SpringBoot数据层
十八岁讨厌编程 人气:0前置导入
之前做SSMP整合的时候数据层解决方案涉及到了,MySQL数据库与MyBatisPlus框架,后面又涉及到了Druid数据源的配置,所以现在数据层解决方案可以说是Mysql+Druid+MyBatisPlus。而三个技术分别对应了数据层操作的三个层面:
- 数据源技术:Druid
- 持久化技术:MyBatisPlus
- 数据库技术:MySQL
下面的研究就分为三个层面进行研究,对应上面列出的三个方面,咱们就从第一个数据源技术开始说起。
数据源技术
目前我们使用的数据源技术是Druid,运行时可以在日志中看到对应的数据源初始化信息,具体如下:
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
如果不使用Druid数据源,程序运行后是什么样子呢?是独立的数据库连接对象还是有其他的连接池技术支持呢?将Druid技术对应的starter去掉再次运行程序可以在日志中找到如下初始化信息:
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
虽然没有DruidDataSource相关的信息了,但是我们发现日志中有HikariDataSource这个信息,就算不懂这是个什么技术,看名字也能看出来,以DataSource结尾的名称,这一定是一个数据源技术。我们又没有手工添加这个技术,这个技术哪里来的呢?它就是springboot内嵌数据源。
数据层技术是每一个企业级应用程序都会用到的,而其中必定会进行数据库连接的管理。springboot根据开发者的习惯出发,开发者提供了数据源技术,就用你提供的,开发者没有提供,那总不能手工管理一个一个的数据库连接对象啊,怎么办?我给你一个默认的就好了,这样省心又省事,大家都方便。
springboot提供了3款内嵌数据源技术,分别如下:
- HikariCP
- Tomcat提供DataSource
- Commons DBCP
第一种,HikartCP,这是springboot官方推荐的数据源技术,作为默认内置数据源使用。啥意思?你不配置数据源,那就用这个。
第二种,Tomcat提供的DataSource,如果不想用HikartCP,并且使用tomcat作为web服务器进行web程序的开发,使用这个。为什么是Tomcat,不是其他web服务器呢?因为web技术导入starter后,默认使用内嵌tomcat,既然都是默认使用的技术了,那就一用到底,数据源也用它的。有人就提出怎么才能不使用HikartCP用tomcat提供的默认数据源对象呢?把HikartCP技术的坐标排除掉就OK了。
第三种,DBCP,这个使用的条件就更苛刻了,既不使用HikartCP也不使用tomcat的DataSource时,默认给你用这个。
springboot这心操的,也是稀碎啊,就怕你自己管不好连接对象,给你一顿推荐,真是开发界的最强辅助。既然都给你奶上了,那就受用吧,怎么配置使用这些东西呢?之前我们配置druid时使用druid的starter对应的配置如下:
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ************
换成是默认的数据源HikariCP后,直接把druid删掉就行了,如下:
注意:这个地方同时还要把Druid的starter给删掉才行
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *****************
当然,也可以写上是对hikari做的配置,但是url地址要单独配置,如下(也就是另一种写法):
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *************
这就是配置hikari数据源的方式。如果想对hikari做进一步的配置,可以继续配置其独立的属性。例如:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: **************
maximum-pool-size: 50
如果不想使用hikari数据源,使用tomcat的数据源或者DBCP配置格式也是一样的。以后我们做数据层时,数据源对象的选择就不再是单一的使用druid数据源技术了,可以根据需要自行选择。
总结
springboot技术提供了3种内置的数据源技术,分别是Hikari、tomcat内置数据源、DBCP
持久化技术
说完数据源解决方案,再来说一下持久化解决方案。springboot充分发挥其最强辅助的特征,给开发者提供了一套现成的数据层技术,叫做JdbcTemplate。其实这个技术不能说是springboot提供的,因为不使用springboot技术,一样能使用它,谁提供的呢?spring技术提供的,所以在springboot技术范畴中,这个技术也是存在的,毕竟springboot技术是加速spring程序开发而创建的。
这个技术其实就是回归到jdbc最原始的编程形式来进行数据层的开发,下面直接上操作步骤:
步骤①:导入jdbc对应的坐标,记得是starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
步骤②:自动装配JdbcTemplate对象
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
步骤③:使用JdbcTemplate实现查询操作(非实体类封装数据的查询操作)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
结果:

步骤④:使用JdbcTemplate实现查询操作(实体类封装数据的查询操作)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}结果:
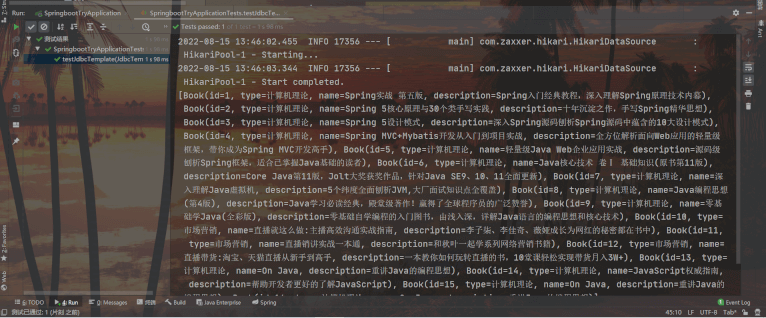
步骤⑤:使用JdbcTemplate实现增删改操作
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
} 如果想对JdbcTemplate对象进行相关配置,可以在yml文件中进行设定,具体如下:
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
fetch-size可以提高我们的查询性能。比如现在我们查了一万条数据,那么一次给我们几条呢?这个就可以由fetch-size来控制。假如一次给五十条,而我们也就用到了这五十条,那么效率会很高。而如果我们使用到50条之外的,它就会再来一次,效率降低。
总结
- SpringBoot内置JdbcTemplate持久化解决方案
- 使用JdbcTemplate需要导入spring-boot-starter-jdbc的坐标
数据库技术
截止到目前,springboot给开发者提供了内置的数据源解决方案和持久化解决方案,在数据层解决方案三件套中还剩下一个数据库,莫非springboot也提供有内置的解决方案?还真有,还不是一个,有三个
springboot提供了3款内置的数据库,分别是:
- H2
- HSQL
- Derby
以上三款数据库除了可以独立安装之外,还可以像是tomcat服务器一样,采用内嵌的形式运行在spirngboot容器中。内嵌在容器中运行,那必须是java对象啊,对,这三款数据库底层都是使用java语言开发的。
我们一直使用MySQL数据库就挺好的,为什么有需求用这个呢?原因就在于这三个数据库都可以采用内嵌容器的形式运行,在应用程序运行后,如果我们进行测试工作,此时测试的数据无需存储在磁盘上,但是又要测试使用,内嵌数据库就方便了,运行在内存中,该测试测试,该运行运行,等服务器关闭后,一切烟消云散,多好,省得你维护外部数据库了。这也是内嵌数据库的最大优点,方便进行功能测试。
下面以H2数据库为例讲解如何使用这些内嵌数据库,操作步骤也非常简单,简单才好用嘛
步骤①:导入H2数据库对应的坐标,一共2个
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
步骤②:将工程设置为web工程,启动工程时启动H2数据库
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
步骤③:通过配置开启H2数据库控制台访问程序,也可以使用其他的数据库连接软件操作
spring:
h2:
console:
enabled: true
path: /h2
做完之后我们启动服务器,然后访问localhost/h2(已经提前设置端口为80),页面显示:
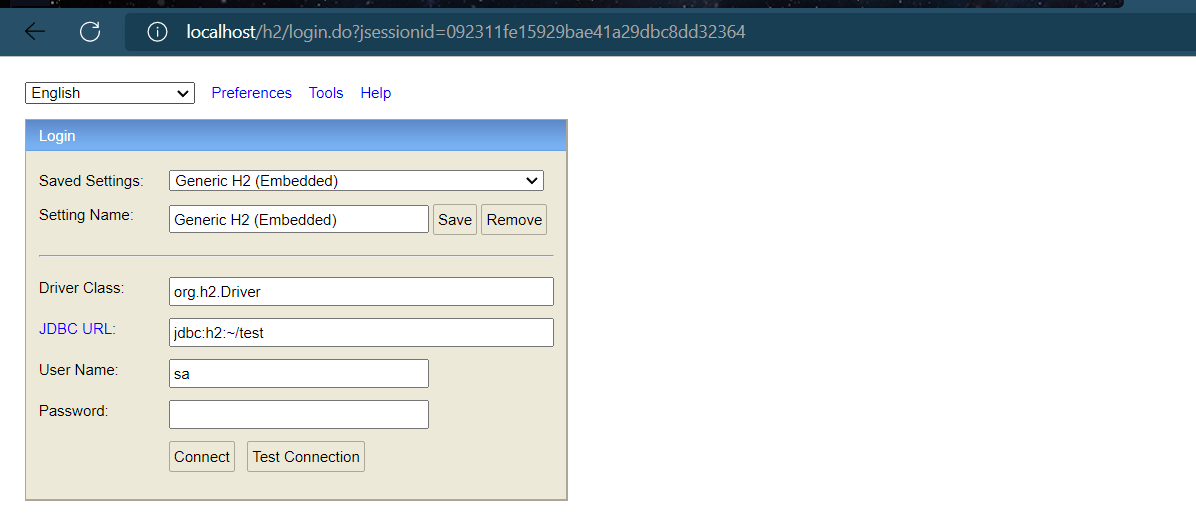
web端访问路径/h2,访问密码123456,如果访问失败,先配置下列数据源,启动程序运行后再次访问/h2路径就可以正常访问了(成功访问之后把以下内容去掉也是可以访问的)
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
然后我们就进入了如下网页:

我们可以先创建一张表:
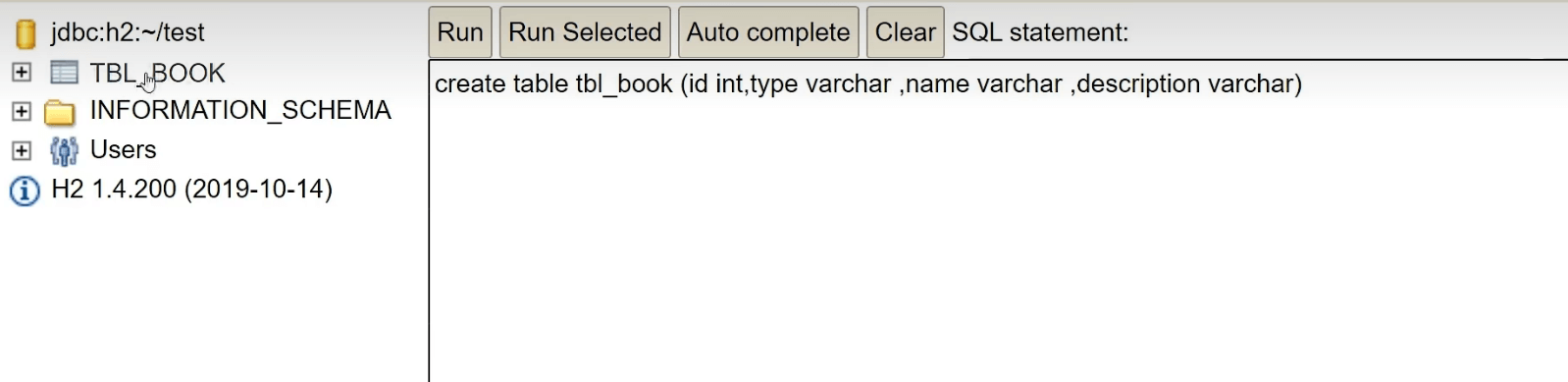
然后我们查看一下表:
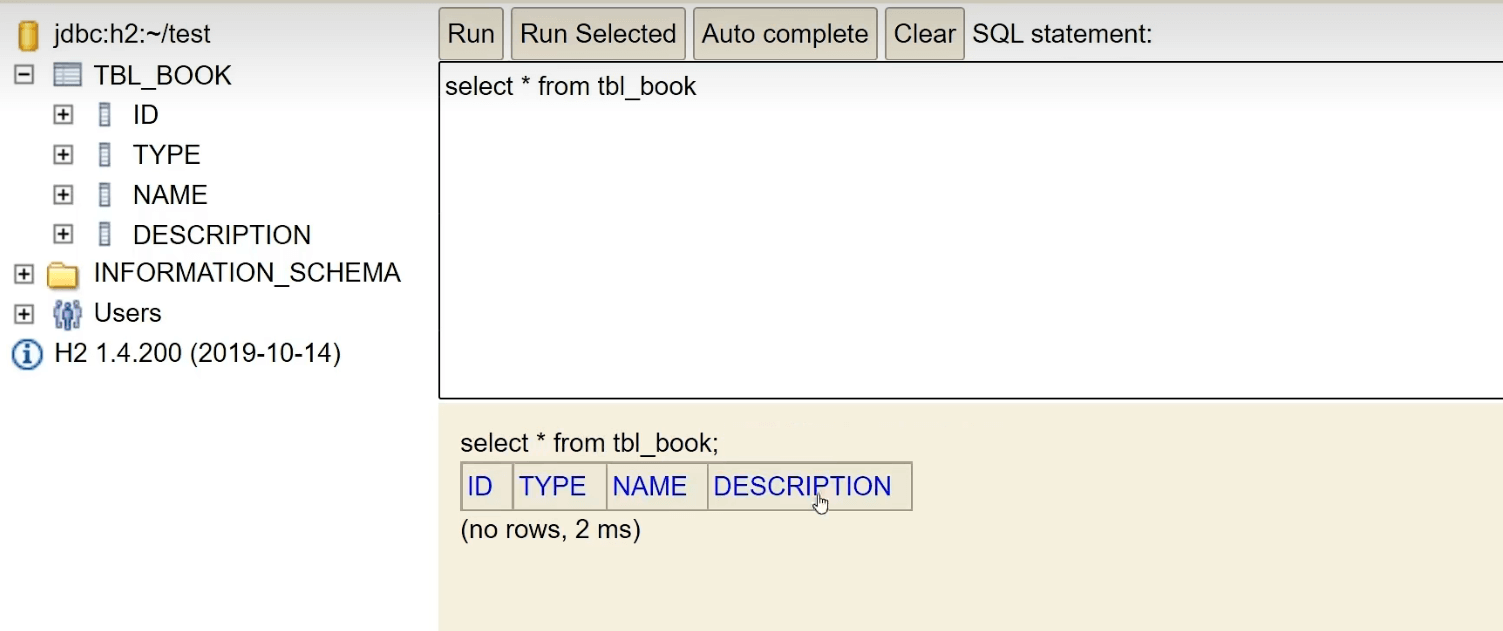
我们往里面加两条数据:
insert into tbl_book values(1,'springboot','springboot','springboot')
insert into tbl_book values(2,'springboot2','springboot2','springboot2')
我们再去查看一下表,发现数据已经成功添加了:
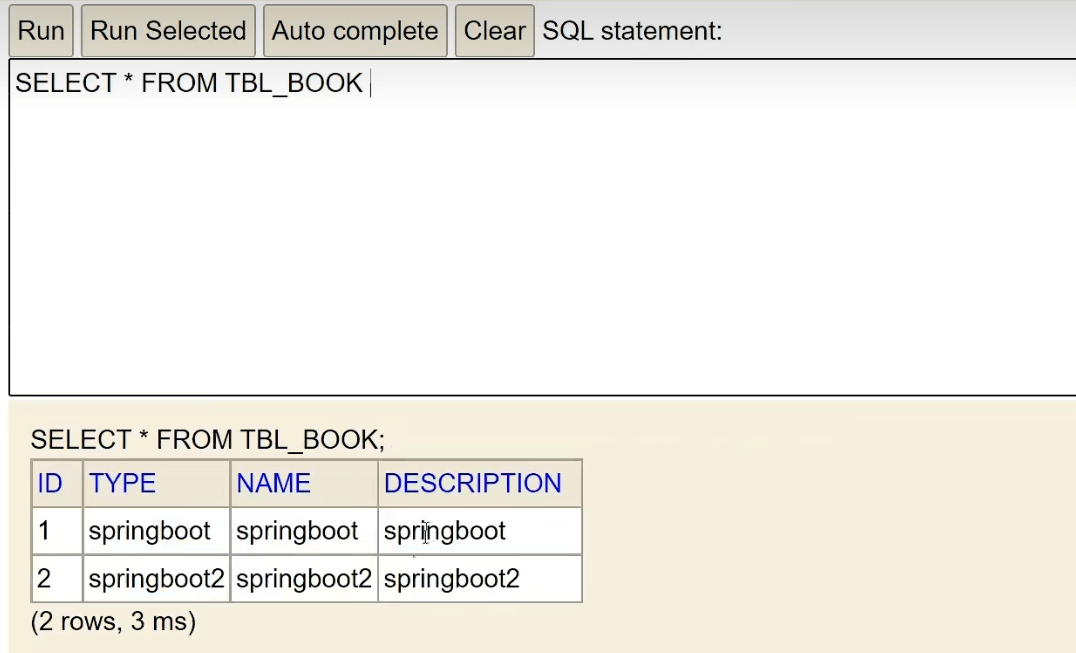
步骤④:使用JdbcTemplate或MyBatisPlus技术操作数据库
这里我们只说了JdbcTemplate,MyBatisPlus技术与以前使用方法一样。
此时数据源要写好:

数据源的配置信息我们在第一次进入h2网页的时候上面有写
我们测试一下往里面添加数据:

其实我们只是换了一个数据库而已,其他的东西都不受影响。一个重要提醒,别忘了,上线时,把内存级数据库关闭,采用MySQL数据库作为数据持久化方案,关闭方式就是设置enabled属性为false即可。

总结
- H2内嵌式数据库启动方式,添加坐标,添加配置
- H2数据库线上运行时请务必关闭
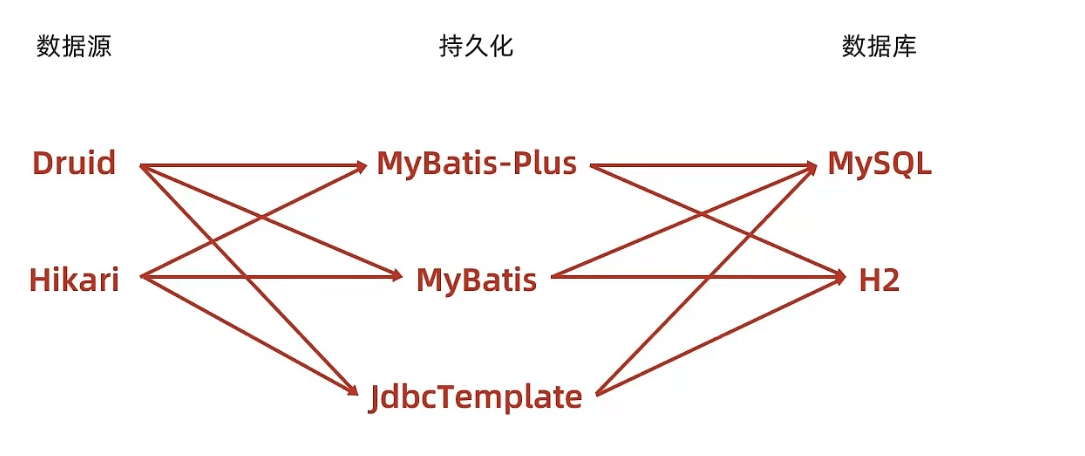
到这里SQL相关的数据层解决方案我们就说完了,现在的可选技术就丰富的多了。
- 数据源技术:Druid、Hikari、tomcat DataSource、DBCP
- 持久化技术:MyBatisPlus、MyBatis、JdbcTemplate
- 数据库技术:MySQL、H2、HSQL、Derby
现在开发程序时就可以在以上技术中任选一种组织成一套数据库解决方案了。
加载全部内容