Qt文件编码格式识别
feiyangqingyun 人气:0一、前言
在做数据导入导出的过程中,如果应用场景多了,相信各位都会遇到一个问题就是文件编码的问题,有些文件是ANSI编码,有些是utf8编码,有些又是utf8带bom编码,不同的文件编码如果都用同一种编码格式去解析读取出来的数据的话,肯定会遇到乱码的问题,这并不是Qt的问题,也不是什么Qt乱码的问题,而是要识别到文件的编码然后用对应的编码去读取内容,这样就不会出现乱码,当然乱码的出现肯定是中文,如果文件全部是英文数字,无论何种编码,都不会乱码。
那么问题来了,如何用程序自动识别文件的编码格式呢?找遍了搜索没有找到完整的答案。查阅资料得知utf8带bom编码都会有个固定的头部字节EFBBBF,所以这个好区分,由于ANSI编码和utf8编码没有对应的头部字节标识,所以需要转个弯来处理,依然是读取头部的三个字节,用QTextCodec的toUnicode函数转换,转换结果的ConverterState可以识别到可用字符数量,如果数量大于0说明是ANSI编码,需要用gbk去解码。
二、功能特点
- 组件同时集成了导出数据到csv、xls、pdf和打印数据。
- 所有操作全部提供静态方法无需new,数据和属性等各种参数设置采用结构体数据,极为方便。
- 同时支持QTableView、QTableWidget、QStandardItemModel、QSqlTableModel等数据源。
- 提供静态方法直接传入QTableView、QTableWidget控件,自动识别列名、列宽和数据内容。
- 每组功能都提供单独的完整的示例,注释详细,非常适合各阶段Qter程序员。
- 原创导出数据机制,不依赖任何office组件或者操作系统等第三方库,支持嵌入式linux。
- 速度超快,9个字段10万行数据只需要2秒钟完成。
- 只需要四个步骤即可开始急速导出海量数据比如100W条记录到Excel。
- 同时提供直接写入数据接口和多线程写入数据接口,不卡主界面。
- 可设置标题、副标题、表名。
- 可设置导出数据的字段名、列名、列宽。
- 可设置末尾列自动拉伸填充,默认拉伸更美观。
- 可设置是否启用校验过滤数据,启用后符合规则的数据特殊颜色显示。
- 可指定校验的列、校验规则、校验值、校验值数据类型。
- 校验规则支持 精确等于==、大于>、大于等于>=、小于<、小于等于<=、不等于!=、包含contains。
- 校验值数据类型支持 整型int、浮点型float、双精度型double,默认文本字符串类型。
- 可设置随机背景颜色及需要随机背景色的列集合。
- 支持分组输出数据,比如按照设备分组输出数据,方便查看。
- 可设置csv分隔符、行内容分隔符、子内容分隔符。
- 可设置边框宽度、自动填数据类型,默认自动数据类型开启。
- 可设置是否开启数据单元格样式,默认不开启,不开启可以节约大概30%的文件体积。
- 可设置横向排版、纸张边距等,比如导出到pdf以及打印数据。
- 提供图文混排导出数据到pdf以及打印示例,自动分页,支持多图。
- 提供一个打印样板中同时包括横向纵向排版示例。
- 提供静态函数将控件截图导出到pdf文件。
- 提供静态函数将图片转成pdf文件。
- 提供静态函数将csv文件转成xls文件,支持列宽表名等参数设置。
- 针对每列可分别设置字段对齐样式、内容对齐样式,包括左对齐、居中对齐、右对齐。
- 灵活性超高,可自由更改源码设置对齐方式、文字颜色、背景颜色等。
- 支持任意excel表格软件,包括但不限于excel2003-2021、wps、openoffice等。
- 纯Qt编写,支持任意Qt版本+任意编译器+任意系统。
三、体验地址
体验地址:http://pan.baidu.com/s/1eeL5MTz0rifwtVLegRpkoQ 提取码:erxm 文件名:bin_dataout.zip
国内站点:https://gitee.com/feiyangqingyun
国际站点:https://github.com/feiyangqingyun
四、效果图
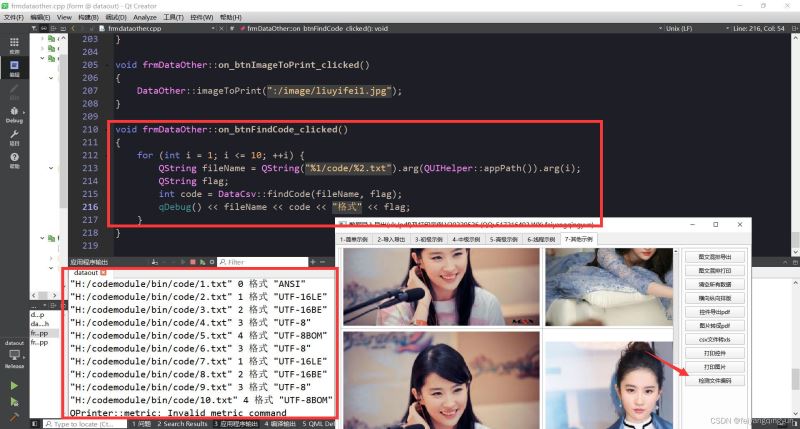
五、相关代码
//检查文件编码 0=ANSI 1=UTF-16LE 2=UTF-16BE 3=UTF-8 4=UTF-8BOM
int DataCsv::findCode(const QString &fileName, QString &flag)
{
//假定默认编码utf8
int code = 3;
flag = "UTF-8";
QFile file(fileName);
if (file.open(QIODevice::ReadOnly)) {
//读取3字节用于判断
QByteArray buffer = file.read(3);
quint8 b1 = buffer.at(0);
quint8 b2 = buffer.at(1);
quint8 b3 = buffer.at(2);
if (b1 == 0xFF && b2 == 0xFE) {
code = 1;
flag = "UTF-16LE";
} else if (b1 == 0xFE && b2 == 0xFF) {
code = 2;
flag = "UTF-16BE";
} else if (b1 == 0xEF && b2 == 0xBB && b3 == 0xBF) {
code = 4;
flag = "UTF-8BOM";
} else {
//尝试用utf8转换,如果可用字符数大于0,则表示是ansi编码
QTextCodec::ConverterState state;
QTextCodec *codec = QTextCodec::codecForName("utf-8");
codec->toUnicode(buffer.constData(), buffer.size(), &state);
if (state.invalidChars > 0) {
code = 0;
flag = "ANSI";
}
}
file.close();
}
return code;
}
加载全部内容