hive表结构
q495673918 人气:0hive简介
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。 [1]
1.外部表
当文件已经存在或位于远程位置时,我们可以使用外部表,外部表的存储由自己指定。
特点:删除表,数据依然存在
建表语句
CREATE EXTERNAL TABLE tmp_xx(id int,name String);
2.内部表
hive管理控制表的整个生命周期,存储位置在hive.metastore.warehouse.dir目录下。
特点:删除表时,数据也被删除
建表语句
CREATE TABLE tmp_xx(id int,name String);
3.分区表
把一个表的数据以分区字段的值作为目录去存储。
特点:
- 缩小了硬盘扫描数据的区域,减少磁盘IO
- 将表数据存储在多个分区目录,便于独立管理(创建,删除)数据
存储结构如下

1.静态分区
在执行前就知道分区的值
- 可以根据PARTITIONED BY创建分区表,一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
- 分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
- 分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
单分区相关语法
#单分区表创建 CREATE TABLE tmp_xx(id int,name String) partitioned by (d string); #添加分区 ALTER TABLE tmp_partition ADD IF NOT EXISTS PARTITION (d='20220628') #删除分区 ALTER TABLE tmp_partition DROP IF EXISTS PARTITION (d='20220628') #数据写入 INSERT OVERWRITE TABLE tmp_xx PARTITION (d='20220629') SELECT id, name FROM tmp_yy limit 10; #查看分区数据 select * from tmp_xx where d='20220629' #查看表分区 show partitions table; #查看目录 hadoop dfs -du -h /user/hive/warehouse/tmp_xxx
多分区相关语法
#多分区表创建 CREATE TABLE tmp_xx(id int,name String) partitioned by (d String,h String); #数据写入 INSERT OVERWRITE TABLE tmp_xx PARTITION (d='20220629',h='15') SELECT id, name FROM tmp_yy limit 10; #查看分区数据 select * from tmp_xx where d='20220629' and h='15'
2.动态分区
执行时才知道分区的值,相比于静态分区可以一次写入多个分区数据,而不用在每次分区写入的时候一次执行多次insert,其他的地方和静态分区都是一样的。
官方文档:https://cwiki.apache.org/confluence/display/Hive/DynamicPartitions
特点:
- 在INSERT … SELECT …查询中,必须在SELECT语句中的列中最后指定动态分区列,并按PARTITION()子句中出现的顺序进行排列
- 如果动态分区和静态分区一起使用,必须是静态分区的字段在前,动态分区的字段在后。
想要使用动态分区需要hive开启动态分区,参数如下
set hive.exec.dynamic.partition=true; --开启动态分区 默认为false,不开启 set hive.exec.dynamic.partition.mode=nonstrict; --指定动态分区模式,默认为strict 下面参数可选 SET hive.exec.max.dynamic.partitions=2048; SET hive.exec.max.dynamic.partitions.pernode=256; SET hive.exec.max.created.files=10000; SET hive.error.on.empty.partition=true;
语法:
#写入数据 INSERT overwrite TABLE tmp_partition PARTITION(d) SELECT id,NAME,d FROM tmp_xxx #写入多分区数据 INSERT overwrite TABLE tmp_partition PARTITION(d,h) SELECT id,NAME,d,h FROM tmp_xxx #混合分区使用,使用动态分区和静态分区,静态分区必须在前 INSERT overwrite TABLE tmp_partition PARTITION(d='20220629',h) SELECT id,NAME,h FROM tmp_xxx
4.分桶表
对比分区表,分桶表是对数据进行更加细粒度的划分。一般用的比较少,在数据量比较小的时候使用分桶表可能性能更差。
分桶表将整个数据内容按照分桶字段的哈希值进行区分,使用该哈希值除以桶的个数得到取余数,bucket_id = column.hashcode % bucket.num,余数决定了该条记录会被分在哪个桶中。余数相同的记录会分在一个桶里。需要注意的是,在物理结构上,一个桶对应一个文件,而分区表只是一个目录,至于目录下有多少数据是不确定的。
分桶表和分区表的区别
| 分区表 | 分桶表 | |
| 存储结构 | 文件 | 目录/文件夹 |
| 创建语句 | partitioned by | clustered by,指定桶个数 |
| 数量 | 分区个数可增长 | 分桶数指定后不在增长 |
| 用途 | 避免扫描全表,通过分区列指定查询目录提高查询速度 | 抽样及大表join时提高效率 |
想要使用分桶表需要开启分桶机制,默认开启
set hive.enforce.bucketing=true
建表
CREATE TABLE tmp_bucket(id INT,NAME STRING) clustered BY (id) INTO 4 buckets
写入数据之后查看文件结构,发现表文件夹下有4个文件,说明分桶成功

1.抽样
#建表 select columns from table tablesample(bucket x out of y on column); -- x:表示从第几个分桶进行抽样 -- y:表示每隔几个分桶取一个分桶,y必须为表bucket的整数倍或者因子 #从分桶表的建表语句中可知,我们一共分了4个桶,所以我们这里x取1,y取2 一共抽取2(4/2)个桶,从第一个桶开始,每隔2个桶抽取一次,即第一个桶和 第三个桶。 SELECT id,NAME FROM tmp_bucket tablesample(bucket 1 OUT of 2 ON id) LIMIT 10
2.map-side join
获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。
具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
需要注意的是这种方式只适用于大表,小表不适用,表的大小至少得几个G或几个T,此功能未做测试。
5.表的文件存储格式
- STORED AS 指定表的文件存储格式默认TEXT FILE(文本文件)格式存储,
- 默认存储格式可通过hive.default.fileformat配置修改
- 其它常用存储格式 Parquet(列式),Avro,ORC(列式),Sequence File,INPUT FORMAT & OUTPUT FORMAT (二进制)
1.TEXTFILE
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
纯文本文件存储,TEXTFILE默认是hive的默认存储方式,用户可以通过配置 hive.default.fileformat 来修改。
在HDFS上可直接查看数据,可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但是使用这种方式,hive不会对数据进行切分,无法对数据进行并行操作。
存储方式:行存储
优势:可使用任意的分割符进行分割;在hdfs上可查可标记;加载速度较快;
劣势:不会对数据进行压缩处理,存储空间较大、磁盘开销大、数据解析开销大。
2.SEQUENCEFILE
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.mapred.SequenceFileOutputFormat'
存储为压缩的序列化文件。是hadoop中的标准序列化文件,可压缩,可分块。SequenceFile是一个由二进制序列化过的key/value的字节流组成的文本存储文件,它可以在map/reduce过程中的input/output 的format时被使用。
SequenceFile 有三种压缩态:
- Uncompressed – 未进行压缩的状
- record compressed - 对每一条记录的value值进行了压缩(文件头中包含上使用哪种压缩算法的信息)
- block compressed – 当数据量达到一定大小后,将停止写入进行整体压缩,整体压缩的方法是把所有的keylength,key,vlength,value 分别合在一起进行整体压缩,块的压缩效率要比记录的压缩效率高 hive中通过设置SET mapred.output.compression.type=BLOCK;来修改SequenceFile压缩方式。
存储方式:行存储
优势:存储时候会对数据进行压缩处理,存储空间小;支持文件切割分片;查询速度比TestFile速度快;
劣势:无法可视化展示数据;不可以直接使用load命令对数据进行加载;自身的压缩算法占用一定的空间
3.RCFILE
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.RCFileOutputFormat'
文件存储方式为二进制文件。以RcFile文件格式存储的表也会对数据进行压缩处理,在HDFS上以二进制格式存储,不可直接查看。
RCFILE是一种行列存储相结合的存储方式,该存储结构遵循的是“先水平划分,再垂直划分”的设计里面。首先,将数据按行分块形成行组,这样可以使同一行的数据在一个节点上。然后,把行组内的数据列式存储,将列维度的数据进行压缩,并提供了一种lazy解压技术。
Rcfile在进行数据读取时会顺序处理HDFS块中的每个行组,读取行组的元数据头部和给定查询需要的列,将其加载到内存中并进行解压,直到处理下一个行组。但是,rcfile不会解压所有的加载列,解压采用lazy解压技术,只有满足where条件的列才会被解压,减少了不必要的列解压。
在rcfile中每一个行组的大小是可变的,默认行组大小为4MB。行组变大可以提升数据的压缩效率,减少并发存储量,但是在读取数据时会占用更多的内存,可能影响查询效率和其他的并发查询。用户可根据具体机器和自身需要调整行组大小。
存储方式:行列混合的存储格式,将相近的行分块后,每块按列存储。
优势:基于列存储,压缩快且效率更高,;占用的磁盘存储空间小,读取记录时涉及的block少,IO小;查询列时,读取所需列只需读取列所在块的头部定义,读取速度快(在读取全量数据时,性能与Sequence没有明显区别);
劣势:无法可视化展示数据;导入数据时耗时较长;不能直接使用load命令对数据进行加载;自身的压缩算法占用一定空间,但比SequenceFile所占空间稍小;
4.ORC
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
ORC (Optimized Record Columnar)是RC File 的改进,主要在压缩编码、查询性能上进行了升级; ORC具备一些高级特性,如:update操作,支持ACID,支持struct、array复杂类型。Hive1.x版本后支持事务和update操作,就是基于ORC实现的(目前其他存储格式暂不支持)。
存储方式:按行组分割整个表,行组内进行列式存储。数据按行分块,每块按照列存储
文件结构:
首先做一些名词注释:
ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中包含多个stripe,每个stripe包含多条记录,这些记录按照列进行独立存储。
文件级元数据:包括文件的描述信息postscript、文件meta信息(包括整个文件的统计信息)、所有的stripe的信息和schema信息。
Stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为hdfs的块大小,保存了每一列的索引和数据。
Stripe元数据:保存stripe的位置、每个列在该stripe的统计信息以及所有的stream类型和位置。
Row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
Stream:一个stream表示文件中的一段有效的数据,包括索引和数据。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体情况由该列类型和编码方式决定。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别,他们可以根据下发的搜索参数判断是否可以跳过某些数据。在这些统计信息中包含成员数和是否有null值,且对不同类型的数据设置了特定统计信息。
ORC的文件结构如下:
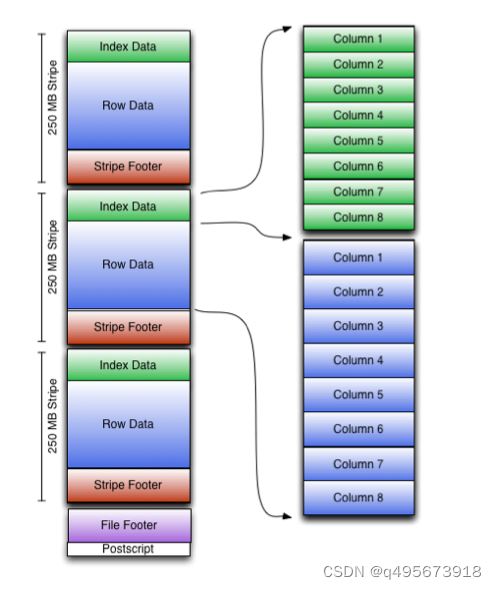
文件级别:
在ORC文件的末尾记录了文件级别的统计信息,包括整个文件的列统计信息。这些信息主要是用于查询的优化,也可以为一些简单的聚合查询如max、min、sum输出结果。
Stripe级别:
保留行级别的统计信息,用于判断该Stripe中的记录是否符合where中的条件,是否需要被读取。
Row group级别:
进一步避免读取不必要的数据,在逻辑上将一个column的index分割成多个index组(默认为10000,可配置)。以这些index记录为一个组,对数据进行统计。在查询时可根据组级别的统计信息过滤掉不必要的数据。
优势:具有很高的压缩比,且可切分;由于压缩比高,在查询时输入的数据量小,使用的task减少,所以提升了数据查询速度和处理性能;每个task只输出单个文件,减少了namenode的负载压力;在ORC文件中会对每一个字段建立一个轻量级的索引,如:row group index、bloom filter index等,可以用于where条件过滤;可使用load命令加载,但加载后select * from xx;无法读取数据;查询速度比rcfile快;支持复杂的数据类型;
劣势:无法可视化展示数据;读写时需要消耗额外的CPU资源用于压缩和解压缩,但消耗较少;对schema演化支持较差;
5.Parquet
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
Parquet 最初的设计动机是存储嵌套式数据,,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据。总的来说Parquet与orc相比的主要优势是对嵌套结构的支持,orc的多层级嵌套表达复杂底层未采用google dremel类似实现,性能和空间损失较大。
存储方式:列式存储
优势:具有高效压缩和编码,是使用时有更少的IO取出所需数据,速度比ORC快;其他方面类似于ORC;
劣势:不支持update;不支持ACID;不支持可视化展示数据
| ORC | Parquet | |
| 存储方式 | 列存储 | 列存储 |
| 嵌套式结构 | orc的多层级嵌套表达复杂且底层未采用google dremel类似实现,性能和空间损失较大 | 支持比较完美 |
| ACID | 支持 | 不支持 |
| update操作 | 支持 | 不支持 |
| 索引 | 粗粒度索引,block/group/chuck级别统计信息 | 粗粒度索引,file/stripe/row级别统计信息,不能精确到列建索引。 |
| 查询性能 | 比parquet稍高 | 比ORC稍低 |
| 压缩 | 高 | 低 |
6.总结
需要查看到所存储的具体数据内容的小型查询,可以采用默认文件格式textfile。不需要查看具体数据的小型查询时可使用sequencefile文件格式。当用于大数据量的查询时,可以使用rcfile、ORC、parquet,一般情况下推荐使用ORC,若字段数较多,不涉及到更新且取部分列查询场景多的情况下建议使用parquet。
需要通过sqoop+hive与关系型数据库交互时,import和export的hive表需要是textfile格式。如果需要操作的表不是此存储格式,需要insert到textfile格式的表中再操作。
一、ORC与Parquet总结对比 1、orc不支持嵌套结构(但可通过复杂数据类型如map<k,v>间接实现),parquet支持嵌套结构 2、orc与hive的兼容性强,作为hive的常用存储格式 3、orc相比parquet的存储压缩率较高,如下图 4、orc导入数据和数据查询的的速度比parquet快

5.表的行存储格式(row format)
ROW FORMAT:控制文件数据和hive表中Row数据的转换,有DELIMITED和SERDE两种值,可以将ROW FORMAT看做FileFormat的功能支持或实现,我们设置了FileFormat后,底层数据格式的转换是依赖SerDe来做的。
DELIMITED:表示使用默认的LazySimpleSerDe类来处理数据,一般用于用分隔符分隔的文本文,默认使用native Serde
SERDE:Serde是 Serializer/Deserializer的简写。hive使用Serde进行行对象的序列与反序列化。Hive使用SerDe读取和写入行对象。读取就是hdfs文件反序列化成对象,写入就是对象序列化存储hdfs
read:HDFS files --> InputFileFormat --> <key, value> --> Deserializer --> Row object write: row object --> Serializer --> <key, value> --> OutputFileFormat --> HDFS files
一般用于比较复杂格式的文本文件,比如JSON格式行、正则表达式可以匹配出的行,像访问日志。
6.表属性
1.压缩
1.为什么要压缩
可以提高吞吐量和性能,大量减少磁盘存储空间。同时压缩也会减少文件在磁盘间的传输及IO消耗,但是压缩和截压缩会带来额外的CPU开销,但是可以节省更多的IO消耗和内存使用。
2.压缩常见的格式
| 压缩方式 | 压缩后大小 | 压缩速度 | 是否可切分 |
| GZIP | 中 | 中 | 否 |
| BZIP2 | 小 | 慢 | 是 |
| LZO | 大 | 快 | 是 |
| Snappy | 大 | 快 | 否 |
3.压缩性能比较
压缩算法 原始文件大小 压缩文件大小 压缩速度 解压速度
gzip 8.3GB 1.8GB 17.5MB/S 58MB/S
bzip2 8.3GB 1.1GB 2.4MB/S 9.5MB/S
lzo 8.3GB 2.9GB 49.3MB/S 74.6MB/S
tblproperties ('orc.compress'='snappy')
tblproperties ('parquet.compression'='snappy');3)开启MAP输出阶段压缩 (1)开启hive中间传输数据压缩功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)开启mapreduce中map输出压缩功能
hive (default)>set mapreduce.map.output.compress=true;
(3)设置mapreduce中map输出数据的压缩方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
4)开启REDUCE输出阶段压缩,比map端压缩事儿多 (1)开启hive最终输出数据压缩功能
hive (default)>set hive.exec.compress.output=true;
(2)开启mapreduce最终输出数据压缩
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)设置mapreduce最终数据输出压缩方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
(4)设置mapreduce最终数据输出压缩为块压缩
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
在生产环境中,常用的HIVE存储格式:列式存储的orc和parquet
HIVE压缩格式:冷数据-----gzip压缩(压缩比高,压缩解压缩速度高,不可切割);
非冷数据------lzo(可切割)和snappy(不可切割)
LZO支持切片,Snappy不支持切片。 ORC和Parquet都是列式存储。 ORC和Parquet 两种存储格式都是不能直接读取的,一般与压缩一起使用,可大大节省磁盘空间。 选择:ORC文件支持Snappy压缩,但不支持lzo压缩,所以在实际生产中,使用Parquet存储 + lzo压缩的方式更为常见,这种情况下可以避免由于读取不可分割大文件引发的数据倾斜。 但是,如果数据量并不大(预测不会有超大文件,若干G以上)的情况下,使用ORC存储,snappy压缩的效率还是非常高的。
ORC支持三种压缩:ZLIB,SNAPPY,NONE。最后一种就是不压缩,orc默认采用的是ZLIB压缩。
Parquet支持的压缩:UNCOMPRESSED、 SNAPPY、GZP和LZO,默认UNCOMPRESSED不压缩
加载全部内容