Java8 分组
诗水人间 人气:0在SQL中经常会用到分组,我们也常常遇到一些组合分组的场景。
有下面的一个User类
import lombok.Builder;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@Builder
public class User {
private String name;
private int id;
private String city;
private String sex;
private LocalDateTime birthDay;
}
java8分组 传统写法(单个字段分组)
场景:根据 城市 进行分组
使用的是方法引用:User::getCity 来完成分组
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Demo2 {
public static void main(String[] args) {
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// data list
List<User> userList = Arrays.asList(
User.builder().id(123456).name("Zhang, San").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(777777).name("Zhang, San").city("ShangHai").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(888888).name("Li, Si").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(999999).name("Zhan, San").city("HangZhou").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(555555).name("Li, Si").city("NaJin").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build()
);
Map<String, List<User>> groupMap = userList.stream()
.collect(Collectors.groupingBy(User::getCity));
groupMap.forEach((k, v) -> {
System.out.println(k);
System.out.println(v);
});
}
}
java8分组 传统写法(多个字段分组)
① 场景:根据 城市,性别进行分组
一般的写法会是下面的这种写法,通过lambda表达式将key的生成逻辑传入进去:u -> u.getCity() + "|" + u.getSex() 来实现分组的效果。
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Demo2 {
public static void main(String[] args) {
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// data list
List<User> userList = Arrays.asList(
User.builder().id(123456).name("Zhang, San").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(777777).name("Zhang, San").city("ShangHai").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(888888).name("Li, Si").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(999999).name("Zhan, San").city("HangZhou").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(555555).name("Li, Si").city("NaJin").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build()
);
Map<String, List<User>> groupMap = userList.stream()
.collect(Collectors.groupingBy(u -> u.getCity() + "|" + u.getSex()));
groupMap.forEach((k, v) -> {
System.out.println(k);
System.out.println(v);
});
}
}
分析:多个分组条件 与 单个分组条件 两种写法
单个条件的分组用的比较多,userList.stream().collect(Collectors.groupingBy(User::getCity));
这种方法引用的方式看起来很清爽。
在我们遇到多个字段的分组的时候,我并不太想使用前面那种传统的写法①。
我在想,既然单个字段的分组写法是:
userList.stream().collect(Collectors.groupingBy(User::getCity));
那么多个字段的写法可否是下面这种( 类推 ),传入多个方法引用!
userList.stream().collect(Collectors.groupingBy(User::getCity,User::getSex));
很可惜 jdk 类库中Collectors 没有提供这种写法
多个字段的优雅写法
因为jdk没有提供这种写法,于是自己就想写了一个Util来帮助我们使用多个方法引用的方式完成组合分组
MyBeanUtil groupingBy(userList, User::getSex, User::getCity);
Demo:
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
import java.util.function.Function;
import java.util.stream.Collectors;
public class MyBeanUtil {
public static void main(String[] args) {
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// data list
List<User> userList = Arrays.asList(
User.builder().id(123456).name("Zhang, San").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(777777).name("Zhang, San").city("ShangHai").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(888888).name("Li, Si").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(999999).name("Zhan, San").city("HangZhou").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(555555).name("Li, Si").city("NaJin").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build()
);
// 进行分组,根据名字和城市分组
Map<String, List<User>> groupMap = groupingBy(userList, User::getSex, User::getCity);
//打印分组结果
groupMap.forEach((k, v) -> {
System.out.println(k);
System.out.println(v);
});
}
/**
* 将数据分组,根据方法引用(bean的get方法)
*
* @param list 为分组的数据
* @param functions get方法数组
*/
@SafeVarargs
public static <T, R> Map<String, List<T>> groupingBy(List<T> list, Function<T, R>... functions) {
return list.stream().collect(Collectors.groupingBy(t -> groupingBy(t, functions)));
}
/**
* 分组工具根据函数式接口使用分组,将数据根据分组结果进行拆分
*/
@SafeVarargs
public static <T, R> String groupingBy(T t, Function<T, R>... functions) {
if (functions == null || functions.length == 0) {
throw new NullPointerException("functions数组不可以为空");
} else if (functions.length == 1) {
return functions[0].apply(t).toString();
} else {
return Arrays.stream(functions).map(fun -> fun.apply(t).toString()).reduce((str1, str2) -> str1 + "|" + str2).get();
}
}
}
再度优化
依然不是很满足这种写法,因为这种写法需要借助 Util 类,不够接地气!
我更希望是下面这种接地气的写法:能够完全集成在jdk类库中
userList.stream().collect(Collectors.groupingBy(User::getCity,User::getSex));
为了达到上述的效果,那么显然我们是需要修改jdk源代码的;
于是我就将java.util.stream.Collectors源码完整copy出来,然后加入下面3个方法
public static <T, K> Collector<T, ?, HashMap<K, List<T>>>
groupingBy(Function<? super T, ? extends K>... classifier) {
return groupingBy("|", classifier);
}
public static <T, K> Collector<T, ?, HashMap<K, List<T>>>
groupingBy(String split, Function<? super T, ? extends K>... classifier) {
return groupingBy(split, classifier, HashMap::new, toList());
}
public static <T, K, D, A, M extends Map<? super K, D>>
Collector<T, ?, M> groupingBy(String split,
Function<? super T, ? extends K>[] classifierArr,
Supplier<M> mapFactory,
Collector<? super T, A, D> downstream) {
Supplier<A> downstreamSupplier = downstream.supplier();
BiConsumer<A, ? super T> downstreamAccumulator = downstream.accumulator();
BiConsumer<Map<K, A>, T> accumulator = (m, t) -> {
String key = Arrays.stream(classifierArr).map(classifier -> Objects.requireNonNull(classifier.apply(t))).map(String::valueOf).reduce((s1, s2) -> s1 + split + s2).get();
A container = m.computeIfAbsent((K) key, k -> downstreamSupplier.get());
downstreamAccumulator.accept(container, t);
};
BinaryOperator<Map<K, A>> merger = Collectors.<K, A, Map<K, A>>mapMerger(downstream.combiner());
@SuppressWarnings("unchecked")
Supplier<Map<K, A>> mangledFactory = (Supplier<Map<K, A>>) mapFactory;
if (downstream.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)) {
return new CollectorImpl<>(mangledFactory, accumulator, merger, CH_ID);
} else {
@SuppressWarnings("unchecked")
Function<A, A> downstreamFinisher = (Function<A, A>) downstream.finisher();
Function<Map<K, A>, M> finisher = intermediate -> {
intermediate.replaceAll((k, v) -> downstreamFinisher.apply(v));
@SuppressWarnings("unchecked")
M castResult = (M) intermediate;
return castResult;
};
return new CollectorImpl<>(mangledFactory, accumulator, merger, finisher, CH_NOID);
}
}
就达到了我们预期的效果,为了方便大家也一起体验一下,我已经将demo完整的放到了github上
源码地址:https://github.com/1015770492/CollectorsDemo
下载好源码后,找到下面这个类
Demo:
import java.io.Serializable;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
public class MultiGroupByDemo {
public static void main(String[] args) {
DateTimeFormatter df = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
// data list
List<User> userList = Arrays.asList(
User.builder().id(123456).name("Zhang, San").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(777777).name("Zhang, San").city("ShangHai").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(888888).name("Li, Si").city("ShangHai").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(999999).name("Zhan, San").city("HangZhou").sex("woman").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build(),
User.builder().id(555555).name("Li, Si").city("NaJin").sex("man").birthDay(LocalDateTime.parse("2022-07-01 12:00:00", df)).build()
);
/*
* maybe we can
*/
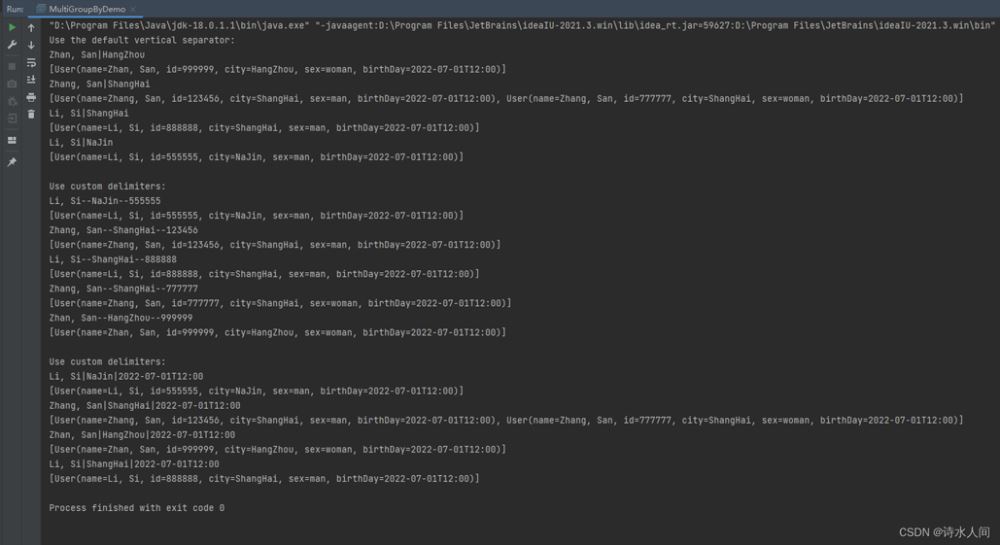
// 1.Use the default vertical separator
System.out.println("Use the default vertical separator:");
HashMap<String, List<User>> defaultSpilt = userList.stream().collect(Collectors.groupingBy(User::getName, User::getCity));
printMap(defaultSpilt);
System.out.println();
// 2.Use custom delimiters
System.out.println("Use custom delimiters:");
userList.stream().collect(Collectors.groupingBy("--", User::getName, User::getCity, User::getId));
HashMap<? extends Serializable, List<User>> collect = userList.stream().collect(Collectors.groupingBy("--", User::getName, User::getCity, User::getId));
printMap(collect);
System.out.println();
// 3.Use custom delimiters
System.out.println("Use custom delimiters:");
userList.stream().collect(Collectors.groupingBy("--", User::getName, User::getCity, User::getId));
HashMap<? extends Serializable, List<User>> collect2 = userList.stream().collect(Collectors.groupingBy(User::getName, User::getCity, User::getBirthDay));
printMap(collect2);
}
public static <T> void printMap(Map<? extends Serializable, List<T>> map){
map.forEach((k, v) -> {
System.out.println(k);
System.out.println(v);
});
}
}
最后我希望这个特性能被JDK所吸收,这样可以方便大家更好的使用这些好用的特性
加载全部内容