MyBatis 注册及获取Mapper
Integer_Double 人气:0一、搭建环境
1.1 pom.xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
</dependency>
1.2 BlogMapper.java
public interface BlogMapper {
List<Blog> selectBlog(String id);
}
1.3 BlogMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mybatis.source.study.BlogMapper">
<select id="selectBlog" resultType="mybatis.source.study.Blog">
select * from t_blog where id= #{id}
</select>
</mapper>
BlogMapper.xml放在resource目录下与BlogMapper.java包路径相同的路径下
1.4 MyBatisDemo.java
public class MyBatisDemo {
public static void main(String[] args) {
//创建数据源
DataSource dataSource = getDataSource();
TransactionFactory transactionFactory = new JdbcTransactionFactory();
//创建sql运行环境
Environment environment = new Environment("development", transactionFactory, dataSource);
//创建mybatis的所有配置
Configuration configuration = new Configuration(environment);
//注册mapper
configuration.addMapper(BlogMapper.class);
// configuration.addInterceptor(new PaginationInterceptor());
//根据配置创建sql会话工厂
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(configuration);
SqlSession sqlSession = sqlSessionFactory.openSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
System.out.println(mapper.selectBlog("001"));
}
private static DataSource getDataSource() {
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUrl("jdbc:mysql://localhost:3306/demo?characterEncoding=utf-8&serverTimezone=Asia/Shanghai");
druidDataSource.setUsername("root");
druidDataSource.setPassword("root");
return druidDataSource;
}
二、addMapper详细分析
2.1 MapperRegistry
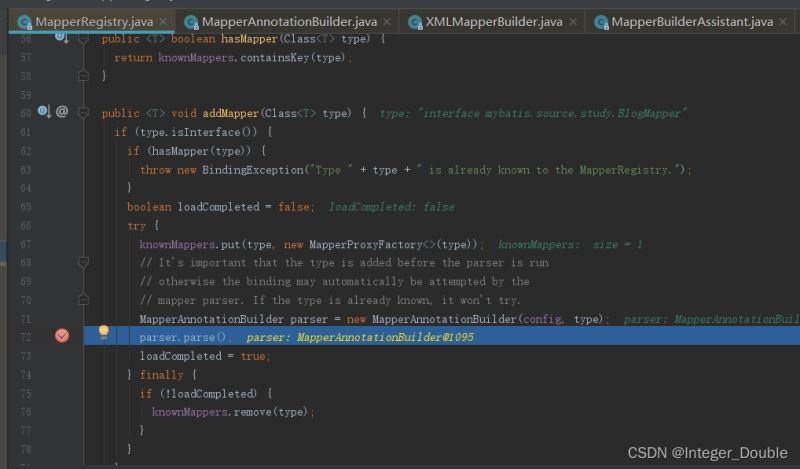
这块就是判断这个mapper.xml解析过没有,解析是在 parser.parse();中做的,来看
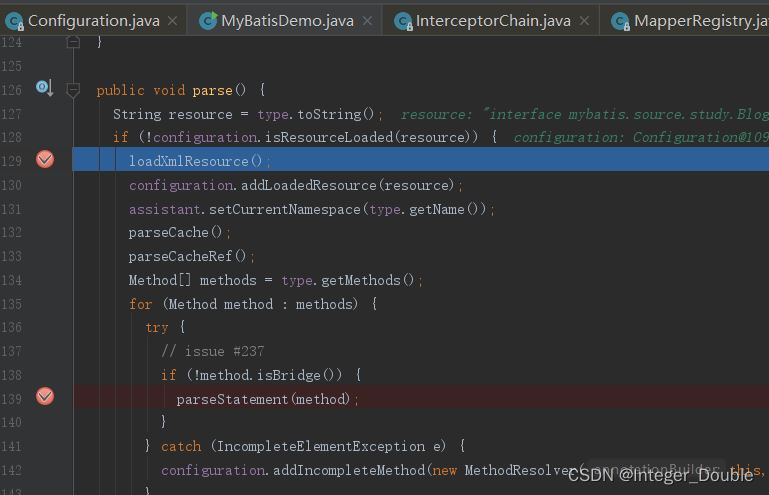
loadXmlResource();根据xml解析每个mapper接口的方法,将得到的MapperStatement放进了configuration,然后记录该xml的namespace表示已经处理过。具体调用链:
loadXmlResource()–>xmlParser.parse()–>configurationElement(parser.evalNode("/mapper"))–> buildStatementFromContext(context.evalNodes(“select|insert|update|delete”))–> buildStatementFromContext(list, null)–>statementParser.parseStatementNode()–>builderAssistant.addMappedStatement–>configuration.addMappedStatement(statement);
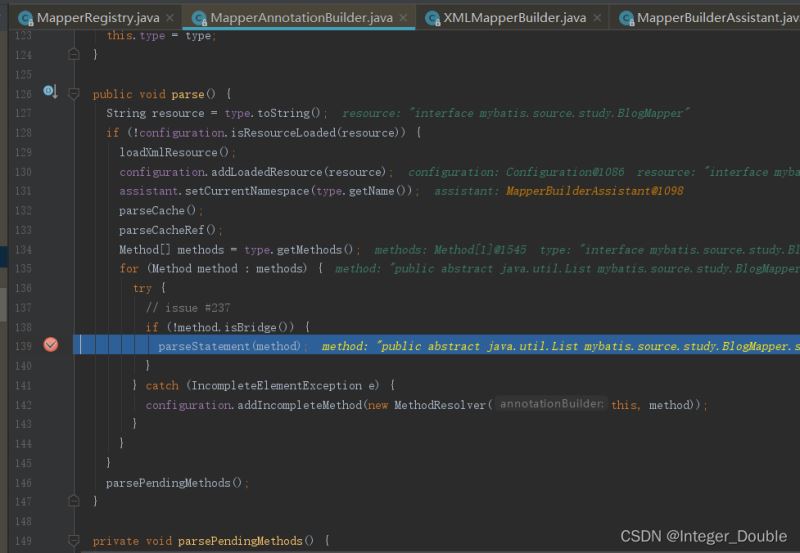
parseStatement(method);根据注解解析每个mapper接口的方法,因此xml和注解可以同时使用。但是同一个方法两者同时使用会报错
2.2 MapperProxyFactory
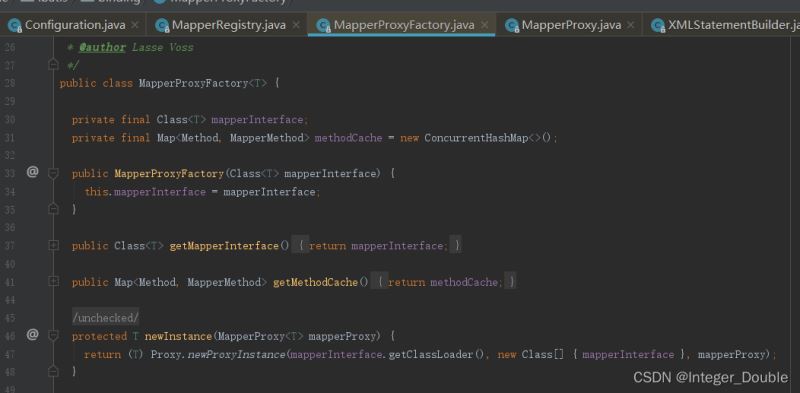
放入knownMappers的是MapperProxyFactory,它是一个Mapper代理的工厂,这个工厂提供newInstance方法,产生一个代理类(也就是BlogMapper接口的代理实现类),调用BlogMapper所有的方法将在MapperProxy的invoke方法中执行
三、getMapper详细分析
getMapper会调用MapperRegistry的getMapper从knownMappers中获取代理工厂,再调用newInstance方法产生一个代理类MapperProxy。
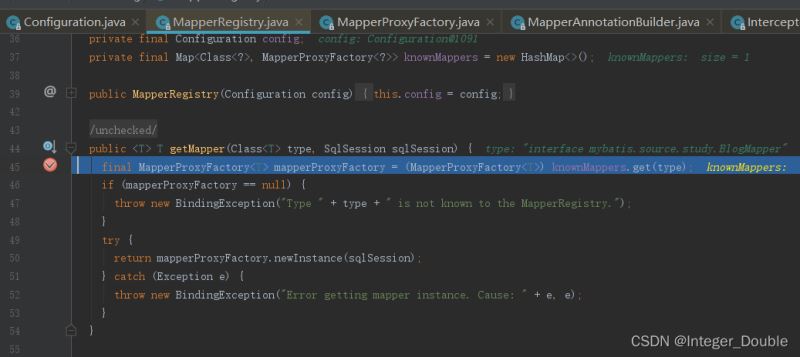
3.1 MapperProxy
在执行mapper.selectBlog(“001”)时,就会调用MapperProxy的invoke方法
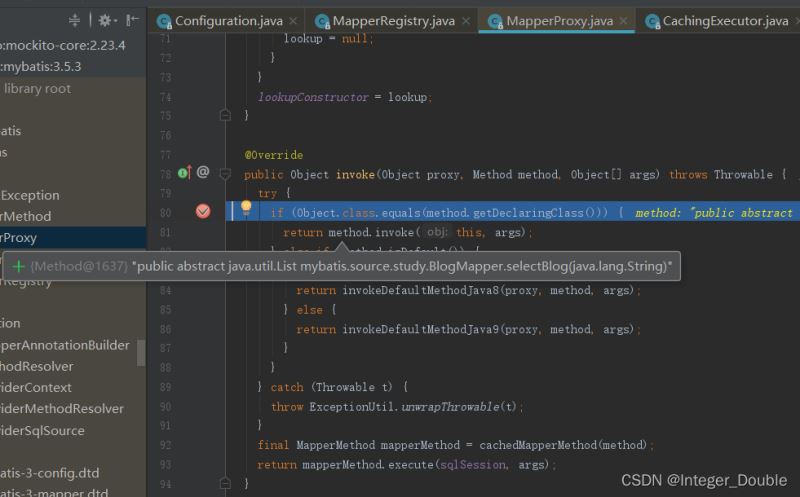
根据method(selectBlog)生成对应的MapperMethod,并将MapperMethod放入本地缓存。
mapperMethod.execute(sqlSession, args);执行真正的sql逻辑。
3.2 MapperMethod
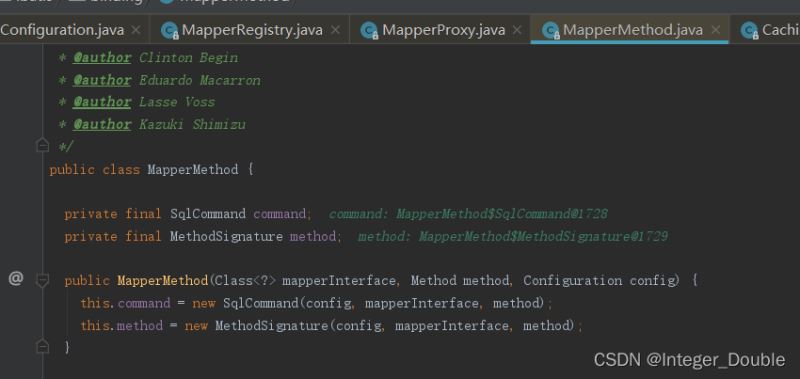
MapperMethod的构造方法,根据接口信息、方法信息、配置信息得到SqlCommand(sql名称、类型)、method(方法签名),方便后续执行命令、处理结果集等。
加载全部内容