Python文件查找
渴望力量的哈士奇 人气:0该章节将学习关于文件查找的操作,大家都知道,无论是 Linux 系统还是 Windows 系统都有基于文件名实现过滤、查找的功能。但是如果想要查找一些关于某些文件指定内容的文件,好像无论是 Linux 还是 Windows 明面上没有这样的功能了。这个时候就可以通过 Python 来实现这样的功能,通过该章节的学习,就可以学习到该功能的如何利用 Python 实现这样的操作。
文件查找操作
glob 的介绍
glob 包是一个快速查找文件夹中内容的包,可以通过模糊查找的形式找到我们想要的内容。
glob 的基本使用
导入包与模块
from glob import glob
使用方法
glob(任意目录)
返回内容:
指定路径下的内容列表,不存在的路径返回空列表。
代码示例如下:
# coding:utf-8 import os from glob import glob target = os.getcwd() result = glob(target) print(result) # 打印输出当前路径的文件夹 result = glob(target + '/*') print(result) # 打印输出当前路径的文件夹下的所有文件 result = glob(target + '/*.py') print(result) # 打印输出当前路径的文件夹下的所有以 "py" 结尾的文件 result = glob(target + '/*.zip') print(result) # 打印输出当前路径的文件夹下的所有以 "zip" 结尾的文件 result = glob(target + '/filetest*') print(result) # # 打印输出当前路径的文件夹下的所有以 "filetest" 开头的文件
运行结果如下:
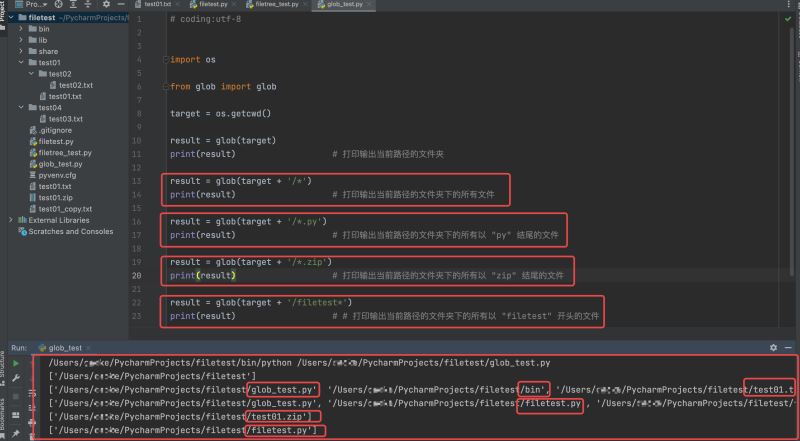
查找指定的文件
已知条件:
想查找的文件名已经知道,但是目录在哪里并不知道。
实现方法:
利用 "glob" 从最上级目录开始查找,利用递归模式,不断的查找,直到找到为止。
代码示例如下:
# coding:utf-8
import glob
"""
获取当前路径下所有内容
判断每个内容的类型(文件夹还是文件)
若是文件夹则继续递归查找
"""
path = glob.os.path.join(glob.os.getcwd(), '*') # 获取当前文件夹下的所有内容
# glob 模块其实已经包含了 "os" 模块
final_result = [] # 定义一个空列表,用以存储 search() 函数查到的内容
def search(path, target): # 定义 search() 函数,传入 "path" 文件路径, "target" 要查找的目标文件
result = glob.glob(path)
for data in result: # for 循环判断递归查到的内容是文件夹还是文件
if glob.os.path.isdir(data): # 若是文件夹,继续将该文件夹的路径传给 search() 函数继续递归查找
_path = glob.os.path.join(data, '*')
search(_path, target)
else: # 若是文件,则将该查询到的文件所在路径插入 final_result 空列表
if target in data:
final_result.append(data)
return final_result
if __name__ == '__main__':
result = search(path, target='filetest.py')
print(result)
运行结果如下:
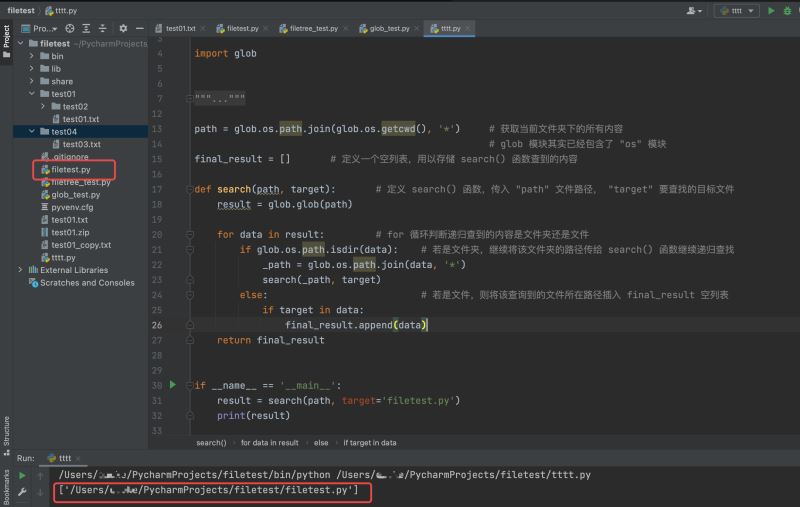
基于文件内容查找文件
接下来我们看一下查找指定内容的文件:
已知条件:
文件中包含有某些关键字,但是不知道文件名和文件所在路径
实现方法:
利用 "glob" 从最上级目录开始查找,利用递归模式,不断的查找。如果是文件夹则进入继续查找,是文件则读取,判断是否包含该内容,返回该内容的文件名以及所在路径。
其实,基于文件内容查找文件实现的方式大体与上文的查找指定文件大体相似,只不过加入了读取文件的判断罢了。
代码示例如下:
# coding:utf-8
import glob
"""
获取当前路径下所有内容
判断每个内容的类型(文件夹还是文件)
若是文件夹则继续递归查找
"""
path = glob.os.path.join(glob.os.getcwd(), '*test04') # 因为下文捕获不可读文件格式太多,所以这里直接指定了 "test04" 路径
final_result = [] # 定义一个空列表,用以存储 search() 函数查到的内容
def search(path, target): # 定义 search() 函数,传入 "path" 文件路径, "target" 要查找的目标文件
result = glob.glob(path)
for data in result: # for 循环判断递归查到的内容是文件夹还是文件
if glob.os.path.isdir(data): # 若是文件夹,继续将该文件夹的路径传给 search() 函数继续递归查找
_path = glob.os.path.join(data, '*')
search(_path, target)
else: # 若是文件,则将该查询到的文件所在路径插入 final_result 空列表
f = open(data, 'r') # 利用 open() 函数读取文件,并通过 try...except... 捕获不可读的文件格式(.zip 格式)
try:
content = f.read()
if target in content:
final_result.append(data)
except:
print('这是不可读文件格式的文件的所在路径:{} '.format(data))
continue
finally:
f.close()
return final_result
if __name__ == '__main__':
result = search(path, target='测试文件')
print(result)
运行结果如下:
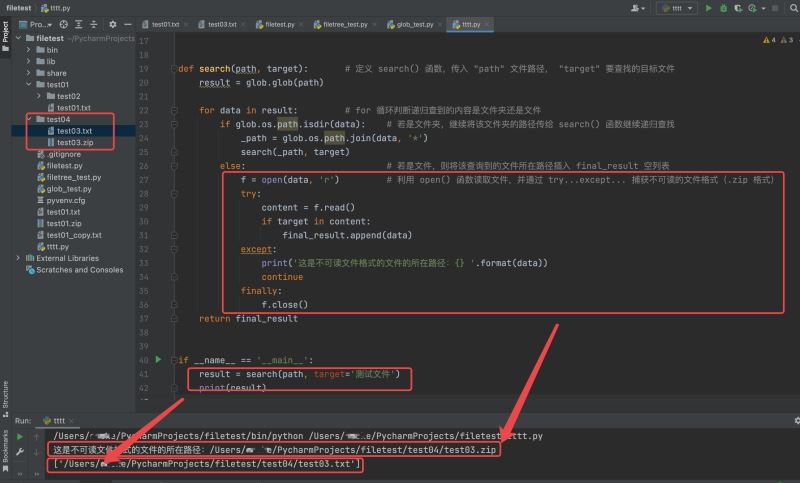
加载全部内容