧的元素:
return oldValue;
}
get() 获取元素
通过elementData()方法获取对应角标元素,在返回时候进行类型转换。
//获取index位置的元素
public E get(int index) {
//检查index是否合法:
rangeCheck(index);
//获取元素:
return elementData(index);
}
//获取数组index位置的元素:返回时类型转换
E elementData(int index) {
return (E) elementData[index];
}
modCount含义
1,在Itr迭代器初始化时,将ArrayList的modCount属性的值赋值给了expectedModCount。
2,通过上面的例子中,我们可以知道当进行增删改时,modCount会随着每一次的操作而+1,modCount记录了ArrayList内发生改变的次数。
3,当迭代器在迭代时,会判断expectedModCount的值是否还与modCount的值保持一致,如果不一致则抛出异常。
AbstractList类当中定义的变量:
protected transient int modCount = 0;
ArrayList获取迭代器对象:
//返回一个Iterator对象,Itr为ArrayList的一个内部类,其实现了Iterator<E>接口
public Iterator<E> iterator() {
return new java.util.ArrayList.Itr();
}
迭代器实现:
//Itr实现了Iterator接口,是ArrayList集合的迭代器对象
private class Itr implements Iterator<E> {
//类似游标,指向迭代器下一个值的位置
int cursor;
//迭代器最后一次取出的元素的位置。
int lastRet = -1;
//Itr初始化时候ArrayList的modCount的值。
int expectedModCount = modCount;
//利用游标,与size之前的比较,判断迭代器是否还有下一个元素
public boolean hasNext() {
return cursor != size;
}
//迭代器获取下一个元素:
public E next() {
//检查modCount是否改变:
checkForComodification();
int i = cursor;
//游标不会大于等于集合的长度:
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = java.util.ArrayList.this.elementData;
//游标不会大于集合中数组的长度:
if (i >= elementData.length)
throw new ConcurrentModificationException();
//游标+1
cursor = i + 1;
//取出元素:
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
//检查modCount是否改变:防止并发操作集合
checkForComodification();
try {
//删除这个元素:
java.util.ArrayList.this.remove(lastRet);
//删除后,重置游标,和当前指向元素的角标 lastRet
cursor = lastRet;
lastRet = -1;
//重置expectedModCount:
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
//并发检查:
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
transient 修饰符
1,当我们序列化对象时,如果对象中某个属性不进行序列化操作,那么在该属性前添加transient修饰符即可实现。例如:
private transient Object[] elementData;
那么问题来了,为什么ArrayList不想对elementData属性进行序列化呢?elementData可是集合中保存元素的数组啊,如果不序列化elementData属性,那么在反序列化时候,岂不是丢失了原先的元素?
原因是 ArrayList在添加元素时,可能会对elementData数组进行扩容操作,而扩容后的数组可能并没有全部保存元素。
例如:我们创建了new Object[10]数组对象,但是我们只向其中添加了1个元素,而剩余的9个位置并没有添加元素。当我们进行序列化时,并不会只序列化其中一个元素,而是将整个数组进行序列化操作,那些没有被元素填充的位置也进行了序列化操作,间接的浪费了磁盘的空间,以及程序的性能。
所以,ArrayList才会在elementData属性前加上transient修饰符。
接下来,我们来看下ArrayList的writeObject()、readObject()
//序列化写入:
private void writeObject(java.io.ObjectOutputStream s) throws java.io.IOException{
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(size);
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
// 序列化读取:
private void readObject(java.io.ObjectInputStream s) throws java.io.IOException, ClassNotFoundException {
elementData = EMPTY_ELEMENTDATA;
s.defaultReadObject();
s.readInt();
if (size > 0) {
ensureCapacityInternal(size);
Object[] a = elementData;
for (int i=0; i<size; i++) {
a[i] = s.readObject();
}
}
}
1,ArrayList在序列化时会调用writeObject(),直接将elementData写入ObjectOutputStream。
2,反序列化时则调用readObject(),从ObjectInputStream获取elementData。
Arrays.copyOf() 数组扩容
该方法在内部创建了一个新数组,底层实现是调用System.arraycopy()。
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
original - 要复制的数组
newLength - 要返回的副本的长度
newType - 要返回的副本的类型
System.arraycopy()
该方法是用了native关键字,调用的为C++编写的底层函数。
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
src - 源数组。
srcPos - 源数组中的起始位置。
dest - 目标数组。
destPos - 目标数据中的起始位置。
length - 要复制的数组元素的数量。
6,LinkedList源码分析
看到网上都说LinkedList是一个环形链表结构,头尾相连。但,当我开始看源码的时候,发现并不是环形链表,是一个直线型链表结构,我一度以为是我理解有误。后来发现,JDK1.7之前的版本是环形链表,而到了JDK1.7以后进行了优化,变成了直线型链表结构。
集合基础结构
1,在LinkedList中,内部类Node对象最为重要,它组成了LinkedList集合的整个链表,分别指向上一个点、下一个结点,存储着集合中的元素。
2,成员变量中,first表明是头结点,last表明是尾结点。
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
//LinkedList的元素个数:
transient int size = 0;
//LinkedList的头结点:Node内部类
transient java.util.LinkedList.Node<E> first;
//LinkedList尾结点:Node内部类
transient java.util.LinkedList.Node<E> last;
//空实现:头尾结点均为null,链表不存在
public LinkedList() {
}
//调用添加方法:
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
//节点的数据结构,包含前后节点的引用和当前节点
private static class Node<E> {
//结点元素:
E item;
//结点后指针
java.util.LinkedList.Node<E> next;
//结点前指针
java.util.LinkedList.Node<E> prev;
Node(java.util.LinkedList.Node<E> prev, E element, java.util.LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
add() 添加
LinkedList的添加方法,主要分为2种,一是直接添加一个元素,二是在指定角标下添加一个元素。
(1)add(E e)底层调用linkLast(E e)方法,就是在链表的最后面插入一个元素。
(2)add(int index, E element),插入的角标如果==size,则插入到链表最后;否则,按照角标大小插入到对应位置。
//添加元素:添加到最后一个结点;
public boolean add(E e) {
linkLast(e);
return true;
}
//last节点插入新元素:
void linkLast(E e) {
//将尾结点赋值个体L:
final java.util.LinkedList.Node<E> l = last;
//创建新的结点,将新节点的前指针指向l:
final java.util.LinkedList.Node<E> newNode = new java.util.LinkedList.Node<>(l, e, null);
//新节点置为尾结点:
last = newNode;
//如果尾结点l为null:则是空集合新插入
if (l == null)
//头结点也置为 新节点:
first = newNode;
else
//l节点的后指针指向新节点:
l.next = newNode;
//长度+1
size++;
//操作数+1
modCount++;
}
//向对应角标添加元素:
public void add(int index, E element) {
//检查传入的角标 是否正确:
checkPositionIndex(index);
//如果插入角标==集合长度,则插入到集合的最后面:
if (index == size)
linkLast(element);
else
//插入到对应角标的位置:获取此角标下的元素先
linkBefore(element, node(index));
}
//在succ前插入 新元素e:
void linkBefore(E e, java.util.LinkedList.Node<E> succ) {
//获取被插入元素succ的前指针元素:
final java.util.LinkedList.Node<E> pred = succ.prev;
//创建新增元素节点,前指针 和 后指针分别指向对应元素:
final java.util.LinkedList.Node<E> newNode = new java.util.LinkedList.Node<>(pred, e, succ);
succ.prev = newNode;
//succ的前指针元素可能为null,为null的话说明succ是头结点,则把新建立的结点置为头结点:
if (pred == null)
first = newNode;
else
//succ前指针不为null,则将前指针的结点的后指针指向新节点:
pred.next = newNode;
//长度+1
size++;
//操作数+1
modCount++;
}
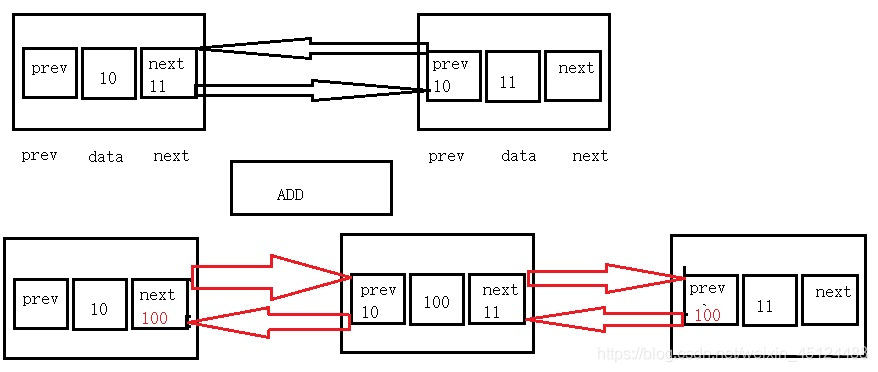
对于LinkedList集合增加元素来说,可以简单的概括为以下几点:
1,将添加的元素转换为LinkedList的Node对象节点。
2,增加该Node节点的前后引用,即该Node节点的prev、next属性,让其分别指向哪一个节点)。
3,修改该Node节点的前后Node节点中pre/next属性,使其指向该节点。
remove() 删除元素
LinkedList的删除也提供了2种形式,其一是通过角标删除元素,其二就是通过对象删除元素;不过,无论哪种删除,最终调用的都是unlink来实现的。
//删除对应角标的元素:
public E remove(int index) {
checkElementIndex(index);
//node()方法通过角标获取对应的元素,在后面介绍
return unlink(node(index));
}
//删除LinkedList中的元素,可以删除为null的元素,逐个遍历LinkedList的元素,重复元素只删除第一个:
public boolean remove(Object o) {
//如果删除元素为null:
if (o == null) {
for (java.util.LinkedList.Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
//如果删除元素不为null:
for (java.util.LinkedList.Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
//移除LinkedList结点:remove()方法中调用
E unlink(java.util.LinkedList.Node<E> x) {
//获取被删除结点的元素E:
final E element = x.item;
//获取被删除元素的后指针结点:
final java.util.LinkedList.Node<E> next = x.next;
//获取被删除元素的前指针结点:
final java.util.LinkedList.Node<E> prev = x.prev;
//被删除结点的 前结点为null的话:
if (prev == null) {
//将后指针指向的结点置为头结点
first = next;
} else {
//前置结点的 尾结点指向被删除的next结点;
prev.next = next;
//被删除结点前指针置为null:
x.prev = null;
}
//对尾结点同样处理:
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
set() 修改元素
1,LinkedList的set(int index, E element)方法与add(int index,E element)的设计思路基本一致,都是创建新Node节点,插入到对应的角标下,修改前后节点的prev、next属性。
2,其中,node(int index)方法至关重要,通过对应角标获取到对应的集合元素。
3,可以看到,node()中是根据角标的大小是选择从前遍历还是从后遍历整个集合。也可以间接的说明,LinkedList在随机获取元素时性能很低,每次的获取都得从头或者从尾遍历半个集合。
//设置对应角标的元素:
public E set(int index, E element) {
checkElementIndex(index);
//通过node()方法,获取到对应角标的元素:
java.util.LinkedList.Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
}
//获取对应角标所属于的结点:
java.util.LinkedList.Node<E> node(int index) {
//位运算:如果位置索引小于列表长度的一半,则从头开始遍历;否则,从后开始遍历;
if (index < (size >> 1)) {
java.util.LinkedList.Node<E> x = first;
//从头结点开始遍历:遍历的长度就是index的长度,获取对应的index的元素
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
//从集合尾结点遍历:
java.util.LinkedList.Node<E> x = last;
//同样道理:
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
get() 获取元素
get(int index)
在通过node(int index)获取到对应节点后,返回节点中的item属性,该属性就是我们所保存的元素。
//获取相应角标的元素:
public E get(int index) {
//检查角标是否正确:
checkElementIndex(index);
//获取角标所属结点的 元素值:
return node(index).item;
}
迭代器
在LinkedList中,并没有自己实现iterator()方法,而是使用其父类AbstractSequentialList的iterator()方法。
List<String> linkedList = new LinkedList<String>(); Iterator<String> iterator = linkedList.iterator();
父类AbstractSequentialList中的 iterator():
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
public Iterator<E> iterator() {
return listIterator();
}
}
父类AbstractList中的 listIterator():
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
public ListIterator<E> listIterator() {
return listIterator(0);
}
}
LinkedList中的 listIterator():
public ListIterator<E> listIterator(int index) {
checkPositionIndex(index);
return new ListItr(index);
}
private class ListItr implements ListIterator<E> {}
7,小结
加载全部内容