python爬取显示进度条
knighthood2001 人气:0前言:
在爬取并下载网页上的视频的时候,我们需要实时进度条,这可以帮助我们更直观的看到视频的下载进度。
一、全部代码展示
from contextlib import closing
from requests import get
url = 'https://v26-web.douyinvod.com/57cdd29ee3a718825bf7b1b14d63955b/615d475f/video/tos/cn/tos-cn-ve-15/72c47fb481464cfda3d415b9759aade7/?a=6383&br=2192&bt=2192&cd=0%7C0%7C0&ch=26&cr=0&cs=0&cv=1&dr=0&ds=4&er=&ft=jal9wj--bz7ThWG4S1ct&l=021633499366600fdbddc0200fff0030a92169a000000490f5507&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ank7OzU6ZnRkNjMzNGkzM0ApNmY4aGU8MzwzNzo3ZjNpZWdiYXBtcjQwLXNgLS1kLTBzczYtNS0tMmE1Xi82Yy9gLTE6Yw%3D%3D&vl=&vr='
with closing(get(url, stream=True)) as response:
chunk_size = 1024 # 单次请求最大值
# response.headers['content-length']得到的数据类型是str而不是int
content_size = int(response.headers['content-length']) # 文件总大小
data_count = 0 # 当前已传输的大小
with open('文件名.mp4', "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
done_block = int((data_count / content_size) * 50)
# 已经下载的文件大小
data_count = data_count + len(data)
# 实时进度条进度
now_jd = (data_count / content_size) * 100
# %% 表示%
print("\r [%s%s] %d%% " % (done_block * '█', ' ' * (50 - 1 - done_block), now_jd), end=" ")注:上面的url已过期,需要各位自己去找网页上的视频url
二、解释
1.with closing
我们在日常读取文件资源时,经常会用到with open() as f:的句子。
但是使用with语句的时候是需要条件的,任何对象,只要正确实现了上下文管理,就可以使用with语句,实现上下文管理是通过__enter__和__exit__这两个方法实现的。
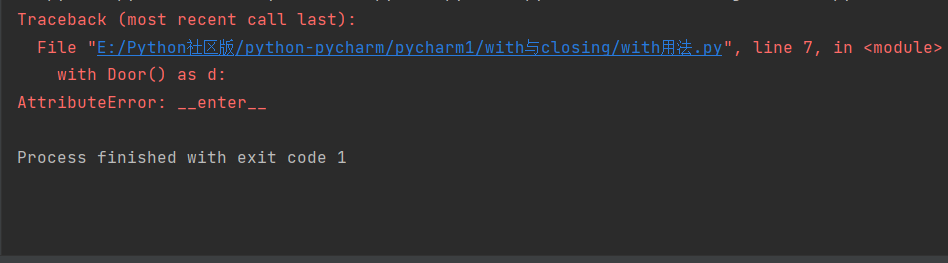
with用法(没有实现上下文管理)
class Door():
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()结果报错了:
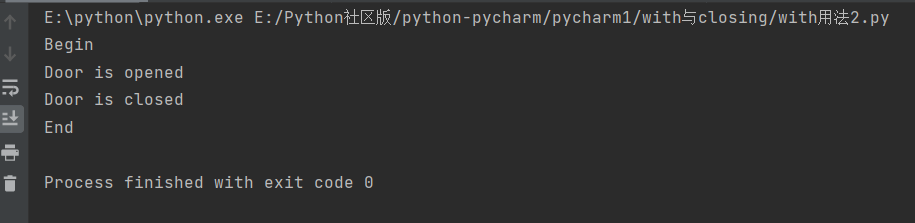
with用法(实现上下文管理)
用__enter__和__exit__实现了上下文管理
class Door():
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()结果没报错:
closing用法(完美解决上述问题)
一个对象没有实现上下文,我们就不能把它用于with语句。这个时候,可以用contextlib中的
closing()来把该对象变为上下文对象。
class Door():
def __enter__(self):
print('Begin')
return self
def __exit__(self, exc_type, exc_value, traceback):
if exc_type:
print('Error')
else:
print('End')
def open(self):
print('Door is opened')
def close(self):
print('Door is closed')
with Door() as d:
d.open()
d.close()例如:用with语句使用requests中的get(url)
也就是本文中的案例,使用with closing()下载视频(在网页中)
2.文件流stream
想象一下,如果把文件读取比作向池子里抽水,同步会阻塞程序,异步会等待结果,如果池子非常大呢?
因此有了文件流,它就好比你一边抽一边取,不用等池子满了再用,
所以对于一些大型文件(几个G的视频)一般会用到这个参数。(对小型文件也可以使用)
3.response.headers['content-length']
这表示获取文件的总大小,但是它得到的结果的数据类型是str而不是int,因此需要进行数据类型转换。
4.response.iter_content()
该方法一般用于从网上下载文件和网页(需要用到requests.get(url))
其中chunk_size表示单次请求最大值。
5.\r和%
\r表示回车(回到行首)
%是一种占位符
而对于%%,第一个%起到了转义的作用,使结果输出为百分号%
三、结果展示

四、总结
我之前看了许多的进度条,这些进度条都能动,但是满足不了根据文件内容进行加载(里面的参数要么都定死了,要么就与文件大小无关),不能做到真正的交互功能,这次的进度条就很好的展示了,大家可以去试试!!
这次下载视频展示进度条是争对一个url,大家可以将它加到你的爬虫的循环中,这样就能在爬每个视频的时候展示实时进度条了!!
加载全部内容