Golang读取超长文本
CrazyDragon_King 人气:0前言:
最近在探索用Go来读取文件,读取文本时发现,对于单行超长的文本,我的Go代码无法处理。经过查阅才发现,Go提供的Scanner无法读取单行超长文本文件。我这里就来总结一下问题的发现和解决过程。
1.问题复现
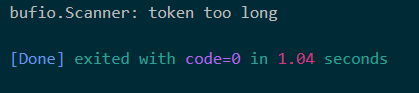
首先注释main函数里面的内容,执行 CreateBigText 函数,它会创建一个含有3行内容的文件,第一行是一个长度超过100KB的行。然后解决main函数的注释,尝试执行代码,会发现只有一行错误信息:
package main
import (
"bufio"
"bytes"
"log"
"os"
"strconv"
)
func main() {
file, err := os.Open("./read/test.txt")
if err != nil {
log.Fatal(err)
}
ReadBigText(file)
}
func ReadBigText(file *os.File) {
defer file.Close()
scanner := bufio.NewScanner(file)
for scanner.Scan() {
println(scanner.Text())
}
// 输出错误
println(scanner.Err().Error())
}
func CreateBigText() {
file, err := os.Create("./read/test.txt")
if err != nil {
log.Fatal(err)
}
defer file.Close()
data := make([]byte, 0, 32*1024)
buffer := bytes.NewBuffer(data)
// 构造一个大的单行数据
for i := 0; i < 50000; i++ {
buffer.WriteString(strconv.Itoa(i))
}
// 写入一个换行符
buffer.WriteByte('\n')
buffer.WriteString("I love you yesterday and today!\n")
buffer.WriteString("有一美人兮,见之不忘。\n")
// 将3行写入文件
file.Write(buffer.Bytes())
log.Println("创建文件成功")
}
2.问题探究
让我们来探究一下这个问题的原因,首先看一下Scan()方法的注释,这个方法就是每次扫描到下一个token,然后就可以通过获取字节或者文本的方法来获取扫描过的token。如果它返回值是false,就会返回扫描期间遇到的错误,除了io.EOF.
Scan advances the Scanner to the next token, which will then be available through the Bytes or Text method. It returns false when the scan stops, either by reaching the end of the input or an error. After Scan returns false, the Err method will return any error that occurred during scanning, except that if it was io.EOF, Err will return nil. Scan panics if the split function returns too many empty tokens without advancing the input. This is a common error mode for scanners.
所以Scan()和Text()函数是这样结合起来使用的,首先Scan()会扫描出一个token,然后Text()将其转成文本(或者其它方法转成字节),循环执行这种操作就可以按行读取一个文件。
通过阅读Scan()函数的源码,我们可以发现这样一个判断,如果buf的长度大于了最大token长度,那就会报错,见下图。
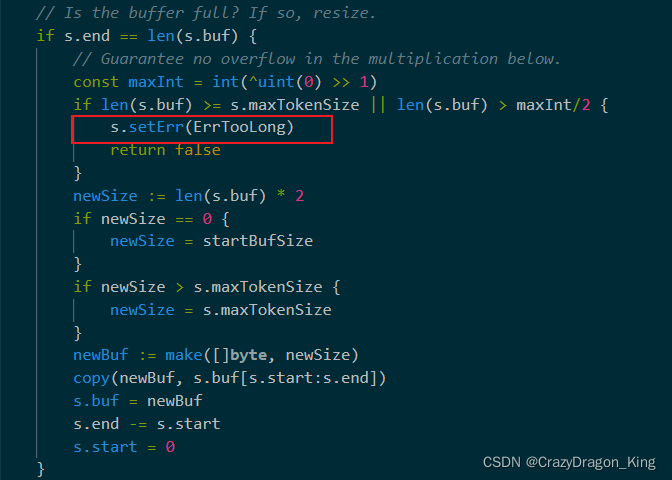
继续查找,可以看到最大长度已经定义好了,它的长度是 64*1024 byte,即64KB,所以一行文本超过了这个最大长度,那么就会报错!

3.问题解决
其实大部分情况下我们都应该使用Scan()函数结合Text()或者Bytes()函数来读取文件的,这个也是官方推荐的,因为它们是 high-level 方法,用起来很方便。但是如果我们有一些极端的情况,例如单行超过64KB,那么怎么办呢?(这种情况是很少的,但是又有可能会遇到这种需求的,例如文件里面存储了一串Base64编码)
这里可以这样来使用,这个方法不会受到64KB的限制,ReaderString方法会按照指定的定界符来读取一个完整的行,返回值是字符串和读取遇到的错误。如果想要读取返回值为字节的话,可以使用 ReadBytes 方法。
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err != nil {
log.Fatal(err)
}
fmt.Printf("%d %s", len(line), line)
}
}

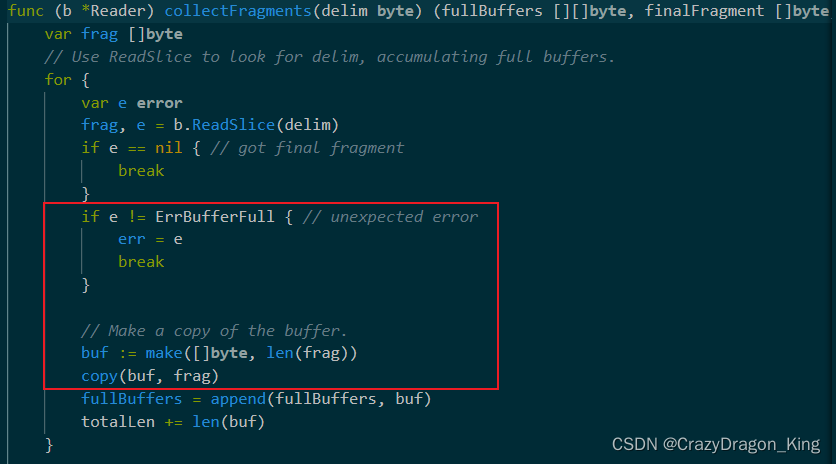
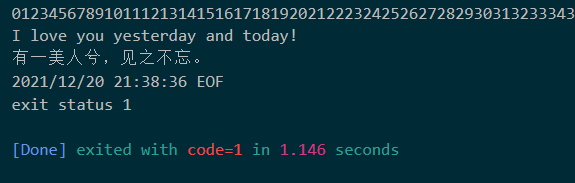
通过阅读源码可知,其实这个方法也是会遇到行太长的问题,只不过它忽略了这种情况。
ErrBufferFull就是这个缓冲区溢出错误。
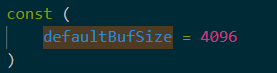
我们继续进入内容其实也可以知道,它默认的缓冲区大小是4KB。
4.扩展
上面都说相对高层的方法,我们来看一下相对底层的方法。
ReadLine is a low-level line-reading primitive. Most callers should use ReadBytes('\n') or ReadString('\n') instead or use a Scanner.
ReadLine是读取一行,但是它是一个 low-level 方法,它会返回三个值:[]byte、isPrefix bool和err error。
其中最令人好奇的是第二个参数,它如果是true,则表示当前行没有读取完毕,但是缓冲区满了,可以看下面这段注释。
If the line was too long for the buffer then isPrefix is set and the beginning of the line is returned. The rest of the line will be returned from future calls.
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
bline, isPrefix, err := reader.ReadLine()
if err == io.EOF {
break // 读取到文件结束才退出
}
// 读取到超长行,即单行超过4k字节,直接写入文件,不对此行做处理
if isPrefix {
fmt.Print(string(bline))
continue
}
fmt.Println(string(bline))
}
}
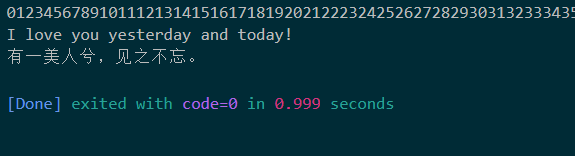
不过需要注意这个方法读取出来的数据是不包括换行符的,所以我是用的println打印输出的。
如果你也去看了 ReadString、ReadBytes 和 ReadLine 方法,会发现两种都依赖于一个底层的方法——ReadSlice方法。这个方法很原始,一般不会直接使用它。如果它遇到了超长行,它就会直接返回读取到的字节和一个ErrBufferFull,那这样我们就可以根据这个错误来继续读取数据了。这种方式还是相对麻烦了一些,不过如果你可以理解的话,对于上面的方法也就不是问题了。学习嘛,还是有必要一探究竟的。不过阅读源码感觉有些还是理解起来很困难,特别是这些英语注释,不过也能看一个七七八八了。还不行的话,那就再借助一些翻译软件,不过我个人觉得提高自己的英语能力还是非常必要的。
func ReadBigText(file *os.File) {
defer file.Close()
reader := bufio.NewReader(file)
for {
byt, err := reader.ReadSlice('\n')
if err != nil {
if err == bufio.ErrBufferFull {
fmt.Print(string(byt))
continue
}
log.Fatal(err)
}
fmt.Print(string(byt))
}
}
总结
加载全部内容