Python使用re模块正则表达式
ζ小菜鸡 人气:0一、前言
在Python提供了re模块,用于实现正则表达式的操作。在实现时,可以使用re模块提供的方法(如,search()、match()、findall()等)进行字符串处理,也可以先使用re模块的compile()方法将模式字符串转换为正则表达式对象,然后再使用该正则表达式对象的相关方法来操作字符串。
如果使用re模块时,未将其引入,将抛出异常如图所示:

二、匹配字符串
匹配字符串可以使用re模块提供的match()、seardch()和findall()等方法。
1.使用match()方法进行匹配
match()方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None,语法格式如下:
re.match(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来
- string:表示要匹配的字符串
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。常用的标志如表所示:
| 标志 | 说明 |
|---|---|
| A或ASCII | 对于\w、\W、\b、\B、\d、\D、\s和\S只进行ASCII匹配(仅适用于Python3.X) |
| I或IGNORECASE | 执行不区分字母大小写的匹配 |
| M或MULTILINE | 将^和$用于包括整个字符串的开始和结尾的每一行(默认情况下,仅适用于整个字符串的开始和结尾处) |
| S或DOTALL | 适用(.)字符匹配所有字符,包括换行符 |
| X或VERBOSE | 忽略模式字符串中未转义的空格和注释 |
例如,匹配字符串是否以“mr_”开头,不区分字母大小写,代码如下:
import re pattern = r"mr_\w+" #模式匹配字符串 string = "MR_SHOP mr_shop" #要匹配的字符串 match = re.match(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果 string = "项目名称MR_SHOP mr_shop" match = re.match(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果
执行结果如下:
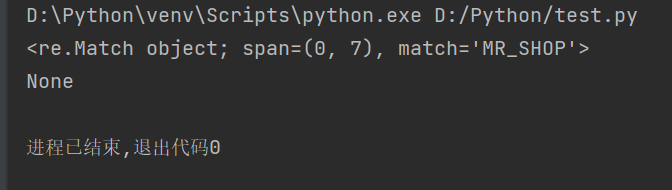
从上面执行结果中可以看出,字符串"MR_SHOP"是以“mr_”开头,所以返回一个match对象,而字符串“项目名称MR_SHOP”不是以“mr_”开头,将返回“None”。这是因为match()方法从字符串的开始位置开始匹配,当第一个字母不符合条件时,则不再进行匹配,直接返回None。
Match对象中包含了匹配值得位置和匹配数据,其中:
- 要获取匹配值的起始位置可以使用Match对象的start()方法;
- 要获得匹配值的结束位置可以使用end()方法;
- 通过span()方法可以返回匹配位置元组;
- 通过string属性可以获取要匹配的字符串
代码如下:
import re
pattern = r"mr_\w+" # 模式匹配字符串
string = "MR_SHOP mr_shop" # 要匹配的字符串
match = re.match(pattern, string, re.I) # 匹配字符,不区分大小写
print("匹配值的起始位置", match.start())
print("匹配值的结束位置", match.end())
print("匹配位置元组", match.span())
print("要匹配的字符串", match.string)
print("匹配数据", match.group())
执行结果如下:

2.使用search()方法进行匹配
search()方法用于在整个字符串搜索第一个匹配值,如果匹配成功,则返回match对象,否则返回None,语法格式如下:
re.search(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来
- string:表示要匹配的字符串
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,所示一个以“mr_”开头的字符串,不区分大小写,代码如下:
import re pattern = r"mr_\w+" #模式匹配字符串 string = "MR_SHOP mr_shop" #要匹配的字符串 match = re.search(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果 string = "项目名称MR_SHOP mr_shop" match = re.search(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果
执行结果如下:

从上面运行结果中可以看出,search()方法不仅仅是在字符串的起始位置搜索,其他位置有符合的匹配也可以。
3.使用findall()方法进行匹配
findall()方法用于整个字符串中的搜索所有符合正则表达式的字符串,并以列表的形式返回,如果匹配成功,则返回包含匹配结构的列表,否则返回空列表。其语法格式如下:
re.findall(pattern, string, [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来
- string:表示要匹配的字符串
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如,所示一个以“mr_”开头的字符串,不区分大小写,代码如下:
import re pattern = r"mr_\w+" #模式匹配字符串 string = "MR_SHOP mr_shop" #要匹配的字符串 match = re.findall(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果 string = "项目名称MR_SHOP mr_shop" match = re.findall(pattern,string,re.I)#匹配字符,不区分大小写 print(match) #输出匹配结果
执行结果如下:
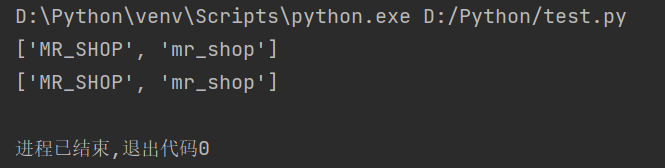
如果在指定的模式字符串中,包含分组,则返回与分组匹配的文本列表。例如:
import re
pattern = r"[1-9]{1,3}(\.[0-9]{1,3}){3}" # 模式字符串
str1 = "127.0.0.1 192.168.1.66" # 要匹配的字符串
match = re.findall(pattern, str1) # 进行模式匹配
print(match)
执行结果如下:

从上面结果中可以看出,并没有得到匹配的IP地址,这是因为在模式字符串中出现了分组,所以得到的结果是根据分组进行匹配的结果,即“(.[0-9]{1,3})”匹配的结果。如果想获取整个模式字符串的匹配,可以将整个模式字符串使用一对小括号进行分组,然后再获取结果时,只取返回值列表的每个元素(是一个元组)的第1个元素。代码如下:
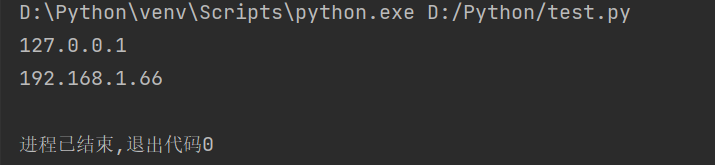
import re
pattern = r"([1-9]{1,3}(\.[0-9]{1,3}){3})" # 模式字符串
str1 = "127.0.0.1 192.168.1.66" # 要匹配的字符串
match = re.findall(pattern, str1) # 进行模式匹配
for item in match:
print(item[0])
执行结果如下:
三、替换字符串
sub()方法用于实现字符串替换,语法格式如下:
re.sub(pattern, sep1, string, count, flags)
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来
- sep1:表示替换的字符串
- string:表示查找要被替换的原始字符串
- count:可以参数,表示模式匹配后替换
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
import re
pattern = r"1[34578]\d{9}" # 定义要替换的模式字符串
string = "中奖号码为:84978981 联系电话为:13611111111"
result = re.sub(pattern, "1xxxxxxxxxx", string)
print(result)
执行结果如下:

四、使用正则表达式分割字符串
splist()方法用于实现根据正则表达式分割字符串,并以列表的形式返回,其作用与字符串对象的splist()方法类似,所不同的就是分割字符由模式字符串指定。语法格式如下:
re.splist(pattern, string, [maxsplist], [flags])
参数说明:
- pattern:表示模式字符串,由要匹配的正则表达式转换而来
- string:表示要匹配的字符串
- maxsplist:可选参数,表示最大的拆分次数。
- flags:可选参数,表示标志位,用于控制匹配方式,如是否区分字母大小写。
例如:从给定的URL地址中提取出请求地址和各个参数,代码如下:
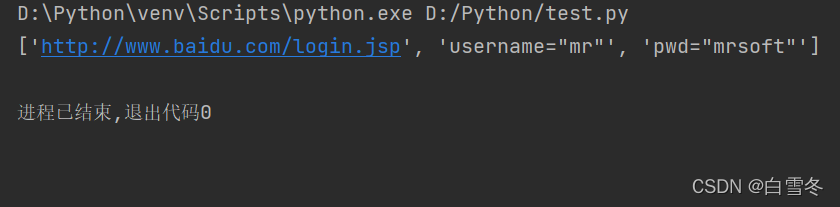
import re pattern = r"[?|&]" # 定义分割符 url = 'http://www.baidu.com/login.jsp?username="mr"&pwd="mrsoft"' result = re.split(pattern, url) # 分割字符串 print(result)
执行结果如下:
总结
加载全部内容