Python re.findall()用法
IT之一小佬 人气:0在python中,通过内嵌集成re模块,程序媛们可以直接调用来实现正则匹配。本文重点给大家介绍python中正则表达式 re.findall 用法
re.findall():函数返回包含所有匹配项的列表。返回string中所有与pattern相匹配的全部字串,返回形式为数组。
示例代码1:【打印所有的匹配项】
import re
s = "Long live the people's Republic of China"
ret = re.findall('h', s)
print(ret)运行结果:

示例代码2:【如果未找到匹配项,返回空列表】
import re
s = "Long live the people's Republic of China"
ret = re.findall('USA', s)
print(ret)运行结果:

示例代码:
import re s = "https://blog.csdn.net/weixin_44799217" ret = re.findall(r"^http", s) print(ret) ret2 = re.findall(r"[t,b,s]", s) # 匹配括号中的其中一个字符 print(ret2) ret3 = re.findall(r"\d\d\d", s) print(ret3) ret4 = re.findall(r"\d", s) print(ret4) ret5 = re.findall(r"[^\d]", s) # 取非 print(ret5) ret6 = re.findall(r"[^https://]", s) # 取非 print(ret6)
运行结果:
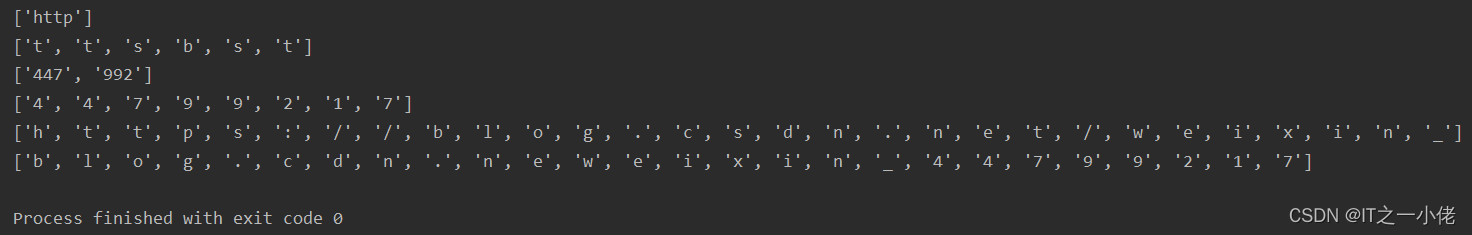
获取网站中的title:
import requests import re url = 'http://pz.wendu.com/' response = requests.get(url) data = response.text # print(data) res = re.findall(r'<title>(.*?)</title>', data)[0] print(res)
运行效果:

加载全部内容