Python多分类混淆矩阵
胖大海pyh 人气:111、什么是混淆矩阵
深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分。它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
首先要明确几个概念:
T或者F:该样本 是否被正确分类。
P或者N:该样本 原本是正样本还是负样本。
- 真正例(True Positive,TP):预测正确;模型预测也是正例,样本的真实类别是正例,
- 真负例(True Negative,TN):预测正确:模型预测为负例,样本的真实类别是负例,
- 伪正例(False Positive,FP):预测错误:模型预测为正例,样本的真实类别是负例,
- 伪负例(False Negative,FN):预测错误;模型预测为负例,样本的真实类别是正例,
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix),这里从其他文章偷了张图:

在混线矩阵中,以对角线为分界线。以上图为例子:对角线的位置表示预测正确,对角线以外的位置表示把样本错误的预测为其他样本。
2、分类模型评价指标
从混淆矩阵可以直观地看出各个参数的数值大小。查准率是在模型预测为正的所有样本中,模型预测对的比重,即:“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。计算公式如下式所示:

F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差,计算公式如下式所示:
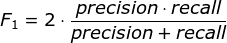
除了F1分数之外,F2分数和F0.5分数在统计学中也得到大量的应用。其中,F2分数中,召回率的权重高于精准率,而F0.5分数中,精准率的权重高于召回率。
3、两种多分类混淆矩阵
多分类混淆矩阵根据不同需求可以绘制不同的矩阵:
1、直接打印出每一个类别的分类准确率。
2、打印具体的分类结果的数值,方便数据的分析和各类指标的计算
在介绍具体代码之前,首先来介绍confusion_matrix()函数,它是Python中的sklearn库提供的输出矩阵数据的方法:
def confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):
参数意义:
- y_true: 是样本真实分类结果,y_pred: 是样本预测分类结果
- y_pred:预测结果
- labels:是所给出的类别,通过这个可对类别进行选择
- sample_weight : 样本权重
3.1直接打印出每一个类别的分类准确率。
# 显示混淆矩阵
def plot_confuse(model, x_val, y_val):
# 获得预测结果
predictions = predict(model,x_val)
#获得真实标签
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
cm = confusion_matrix(y_true=truelabel, y_pred=predictions)
plt.figure()
# 指定分类类别
classes = range(np.max(truelabel)+1)
title='Confusion matrix'
#混淆矩阵颜色风格
cmap=plt.cm.jet
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
# 按照行和列填写百分比数据
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, '{:.2f}'.format(cm[i, j]), horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
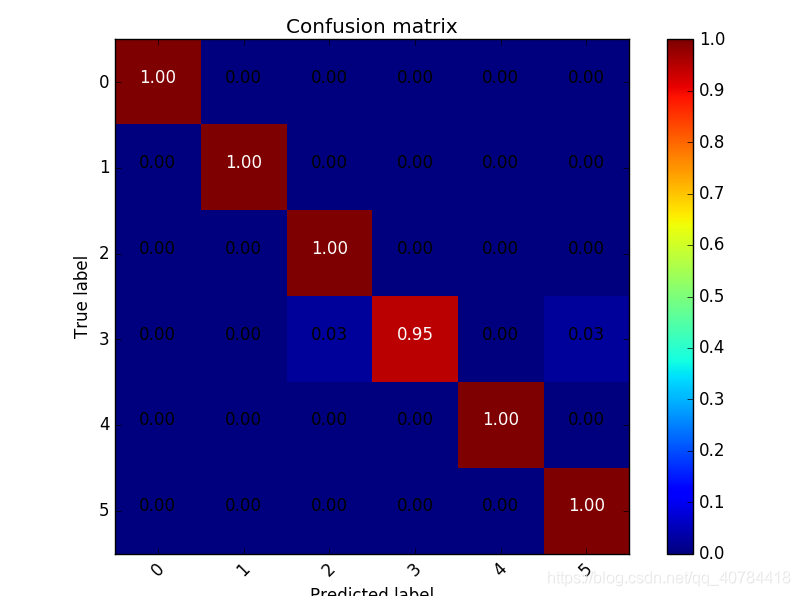
3.2打印具体的分类结果的数值
# 显示混淆矩阵
def plot_confuse_data(model, x_val, y_val):
classes = range(0,6)
predictions = predict(model,x_val)
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
confusion = confusion_matrix(y_true=truelabel, y_pred=predictions)
#颜色风格为绿。。。。
plt.imshow(confusion, cmap=plt.cm.Greens)
# ticks 坐标轴的坐标点
# label 坐标轴标签说明
indices = range(len(confusion))
# 第一个是迭代对象,表示坐标的显示顺序,第二个参数是坐标轴显示列表
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion matrix')
# plt.rcParams两行是用于解决标签不能显示汉字的问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 显示数据
for first_index in range(len(confusion)): #第几行
for second_index in range(len(confusion[first_index])): #第几列
plt.text(first_index, second_index, confusion[first_index][second_index])
# 显示
plt.show()
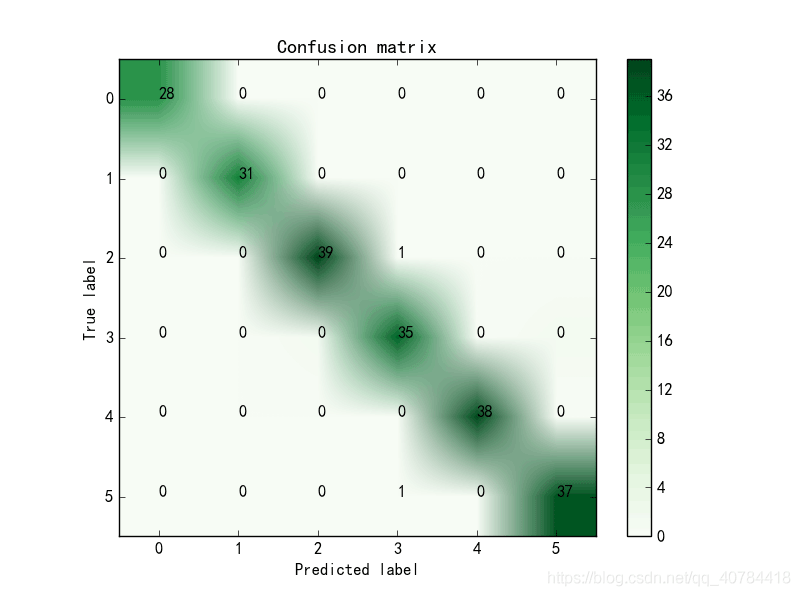
4、总结
1、混淆矩阵是深度学习中分类模型最常用的评估指标。网上大部分都是显示各类的分类正确率,不够灵活。显示具体数值灵活性大,可以计算自己想要的指标。
2、多分类的混淆矩阵中 查准率为主对角线上的值除以该值所在列的和;召回率等于主对角线上的值除以该值所在行的和。
加载全部内容