python操作RabbitMq的工作模式
Jeff的技术栈 人气:0一、简介:
RabbitMq 是实现了高级消息队列协议(AMQP)的开源消息代理中间件。消息队列是一种应用程序对应用程序的通行方式,应用程序通过写消息,将消息传递于队列,由另一应用程序读取 完成通信。而作为中间件的 RabbitMq 无疑是目前最流行的消息队列之一。
RabbitMq 应用场景广泛:
- 系统的高可用:日常生活当中各种商城秒杀,高流量,高并发的场景。当服务器接收到如此大量请求处理业务时,有宕机的风险。某些业务可能极其复杂,但这部分不是高时效性,不需要立即反馈给用户,我们可以将这部分处理请求抛给队列,让程序后置去处理,减轻服务器在高并发场景下的压力。
- 分布式系统,集成系统,子系统之间的对接,以及架构设计中常常需要考虑消息队列的应用。
二、RabbitMq 生产和消费
生产者(producter):队列消息的产生者,负责生产消息,并将消息传入队列
import pika
import json
credentials = pika.PlainCredentials('shampoo', '123456') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 声明消息队列,消息将在这个队列传递,如不存在,则创建
result = channel.queue_declare(queue = 'python-test')
for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 向队列插入数值 routing_key是队列名
channel.basic_publish(exchange = '',routing_key = 'python-test',body = message)
print(message)
connection.close()
消费者(consumer):队列消息的接收者,负责 接收并处理 消息队列中的消息
import pika
credentials = pika.PlainCredentials('shampoo', '123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel = connection.channel()
# 申明消息队列,消息在这个队列传递,如果不存在,则创建队列
channel.queue_declare(queue = 'python-test', durable = False)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
# 告诉rabbitmq,用callback来接收消息
channel.basic_consume('python-test',callback)
# 开始接收信息,并进入阻塞状态,队列里有信息才会调用callback进行处理
channel.start_consuming()
三、RabbitMq 持久化
MQ默认建立的是临时 queue 和 exchange,如果不声明持久化,一旦 rabbitmq 挂掉,queue、exchange 将会全部丢失。所以我们一般在创建 queue 或者 exchange 的时候会声明 持久化。
1.queue 声明持久化
# 声明消息队列,消息将在这个队列传递,如不存在,则创建。durable = True 代表消息队列持久化存储,False 非持久化存储 result = channel.queue_declare(queue = 'python-test',durable = True)
2.exchange 声明持久化
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建.durable = True 代表exchange持久化存储,False 非持久化存储 channel.exchange_declare(exchange = 'python-test', durable = True)
注意:如果已存在一个非持久化的 queue 或 exchange ,执行上述代码会报错,因为当前状态不能更改 queue 或 exchange 存储属性,需要删除重建。如果 queue 和 exchange 中一个声明了持久化,另一个没有声明持久化,则不允许绑定。
3.消息持久化
虽然 exchange 和 queue 都申明了持久化,但如果消息只存在内存里,rabbitmq 重启后,内存里的东西还是会丢失。所以必须声明消息也是持久化,从内存转存到硬盘。
# 向队列插入数值 routing_key是队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化
channel.basic_publish(exchange = '',routing_key = 'python-test',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
4.acknowledgement 消息不丢失
消费者(consumer)调用callback函数时,会存在处理消息失败的风险,如果处理失败,则消息丢失。但是也可以选择消费者处理失败时,将消息回退给 rabbitmq ,重新再被消费者消费,这个时候需要设置确认标识。
channel.basic_consume(callback,queue = 'python-test',
# no_ack 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
no_ack = False)
四、RabbitMq 发布与订阅
rabbitmq 的发布与订阅要借助交换机(Exchange)的原理实现:
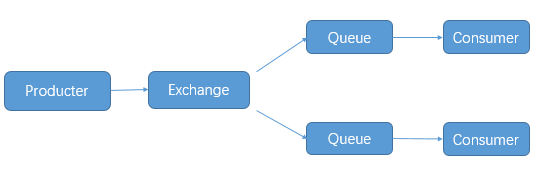
Exchange 一共有三种工作模式:fanout, direct, topicd
模式一:fanout
这种模式下,传递到 exchange 的消息将会转发到所有与其绑定的 queue 上。
- 不需要指定 routing_key ,即使指定了也是无效。
- 需要提前将 exchange 和 queue 绑定,一个 exchange 可以绑定多个 queue,一个queue可以绑定多个exchange。
- 需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。
发布者:
import pika
import json
credentials = pika.PlainCredentials('shampoo', '123456') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')
for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 向队列插入数值 routing_key是队列名。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化。routing_key 不需要配置
channel.basic_publish(exchange = 'python-test',routing_key = '',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
print(message)
connection.close()
订阅者:
import pika
credentials = pika.PlainCredentials('shampoo', '123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel = connection.channel()
# 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='fanout')
# 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去
channel.queue_bind(exchange = 'python-test',queue = result.method.queue)
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
channel.basic_consume(result.method.queue,callback,# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
auto_ack = False)
channel.start_consuming()
模式二:direct
这种工作模式的原理是 消息发送至 exchange,exchange 根据 路由键(routing_key)转发到相对应的 queue 上。
- 可以使用默认 exchange =' ' ,也可以自定义 exchange
- 这种模式下不需要将 exchange 和 任何进行绑定,当然绑定也是可以的。可以将 exchange 和 queue ,routing_key 和 queue 进行绑定
- 传递或接受消息时 需要 指定 routing_key
- 需要先启动 订阅者,此模式下的队列是 consumer 随机生成的,发布者 仅仅发布消息到 exchange ,由 exchange 转发消息至 queue。
发布者:
import pika
import json
credentials = pika.PlainCredentials('shampoo', '123456') # mq用户名和密码
# 虚拟队列需要指定参数 virtual_host,如果是默认的可以不填。
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel=connection.channel()
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct')
for i in range(10):
message=json.dumps({'OrderId':"1000%s"%i})
# 指定 routing_key。delivery_mode = 2 声明消息在队列中持久化,delivery_mod = 1 消息非持久化
channel.basic_publish(exchange = 'python-test',routing_key = 'OrderId',body = message,
properties=pika.BasicProperties(delivery_mode = 2))
print(message)
connection.close()
消费者:
import pika
credentials = pika.PlainCredentials('shampoo', '123456')
connection = pika.BlockingConnection(pika.ConnectionParameters(host = '10.1.62.170',port = 5672,virtual_host = '/',credentials = credentials))
channel = connection.channel()
# 创建临时队列,队列名传空字符,consumer关闭后,队列自动删除
result = channel.queue_declare('',exclusive=True)
# 声明exchange,由exchange指定消息在哪个队列传递,如不存在,则创建。durable = True 代表exchange持久化存储,False 非持久化存储
channel.exchange_declare(exchange = 'python-test',durable = True, exchange_type='direct')
# 绑定exchange和队列 exchange 使我们能够确切地指定消息应该到哪个队列去
channel.queue_bind(exchange = 'python-test',queue = result.method.queue,routing_key='OrderId')
# 定义一个回调函数来处理消息队列中的消息,这里是打印出来
def callback(ch, method, properties, body):
ch.basic_ack(delivery_tag = method.delivery_tag)
print(body.decode())
#channel.basic_qos(prefetch_count=1)
# 告诉rabbitmq,用callback来接受消息
channel.basic_consume(result.method.queue,callback,
# 设置成 False,在调用callback函数时,未收到确认标识,消息会重回队列。True,无论调用callback成功与否,消息都被消费掉
auto_ack = False)
channel.start_consuming()
模式三:topicd
这种模式和第二种模式差不多,exchange 也是通过 路由键 routing_key 来转发消息到指定的 queue 。 不同点是 routing_key 使用正则表达式支持模糊匹配,但匹配规则又与常规的正则表达式不同,比如“#”是匹配全部,“*”是匹配一个词。
举例:routing_key =“#orderid#”,意思是将消息转发至所有 routing_key 包含 “orderid” 字符的队列中。代码和模式二 类似,就不贴出来了。
加载全部内容