PyTorch torch.nn.functional.cosine_similarity使用
JasonLiu1919 人气:0概述
根据官网文档的描述,其中 dim表示沿着对应的维度计算余弦相似。那么怎么理解呢?
首先,先介绍下所谓的dim:
a = torch.tensor([[ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ], dtype=torch.float)
print(a.shape)
"""
[
[
[1, 2],
[3, 4]
],
[
[5, 6],
[7, 8]
]
]
"""
假设有2个矩阵:[[1, 2], [3, 4]] 和 [[5, 6], [7, 8]], 求2者的余弦相似。
按照dim=0求余弦相似:
import torch.nn.functional as F input1 = torch.tensor([[1, 2], [3, 4]], dtype=torch.float) input2 = torch.tensor([[5, 6], [7, 8]], dtype=torch.float) output = F.cosine_similarity(input1, input2, dim=0) print(output)
结果如下:
tensor([0.9558, 0.9839])
那么,这个数值是怎么得来的?是按照
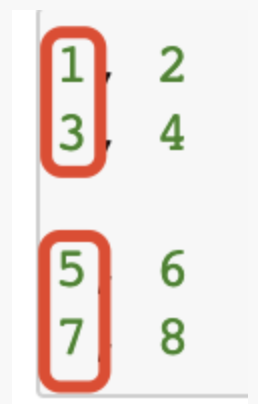
具体求解如下:
print(F.cosine_similarity(torch.tensor([1,3], dtype=torch.float) , torch.tensor([5,7], dtype=torch.float), dim=0)) print(F.cosine_similarity(torch.tensor([2,4], dtype=torch.float) , torch.tensor([6,8], dtype=torch.float), dim=0))
运行结果如下:
tensor(0.9558)tensor(0.9839)
可以用scipy.spatial进一步佐证:
from scipy import spatial dataSetI = [1,3] dataSetII = [5,7] result = 1 - spatial.distance.cosine(dataSetI, dataSetII) print(result)
运行结果如下:
0.95577900872195
同理:
dataSetI = [2,4] dataSetII = [6,8] result = 1 - spatial.distance.cosine(dataSetI, dataSetII) print(result)
运行结果如下:
0.9838699100999074
按照dim=1求余弦相似:
output = F.cosine_similarity(input1, input2, dim=1) print(output)
运行结果如下:
tensor([0.9734, 0.9972])
同理,用用scipy.spatial进一步佐证:
dataSetI = [1,2] dataSetII = [5,6] result = 1 - spatial.distance.cosine(dataSetI, dataSetII) print(result)
运行结果:0.973417168333576
dataSetI = [3,4] dataSetII = [7,8] result = 1 - spatial.distance.cosine(dataSetI, dataSetII) print(result)
运行结果:
0.9971641204866132
结果与F.cosine_similarity相符合。
补充:给定一个张量,计算多个张量与它的余弦相似度,并将计算得到的余弦相似度标准化。
import torch
def get_att_dis(target, behaviored):
attention_distribution = []
for i in range(behaviored.size(0)):
attention_score = torch.cosine_similarity(target, behaviored[i].view(1, -1)) # 计算每一个元素与给定元素的余弦相似度
attention_distribution.append(attention_score)
attention_distribution = torch.Tensor(attention_distribution)
return attention_distribution / torch.sum(attention_distribution, 0) # 标准化
a = torch.FloatTensor(torch.rand(1, 10))
print('a', a)
b = torch.FloatTensor(torch.rand(3, 10))
print('b', b)
similarity = get_att_dis(target=a, behaviored=b)
print('similarity', similarity)a tensor([[0.9255, 0.2194, 0.8370, 0.5346, 0.5152, 0.4645, 0.4926, 0.9882, 0.2783,
0.9258]])
b tensor([[0.6874, 0.4054, 0.5739, 0.8017, 0.9861, 0.0154, 0.8513, 0.8427, 0.6669,
0.0694],
[0.1720, 0.6793, 0.7764, 0.4583, 0.8167, 0.2718, 0.9686, 0.9301, 0.2421,
0.0811],
[0.2336, 0.4783, 0.5576, 0.6518, 0.9943, 0.6766, 0.0044, 0.7935, 0.2098,
0.0719]])
similarity tensor([0.3448, 0.3318, 0.3234])
总结
加载全部内容