级联分类器算法
wumh7 人气:0一、人脸检测算法分类
目前人脸检测方法主要分为两大类,基于知识和基于统计。
基于知识的人脸检测方法主要包括:模板匹配,人脸特征,形状与边缘,纹理特征,颜色特征。
基于统计的人脸检测方法主要包括:主成分分析与特征脸法,神经网络模型,隐马尔可夫模型,支持向量机,Adaboost算法。
基于知识的方法将人脸看成不同特征的特定组合,即通过人脸的眼睛、嘴巴、鼻子、耳朵等特征及其组合关系来检测人脸。
基于统计的方法将人脸看成统一的二维像素矩阵,通过大量的样本构建人脸子空间,通过相似度的大小来判断人脸是否存在。
二、Haar分类器算法
本文介绍的Haar分类器方法,包含了Adaboost算法。
Haar算法实际上是运用了boosting算法中的Adaboost算法。Haar分类器利用Adaboost算法构建一个强分类器进行级联,而在底层特征抽取上采用的是高校的矩形特征以及积分图方法。
Haar分类器=类Haar特征+积分图法+Adaboost算法+级联。
Haar分类器主要步骤如下:
1. 提取类Haar特征;
2. 利用积分图法对类Haar特征提取进行加速;
3. 使用Adaboost算法训练强分类器,区分出人脸和非人脸;
4. 使用筛选式级联把强的分类器级联在一起,从而提高检测准确度。
2.1 人脸检测的大概流程
我们用一个小的窗口在一幅图片中不断的滑动,每滑动到一个位置,就对该小窗口内的图像进行特征提取,若提取到的特征通过了所有训练好的强分类器的判定,则我们判定该小窗口的图片内含有人脸。
2.2 Haar-like特征
Viola牛们提出的Haar-like特征如下:
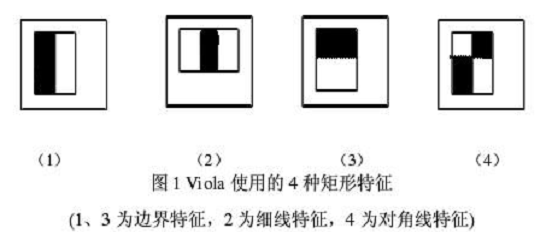
将Haar-like特征在图片上进行滑动,在每个位置计算白色区域对应的像素值的和减去黑色区域对应的像素值的和,从而提取出该位置的特征,人脸区域与非人脸区域提取出的特征值不同,从而区分出人脸区域和非人脸区域。
我们可以用多个矩形特征计算得到一个区分度更大的特征值,从而增加人脸区域和非人脸区域的区分度。那么该怎么组合这些矩形特征才能得到更好的区分度呢?Adaboost算法就是用来解决这个问题的。
2.3 Adaboost算法
Adaboost算法是一种一般性的分类器性能提升算法,不仅仅是限定于一种算法。Adaboost算法可以用来更好地选择矩形特征的组合,而这些矩形特征的组合就构成了分类器,分类器以决策树的方式存储这些矩形特征组合。
Adaboost是基于boosting算法的,而boosting算法涉及到弱分类器和强分类器的概念。弱分类器是基于弱学习的,其分类正确率较低,但是较容易获得,强分类器是基于强学习,其分类正确率较高,但是较难获得。
Kearns和Valiant两个大神提出弱学习和强学习是等价的,并且证明只要样本充足,弱学习可以通过一定的组合获得任意精度的强学习。这个证明为boostting算法提供了理论基础,使其成为一个能够提高分类器性能的一般性方法。
而boosting算法主要存在两个问题,一个是它需要预先知道弱分类器的误差,另一个是它在训练后期会专注于几个难以分类的样本,因此会变得不稳定。针对这些问题,后来Freund和Schapire提出了实际可行的Adaboost算法。
2.4 弱分类器的构建
我们可以用决策树来构建一个简单的弱分类器, 将提取到的特征与分类器的特征进行逐个比较,从而判断该特征是否属于人脸,如下图所示:
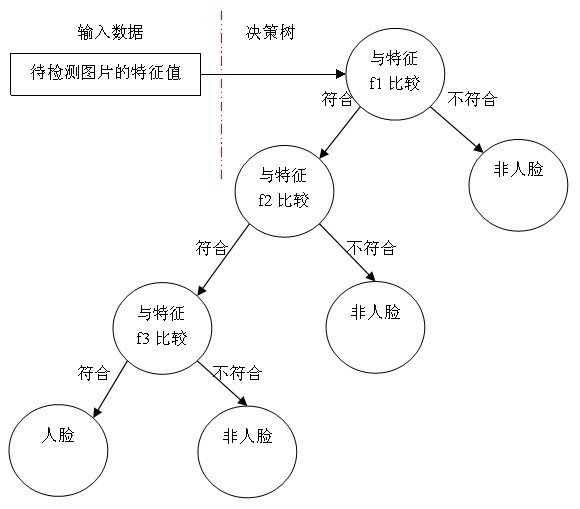
该分类器的重点在于阈值的设定。阈值的设定方法如下:
(1)对于每个分类器计算训练样本的特征值;
(2)对这些特征值进行排序;
(3)计算所有属于人脸的样本的特征值的和t1和所有属于非人脸的样本的特征值的和t0;
(4)计算第i个样本前所有属于人脸的样本的特征值的和s1is1i和属于非人脸的样本的特征值的和s0is0i;
(5)计算r=min((s1+(t0i−s0i)),s0+(t1i−s1i))r=min((s1+(t0i−s0i)),s0+(t1i−s1i))。
计算得到的最小的rr值即为所求阈值。有了阈值,我们便用决策树构成了一个简单的弱分类器,如下所示:

其中x子图像窗口,f是特征,p的作用是控制不等号方向,使得不等号都为"<",θθ是阈值。
2.5 强分类器的构造
这个部分我还是似懂非懂。按照我的理解,强分类为的构造是这样的:
(1)首先选出部分样本,给它们赋予权重1/N,其中N为总的样本的个数;
(2)用选出的样本训练弱分类器;
(3)提高错误分类的样本的权重,并舍弃正确分类的样本,加入新的样本,新的样本的权重还是之前的1/N,进行新一轮的弱分类器的训练;
(4)经过T轮后,训练出T个弱分类器;
(5)将这T个弱分类器根据他们的分类错误率加权求和构成一个强的分类器,如下所示:
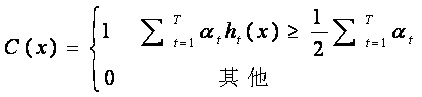
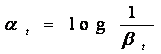
其中αtαt是第t个弱分类器的权重,βtβt是第t个弱分类器的错误率。强分类器相当于先让各个弱分类器进行投票,然后让投票结果根据各弱分类器的错误率进行加权相加,最后与平均的投票结果进行比较得到最终结果。
Reference:
加载全部内容