c++与python实现二分查找
机器学习入坑者 人气:0在计算机中,数据的查找方式与其存储方式关系密切。试想一下,如果图书馆中书籍杂乱无章的存放,那么要想找到心仪的书籍将会非常困难。为此,人们常常将物品按照某种规则或次序进行放置,目的是便于日后的查找。
作为查找算法家族中的一员,二分查找正是利用数据按次序存储这一优点,极大的提升了查找目标值所在位置的速度。
二分查找的核心思想是:首先将数组中间值和目标值进行比较,如果相等则返回;如果不相等,则选择中间值左边的一半或者右边的一半进行比较;不断重复直到检索完毕。首先来看下面这个gif,其中蓝色圈表示左位置,粉色圈表示右位置,绿色圈表示中间位置:
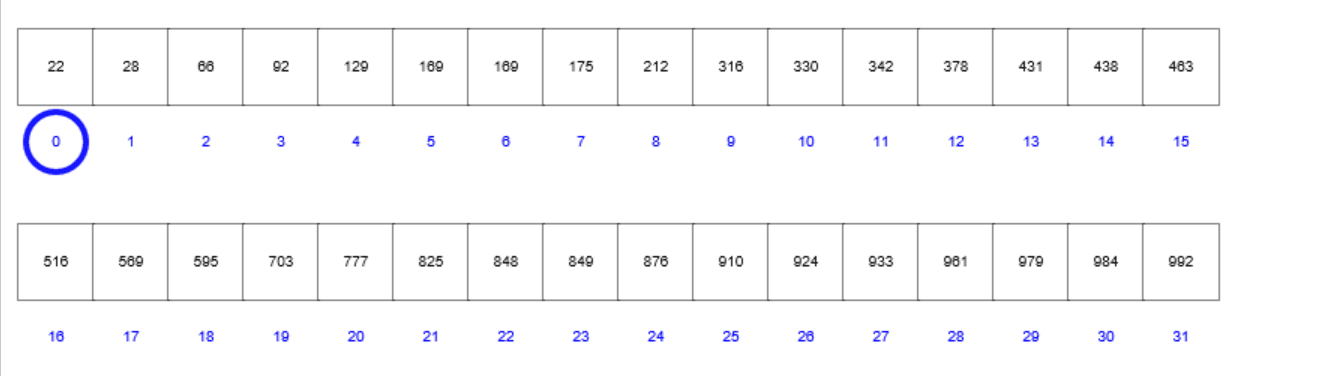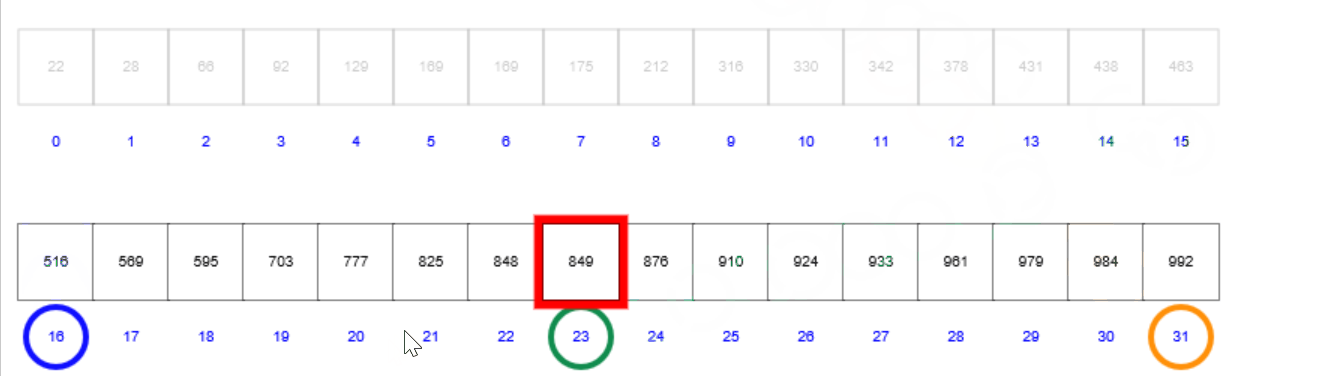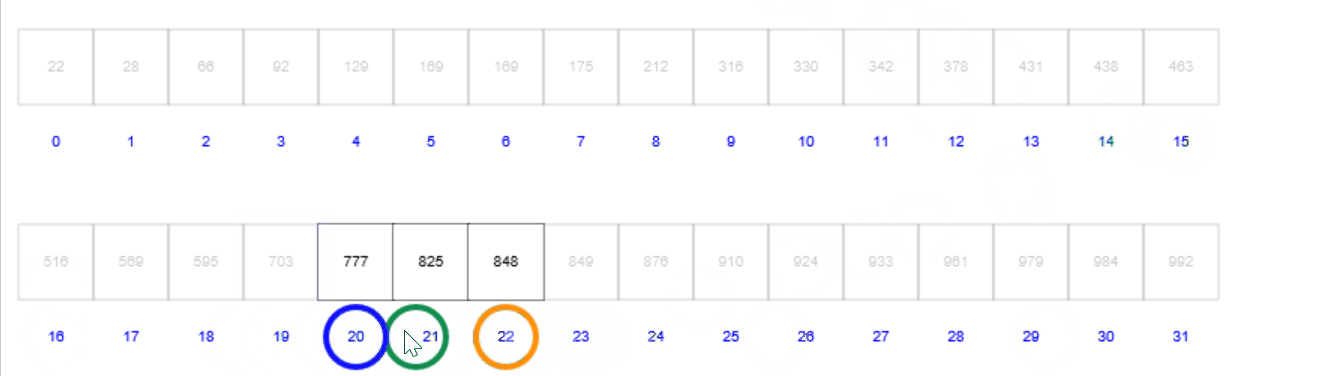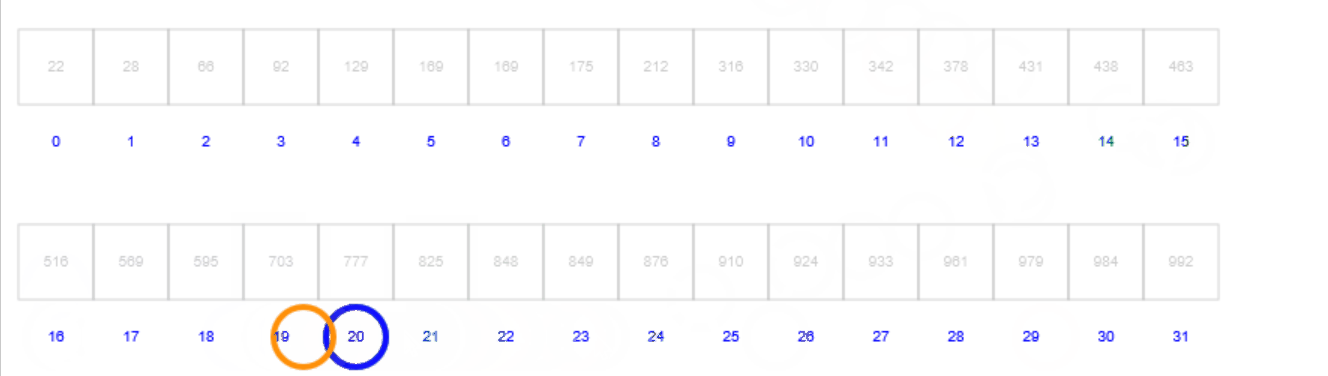
首先定义的是左边界(蓝色圈)和右边界(粉色圈),进而根据左边界和右边界计算出中间位置(绿色圈);然后,比较中间位置的值和目标值的大小,比较结果包含3种情况
- 如果相等则表示查找成功,返回中间位置;
- 如果中间位置的值小于目标值,则说明目标值在中间位置到右边界这一半;
- 如果中间位置的值大于目标值,则说明目标值在左边界到中间位置这一半;
上述步骤的循环需要终止条件,即左边界小于或等于右边界,表明此时已经搜索完成,目标数值不在数据中存在。
1、时间复杂度与优缺点
既然每次搜索后区间长度都减半,假设数据个数(即区间长度)为n,那么算法每次迭代得到的区间长度依次为n/2,n/4,n/8等等,其通项如下,k表示循环次数:
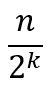
最坏的情况,就是搜索到区间长度为1,即最后只剩1个元素:
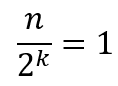
所以,可以求得最坏情况下需要运行的次数为:
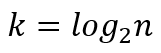
因此二分查找复杂度为O(logn),相比于顺序查找其速度获得了极大的提高(优点)。但是,必须注意二分查找需要保证数据是有序的,这就要求数据必须预先进行排序(缺点)。
2、python实现
def binary_search(ordered_list, target_value):
"""
Args:
ordered_list: data with order
target_value: value that want be searched
"""
left = 0
right = len(ordered_list)-1
# 终止条件
while left <= right:
# 中间位置计算
mid = int((left+right)/2)
if ordered_list[mid] == target_value:
return "index is {}, target value is {}".format(mid, ordered_list[mid])
# 此时目标值在中间值右边,更新左位置
elif ordered_list[mid] < target_value:
left = mid + 1
# 此时目标值在中间值左边,更新右位置
elif ordered_list[mid] > target_value:
right = mid - 1
# 搜索结束没有找到
return "Not find"3、C++实现
int binarySearch(int *orderedData, int dataLength, int targetValue) {
int left = 0;
int right = dataLength - 1;
int mid;
// 终止条件
while (left<=right)
{
// 中间位置计算
mid = (left + right) / 2;
if (*(orderedData + mid) == targetValue) {
return mid;
}
// 目标值在中间值右边,更新左位置
else if (*(orderedData + mid) < targetValue){
left = mid + 1;
}
// 目标值在中间值左边,更新右位置
else
{
right = mid - 1;
}
}
// 搜索不到,返回-1
return -1;
}加载全部内容