DataFrame stack()、unstack()和pivot()
侯小啾 人气:01.stack()
stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦:
准备一组数据,给其设置双索引。
import pandas as pd
data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324],
['B类', 'b1', 112, 412, 466], ['B类', 'b2', 224, 235, 345], ['B类', 'b3', 369, 214, 352],
['C类', 'c1', 236, 251, 485], ['C类', 'c2', 378, 216, 515], ['C类', 'c3', 135, 421, 312],
['D类', 'd1', 306, 325, 496], ['D类', 'd2', 147, 235, 524], ['D类', 'd3', 520, 222, 267]]
df = pd.DataFrame(data=data, columns=['类别', '编号', 'A指标', 'B指标', 'C指标'])
df = df.set_index(['类别', '编号'])
print(df)
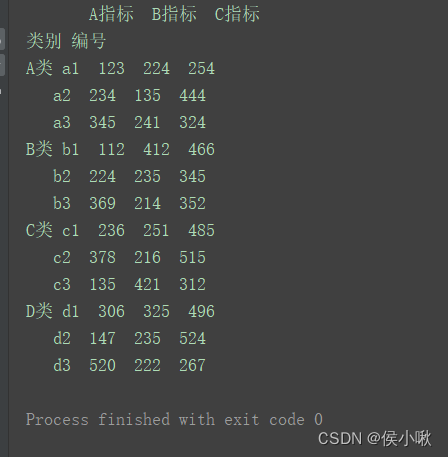
df = df.stack() print(df)
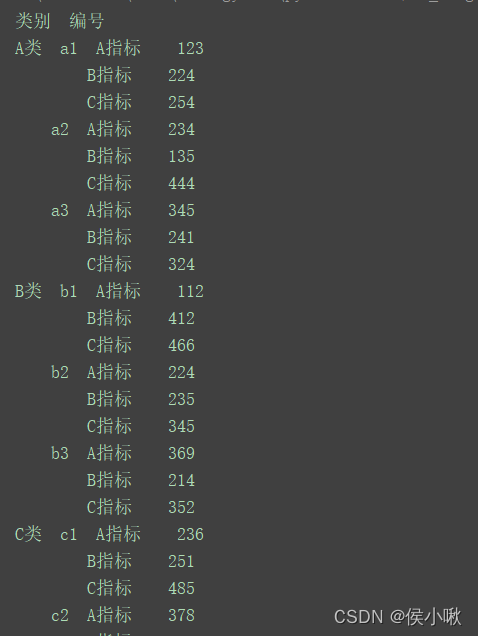
如图,成功将索引列之外的 A指标,B指标,C指标三列放在了同一列。
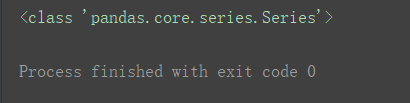
此时的df,不再是一个DataFrame,而变为了一个Series对象。:
print(type(df))
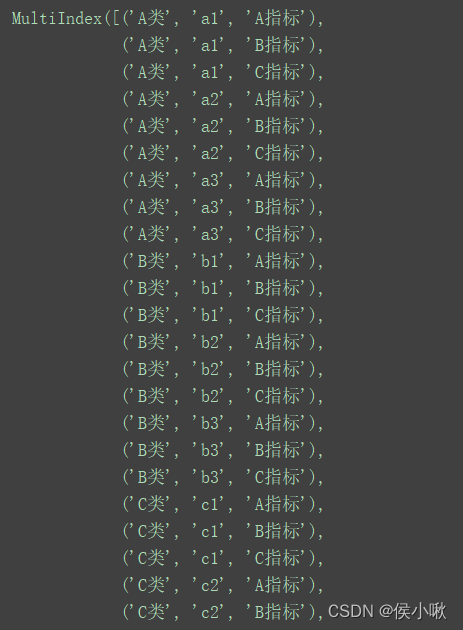
该Series的index列不同于原DataFrame的index列,而是在原DataFrame的index列的基础上,又增加了从右边合并过来的部分:
print(df.index)
此时Values为:
print(df.values)
2. unstack()
unstack是stack的逆向操作。
在上述示例的代码的基础上,对上边的df继续调用unstack()方法:
df1 = df.unstack() print(df1)
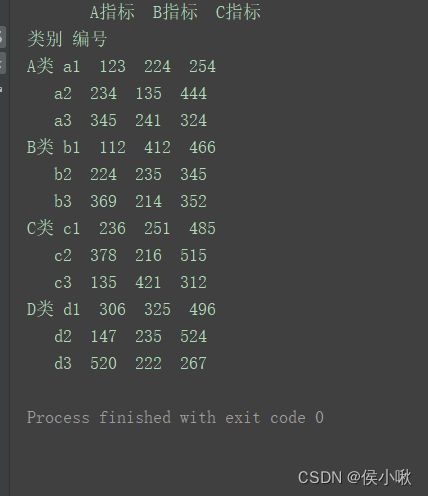
可以看到unstack变回了原来的样子。
3. pivot()
这里对于上边例子中的数据稍作调整:
不设置多重索引
import pandas as pd
data = [['A类', '1', 123, 224, 254], ['A类', '2', 234, 135, 444], ['A类', '3', 345, 241, 324],
['B类', '1', 112, 412, 466], ['B类', '2', 224, 235, 345], ['B类', '3', 369, 214, 352],
['C类', '1', 236, 251, 485], ['C类', '2', 378, 216, 515], ['C类', '3', 135, 421, 312],
['D类', '1', 306, 325, 496], ['D类', '2', 147, 235, 524], ['D类', '3', 520, 222, 267]]
df = pd.DataFrame(data=data, columns=['类别', '编号', 'A指标', 'B指标', 'C指标'])
print(df)

df2 = df.pivot(index='编号', columns='类别', values='A指标') print(df2)

index和columns分别指设定那一列的值为index,设置那一列的值为columns。values指表格要体现的指标。
df3 = df.pivot(index='类别', columns='编号', values='A指标') print(df3)

总结
加载全部内容