slf4j日志MDC输出格式
会灰翔的灰机 人气:18slf4j日志MDC输出格式
配置使用
// 自动配置模板
...
<Property name="layout">%d %p %X{traceId} [%t] %c{10}:%M:%L %m%n</Property>
...
<PatternLayout pattern="${layout}"/>
...
// 具体项目覆盖配置的格式
<Property name="layout">%d %p [%t] %c{1.}:%M:%L %X{myTraceId} %m%n</Property>
MDC.put("myTraceId", myTraceId);
try {
...
} catch (Exception e) {
...
} finally {
MDC.clear();
}
日志输出效果发现是直接打印了myTraceId所对应的的值,而我们期望是这样的格式{myTraceId=123}。
原因分析
查看格式化的实现类PatternLayout,内部通过PatternSelector匹配选择器根据Pattern匹配选择对应的转换器进行格式化
默认使用MarkerPatternSelector实现,选择器构造器中解析获取各个匹配模式对应的格式化实现列表PatternFormatter
PatternFormatter实现的实例属性LogEventPatternConverter抽象类对具体的日志内容进行格式化转换,查看其实现类
直接查看MdcPatternConverter实现
构造器中按照逗号“,”切分MDC的key配置
// options, 对应配置中的key列表
private MdcPatternConverter(final String[] options) {
super(options != null && options.length > 0 ? "MDC{" + options[0] + '}' : "MDC", "mdc");
if (options != null && options.length > 0) {
full = false;
if (options[0].indexOf(',') > 0) {
// 按照逗号切分key
keys = options[0].split(",");
for (int i = 0; i < keys.length; i++) {
keys[i] = keys[i].trim();
}
key = null;
} else {
keys = null;
key = options[0];
}
} else {
full = true;
key = null;
keys = null;
}
}
// 格式化
public void format(final LogEvent event, final StringBuilder toAppendTo) {
final ReadOnlyStringMap contextData = event.getContextData();
// if there is no additional options, we output every single
// Key/Value pair for the MDC in a similar format to Hashtable.toString()
// 如果没有附加的属性,我们输出每一个单独的MDC配置的key/value对,类似与Hashtable.toString()的格式
if (full) {
if (contextData == null || contextData.size() == 0) {
toAppendTo.append("{}");
return;
}
appendFully(contextData, toAppendTo);
} else {
if (keys != null) {
if (contextData == null || contextData.size() == 0) {
toAppendTo.append("{}");
return;
}
// 存在附加属性配置
appendSelectedKeys(keys, contextData, toAppendTo);
} else if (contextData != null){
// otherwise they just want a single key output
final Object value = contextData.getValue(key);
if (value != null) {
StringBuilders.appendValue(toAppendTo, value);
}
}
}
}
我们配置了%X扩展即存在附加属性配置
// 按照配置的MDC keys输出,输出格式为{key=value,key2=value2}
private static void appendSelectedKeys(final String[] keys, final ReadOnlyStringMap contextData, final StringBuilder sb) {
// Print all the keys in the array that have a value.
final int start = sb.length();
sb.append('{');
for (int i = 0; i < keys.length; i++) {
final String theKey = keys[i];
final Object value = contextData.getValue(theKey);
if (value != null) { // !contextData.containskey(theKey)
if (sb.length() - start > 1) {
sb.append(", ");
}
sb.append(theKey).append('=');
StringBuilders.appendValue(sb, value);
}
}
sb.append('}');
}
问题定位后修改配置即可,修改配置后验证格式符合我们的期望
<Property name="layout">%d %p [%t] %c{1.}:%M:%L %X{myTraceId,} %m%n</Property>
小结一下:MDC配置的key,日志会按照逗号切分出keys列表,如果keys列表小于等于1则直接输出一个单独的value值。如果大于1则按照map的格式输出,即:{key1=value1,key2=value2}
slf4j输出日志的语法
slf4j输出log的语法
1. 直接拼接字符串
用字符串拼接的构造方式输出log,字符串消息还是会被求值,存在类型转换和字符串连接的性能消耗。例:
int index = 1;
logger.info("这是第"+index+"条数据");
logger.info("这是第"+String.valueOf(index)+"条数据");
输出结果:

2. 使用SLF4J的格式化功能
这种用法不存在上面提到的缺点。SLF4J使用自己的格式化语法{},同时提供了适合不同参数个数的方法重载:
logger.debug(String format, Object param); //支持一个参数 logger.debug(String format, Object param1, Object param2); //支持两个参数 logger.debug(String format, Object… param); //任意数量参数,构造参数数组具有一定的性能损耗
例:
int index1=1;int index2=2;i
logger.info("这是第{}条数据",index1);
logger.info("这是第{}、{}条数据",index1,index2);
输出:
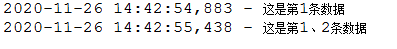
3. 格式化占位符的转义
连续的{}才被认为是格式化占位符
例:
logger.info("{1,2} 这是第{}条数据",index2);
logger.info("{1,2} 这是第{{}}条数据",index2);
输出:

用”\”转义{}占位符
例:
/**用”\”转义{}占位符*/
logger.info("\\{} 这是第{}条数据 ",index2);
/**用“\”本身转义“{}”中的”\”*/
logger.info("\\\\{} 这是第{}条数据 ",index3);
输出:

4. log前做条件判断
isDebugEnabled()的方法在debug disabled的情况下不存在构造字符串参数的性能消耗,但是如果debug enabled,debug是否被enabled将会被求值两次:
- 一次是isDebugEnabled(),
- 一次是debug()本身(该影响较小,因为求值logger状态花费的时间比真正log一条语句花费的时间的1%都还要小)。
例:
if(logger.isDebugEnabled()){
logger.info("这是第{}条数据 ",index2);
}
输出:
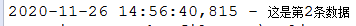
5、打印异常堆栈
logger.error("Failed to format {}", s, e);
slf4j总结
slf4j是Java的一种Log Api,类似Apache Commons Logging 。
官网介绍:http://www.slf4j.org/.
在SLF4J中,不需要进行字符串拼接,不会导致使用临时字符串带来的消耗。
相反,我们使用带占位符的模板消息来记录日志信息,并提供实际值作为参数。可以使用带参数版的日志方法,也可以通过Object数组传入。在为日志信息产生最终的字符串之前,该方法会检查是否开启了特定的日志级别,这不仅降低了内存占用,而且预先减少了执行字符串拼接所消耗的CPU时间。
log.debug("Found {} records matching filter: '{}'", records, filter);//slf4j
log.debug("Found " + records + " records matching filter: '" + filter + "'");//log4j
可以看出SLF4J的优点有:
更简略易读;
在日志级别不够时,少了字符串拼接的开销,不会调用对象(records/filter)的toString方法。通过使用日志记录方法,直到你使用到的时候,才会去构造日志信息(字符串),这就同时提高了内存和CPU的使用率。
Slf4j在1.6.0之后,更是支持了异常堆栈的打印,作为最后一个参数传入即可,基本满足了日志的常见打印场景。
在你的开源库或者私有库中使用SLF4J,可以使它独立于任何的日志实现,这就意味着不需要管理多个库和多个日志文件。
SLF4J提供了占位日志记录,通过移除对isDebugEnabled(), isInfoEnabled()等等的检查提高了代码的可读性。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容