Python整理重复文件
Mr数据杨 人气:0有没有头疼过百度云盘都要塞满了,可是又没有工具能剔除大量重复无用的文件?这里教你一个简单的方法,通过整理目录的方式来处理我们云盘中无用的文件吧。

获取云盘缓存目录
使用 Everything 找到云盘缓存 db 文件,复制到脚本的目录下。

云盘数据整理
我们发现这个是一个 sqlite3 的文件,用 Navicat 打开先看看。
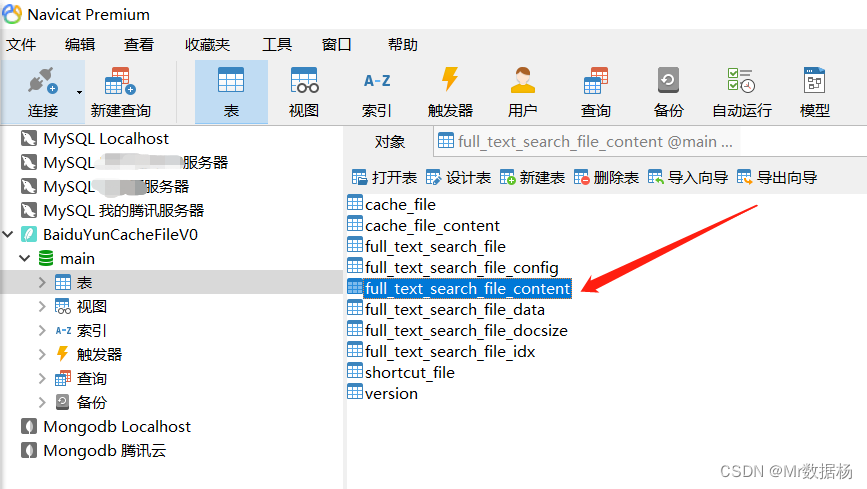
我们所有云盘的文件以及对应的路径保存在 cache_file 中,直接导出可能会有些问题,所以我们用 pandas 来处理数据就可以了。
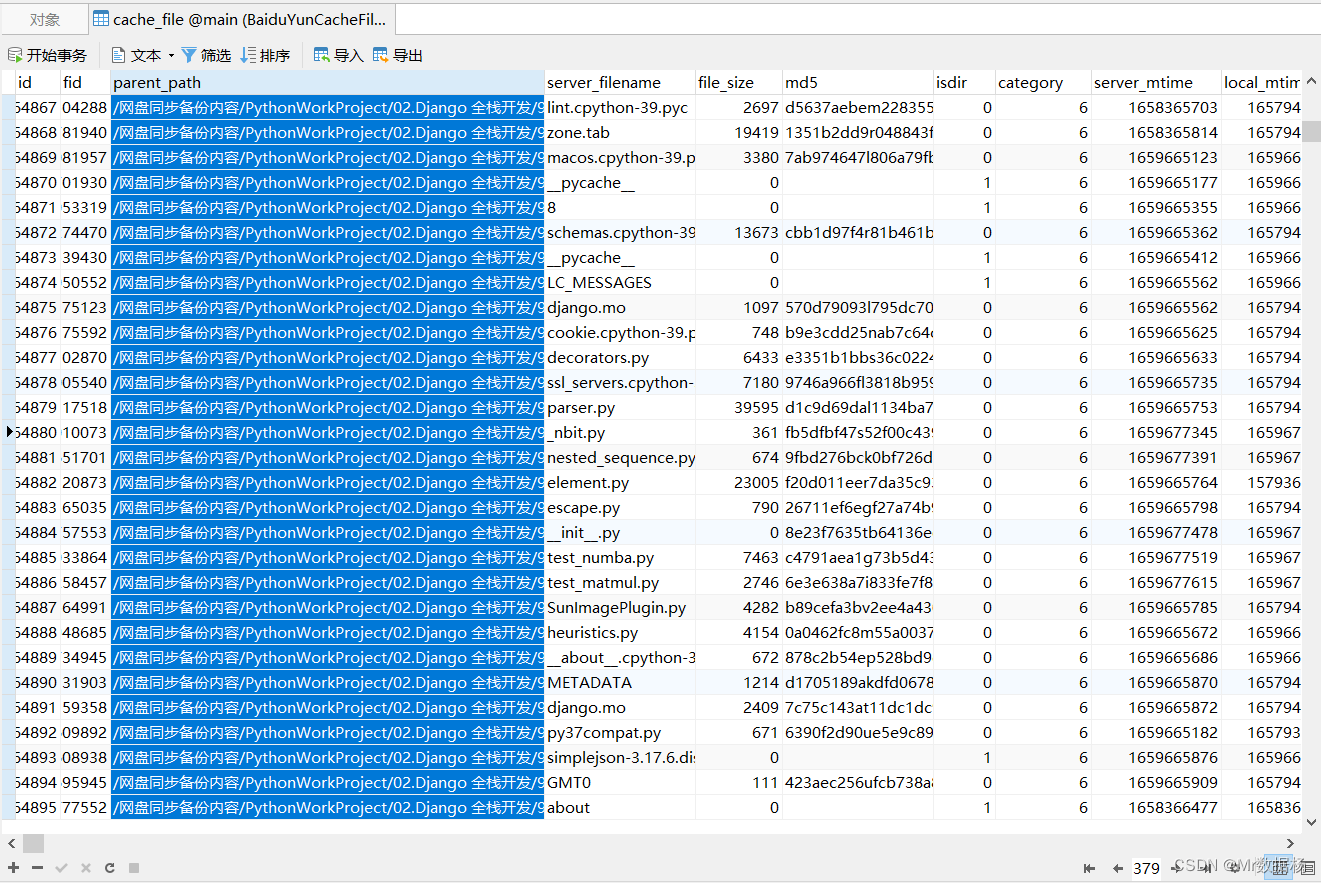
云盘数据导出
我的云盘导出来了 40MB 的目录数据,看着都头疼。
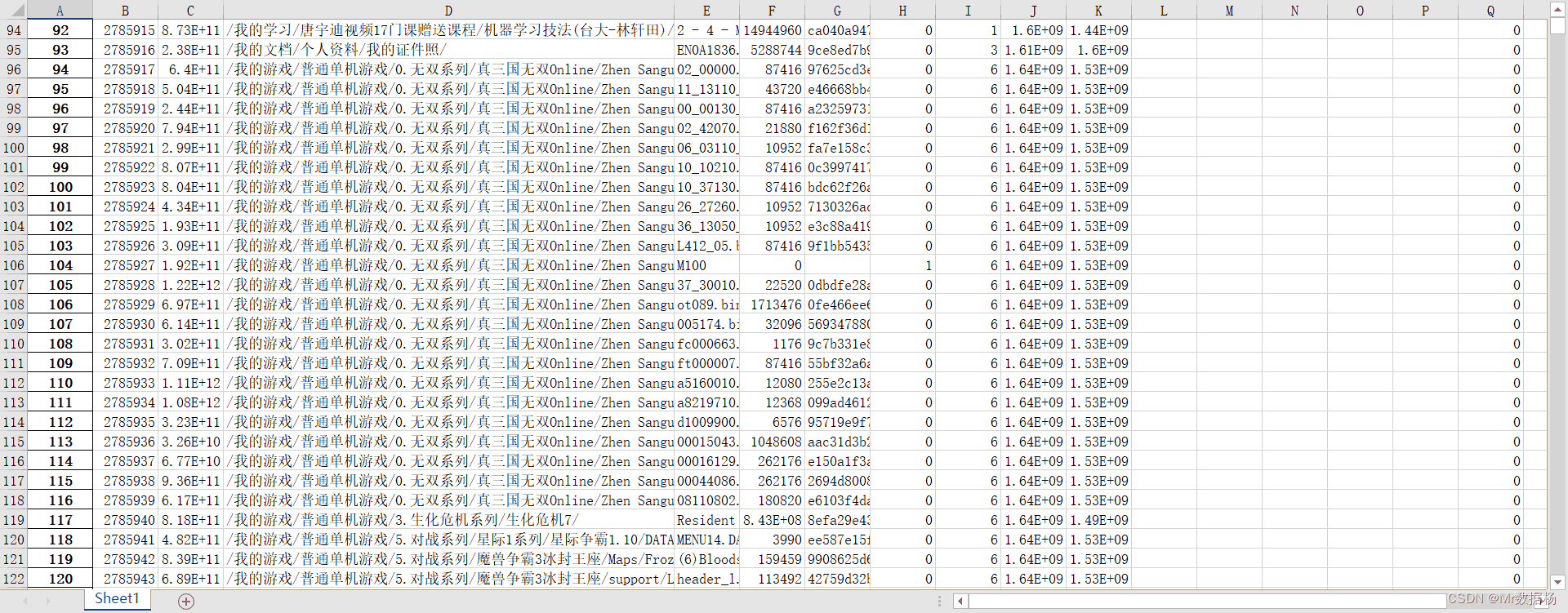
数据整理
把云盘的目录数据导出到 excel,后去该怎么处理就怎么处理吧。代码非常少,如果喜欢用 python 处理就用 pandas 处理,如果感觉有困难直接在 excel 中处理就可以了。
import sqlite3
import pandas as pd
file_dict = {}
con = sqlite3.connect('BaiduYunCacheFileV0.db')
cursor = con.cursor()
cursor.execute("select * from cache_file")
values = cursor.fetchall()
df = pd.DataFrame(values,columns=["id","fid","parent_path","server_filename","file_size","md5","isdir","category","server_mtime","local_mtime","reserved1","reserved2","reserved3","reserved4","reserved5","reserved6","reserved7","reserved8","reserved9"])
df.to_excel("data.xlsx")
重复文件提取
这个由于百度云盘没有对应的API接口可以使用爬虫的方式进行网页的操作对重复数据进行删除,但是容易误操作,所以还是手动把要处理的数据整理出来然后进行操作把。
通过文件名称判断重复,有了结果后续自己处理就好了。
df["server_filename"].duplicated()
0 False
1 False
2 False
3 False
4 False
...
379563 False
379564 False
379565 True
379566 True
379567 False
Name: server_filename, Length: 379568, dtype: bool
df[df["server_filename"].duplicated()]["server_filename"]
188 WE_rk_nos06.txt
252 django.po
254 django.po
255 django.po
256 django.po
...
378517 video.mp4
378518 top_level.txt
378543 Blog_articleinfo.xlsx
379565 apps
379566 职业培训规划.mmap
Name: server_filename, Length: 152409, dtype: object
加载全部内容