小程序 excel批量导入
低代码布道师 人气:0我们上一篇介绍了如何利用微搭的自定义连接器接入腾讯文档的数据,光有接入是不够的,更重要的是我们需要将采集的数据积累下来,变成企业的数字资产。
积累数据最好的方式就是把数据存入数据库,低码工具除了有可视化编程的便利外,还提供了线上的文档型数据库。文档数据库比传统数据库的优势是,文档数据库的返回结构是JSON格式,直接就可以在前端进行渲染。关系型数据库还得通过代码进行转译。
另外一个方面是文档数据库的类型更丰富,有附件、富文本、自动编号、数组、对象、图片、地理位置这些偏业务类型的字段。有了这些丰富多彩的字段,那我们就可以减少代码的编制,无疑对提高编程效率非常有帮助。
介绍了一些基础背景后我们开始介绍如何将腾讯文档的数据批量入库。
1 建立数据源
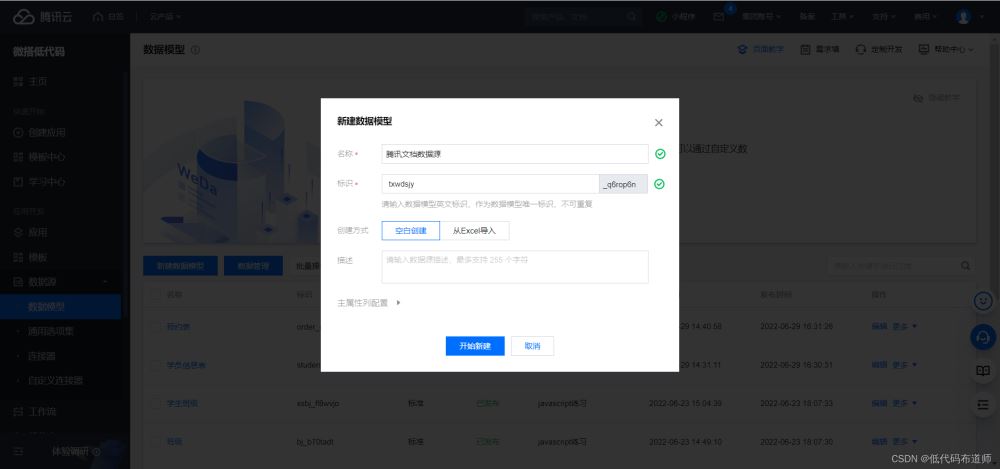
要想将数据入库,就先需要建立数据源。登录微搭控制台,点击数据源,点击新建数据模型

输入名称和标识
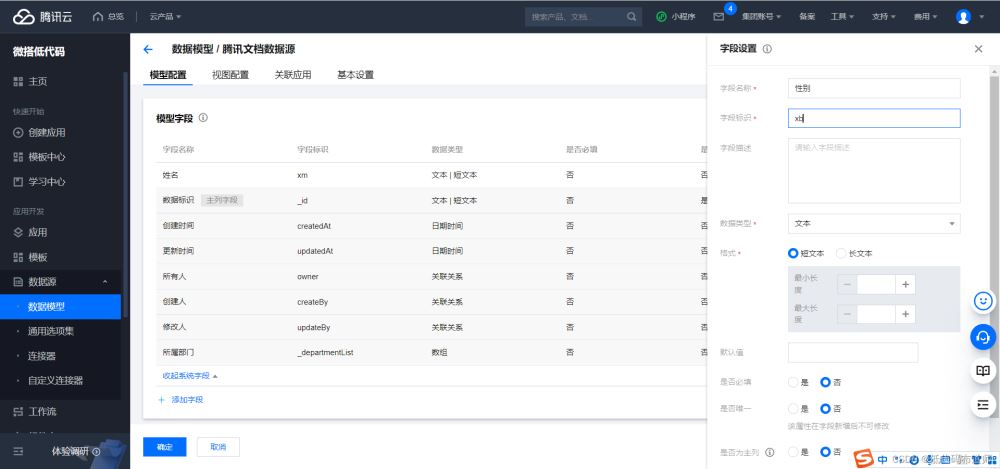
数据源建立之后需要创建字段,点击添加字段

初学者最大的疑问是我需要建哪些字段,字段是个什么概念?我们还是先看一下我们的腾讯文档的在线表格
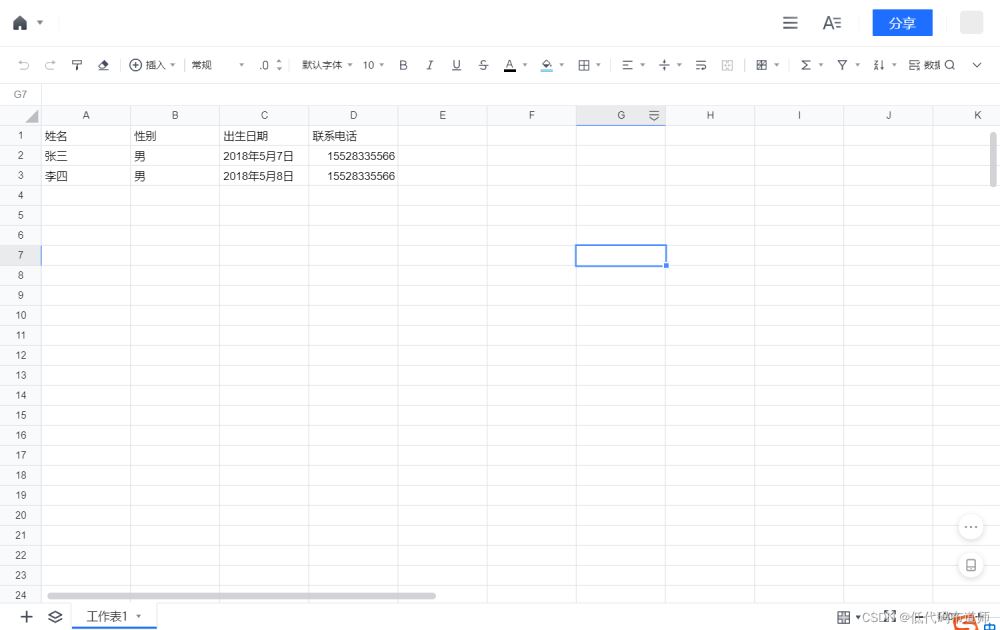
会用excel的人都知道,excel里有行和列的概念。那我们的字段其实是列,每一列都对应一个字段。字段的类型其实是和单元格的内容是相关的。比如我的A2单元格是张三,明显是存的字符,那么我们的类型就是文本。C2是出生日期,应该是日期类型。D2是联系电话,可以选择文本也可以选择电话类型。
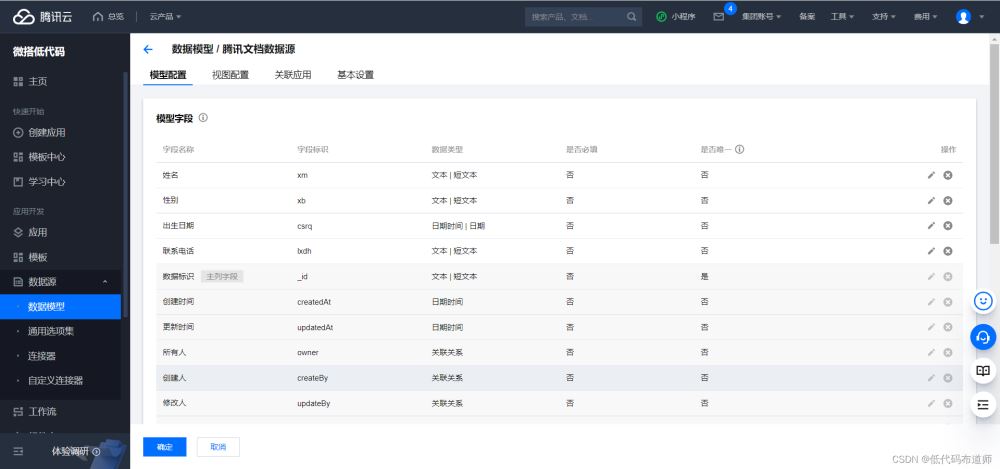
明白了这个基础概念之后,我们分别添加一下字段,一共是四个字段,姓名、性别、出生日期、联系电话


2 编制入库的代码
我们上一节介绍了如何创建连接器来对接腾讯文档,不会的同学可以翻看上一篇文章添加腾讯文档连接器
读取腾讯文档的数据分为读取sheet,根据sheet获取每一行的数据。因为是入库,还需要将解析好的数据封装到对象中,调用批量新增的方法入库。我们来一步步讲解一下。
2.1 创建低码方法
要想入库,先需要创建一个低码方法。点击左上角的低码编辑器进入到代码界面
低码编辑器打开之后会定位到当前页面,在handler旁边点击+号来创建低码方法
首先需要输入一个方法名,方法名最好能望文知义,我们可以定义一个batchAdd方法
平台会自动生成代码结构

初学者因为没有系统的学习过编程,往往容易犯的错误是自由发挥,随意编制代码。我们讲解一下这里的知识点。一般我们在handler里定义的方法叫函数,函数由几部分组成,函数名、入参、出参(或者叫返回值)
export default function 是函数的定义,这里叫匿名函数,就是不给函数起一个名字。如果函数体里写了await了,这个函数需要改写成异步函数,变成 export default async function
小括号里边的叫入参,多个参数以逗号分隔。我们这里其实只有一个入参,是{event,data}。用一对儿大括号包裹的叫对象,对象里是具体的入参。
event是事件对象,一般我们可以获取到组件里的值,data是如果调用事件传参了,可以直接从data里获取值。具体如果希望看到值的我们可以使用打桩的技术,所谓的打桩就是在控制台输出具体的值。
比如我们可以这样写
export default function({event, data}) {
console.log(event,data)
}
打好桩之后,如何看结果呢?事件必须绑定到组件上,组件产生的各种的动作可以触发事件。就像我们这个批量入库,需要用户主动触发,就需要放置一个按钮,并且绑定点击事件,来触发批量新增的方法。
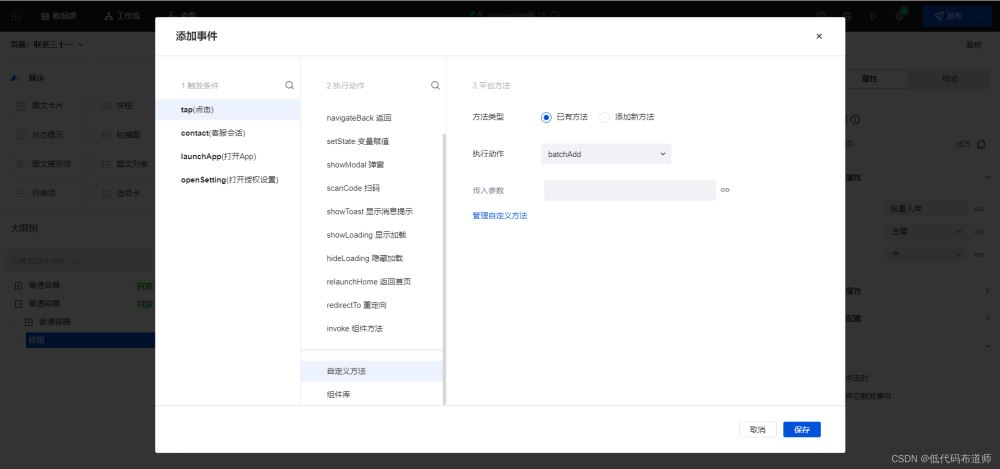

事件绑定好之后在哪看结果呢?点击开发调试工具来看具体的输出
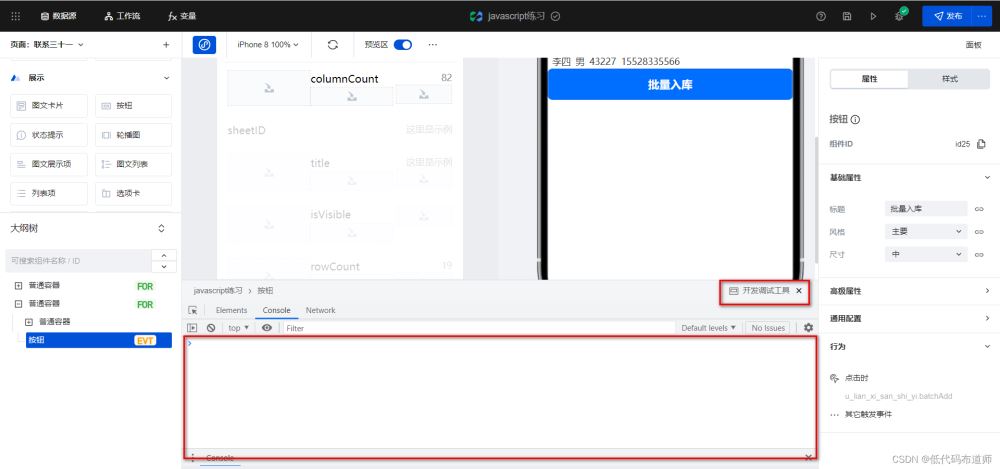
这时候点击一下按钮就可以看到对应的输出

输出的结果还是蛮复杂的,不同的组件产生的事件对象不同,里边的内容不同,我们会在具体的场景进行深入的讲解。为啥本篇会先讲一些基础操作呢?因为不少粉丝是按照教程的步骤一步步操作的,不懂基本的操作有时候会乱粘贴一气,然后就是各种各样的报错,还不知道从哪看错误,浪费了不少时间。
2.2 低码中调用连接器
我们上一篇是使用变量的方法调用了连接器,这一篇我们使用低码方法调用连接器。为了获取腾讯文档中的数据,先需要获取工作表的信息。我们复习一下变量中我们是如何调用的

这里是调用了getSheets方法,并且传入了bookID,低码中是通过api的方式来调用的,在方法中输入如下代码
const bookID = "DWkxMSFlkU1l2YkRo";
const { sheetData } = await app.cloud.callConnector({
name: 'txwd_jnegl1q',
methodName: 'getSheets',
params: {
bookID,
},
});
console.log(sheetData)
这里的bookID是通过腾讯文档分享链接的时候获取到的,{sheetData}是解构赋值的意思,可以直接从返回结果里获取对应的值。可以看一下控制台打印的结果

要怎么看返回结果呢,一对儿中括号表示数组的意思,展开数组第一个元素的下标是0,数组里的元素是个对象,对象是以一对儿大括号表示的,对象里边又有具体的属性和方法。我们这里边需要的是sheetID,cloumnCount,rowCount。
了解了之后我们就定义变量来接收返回值,输入如下代码
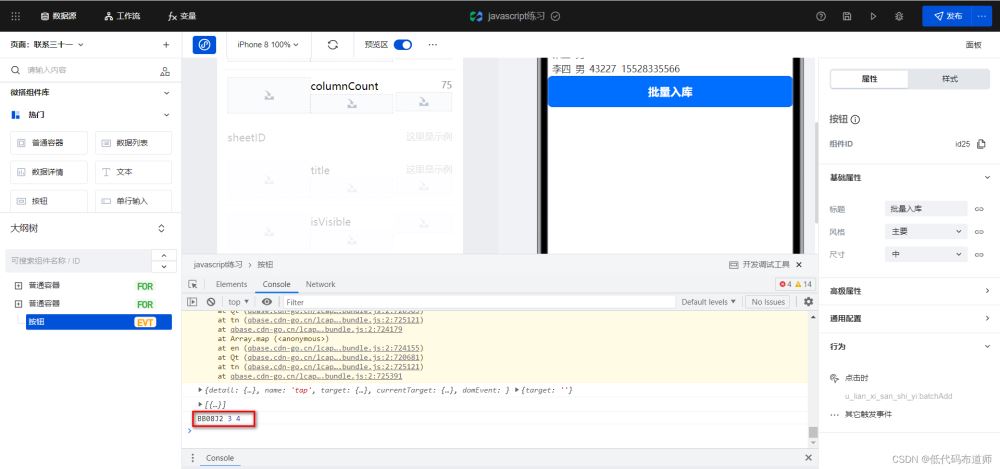
let sheetID = sheetData[0].sheetID let rowCount = sheetData[0].rowCount let columnCount = sheetData[0].columnCount console.log(sheetID, rowCount, columnCount)
看控制台的打印结果
接着我们就需要根据返回的结果调用获取单元格的方法,我们使用变量的时候是这么做的
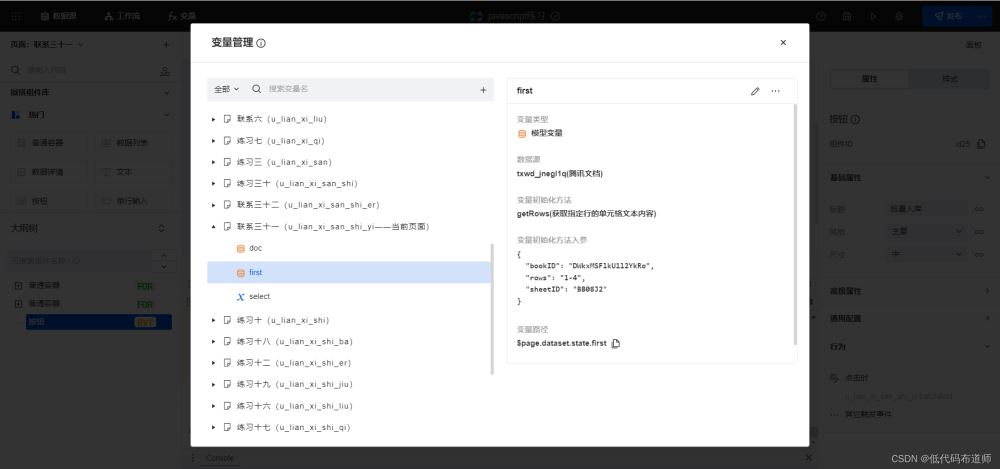
代码中是这样获取
const { rows } = await app.cloud.callConnector({
name: 'txwd_jnegl1q',
methodName: 'getRows',
params: {
bookID,
sheetID,
rows: `2-${rowCount}`
},
});
console.log(rows)
这里小伙伴不明白的就是这一句2-${rowCount},用两个反引号包裹的表示模板字符串,里边如果使用${}这种语法的表示变量,代码只要一执行就会翻译成2-3,读取第二行、第三行的数据。我们看一下输出的结果

textTypes表示每一列的字段类型,textValues表示具体的值。字段类型我们不需要,只需要解析出具体的值就可以
这样每行的数据也解析出来了,就需要按照需要的格式整理入库了,下边是入库的代码
const newRecords = [];
const columns = "xm|xb|csrq|lxdh";
for(let r = 0; r < rowCount - 1; r++) {
const { textValues } = rows[r];
const inputParams = {};
const cols = columns.split('|');
cols.forEach((c, i) => {
inputParams[c] = textValues[i];
});
newRecords.push(inputParams);
}
await app.cloud.callModel({
name: 'txwdsjy_q6rop6n', // 数据模型标识
methodName: 'wedaBatchCreate', // 新增多条的方法标识
params: {
records: newRecords,
},
});
这里columns是内数据源的每一个字段的字段标识,可以去数据源那块找到
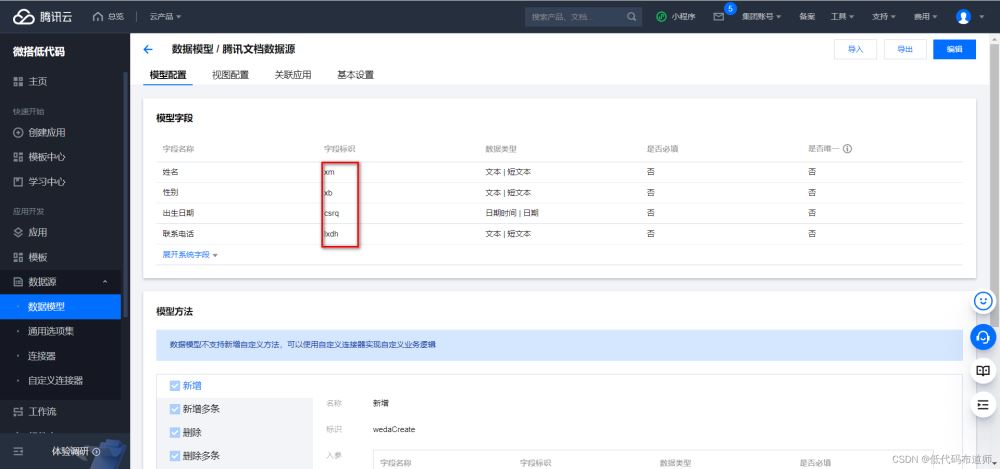
其余的代码因为涉及到具体的编程知识,你直接复用就可以,感兴趣的同学可以学习一下javascript,了解了语法之后就可以读的懂
写好之后点击按钮,发现有两条数据已经写入数据库了
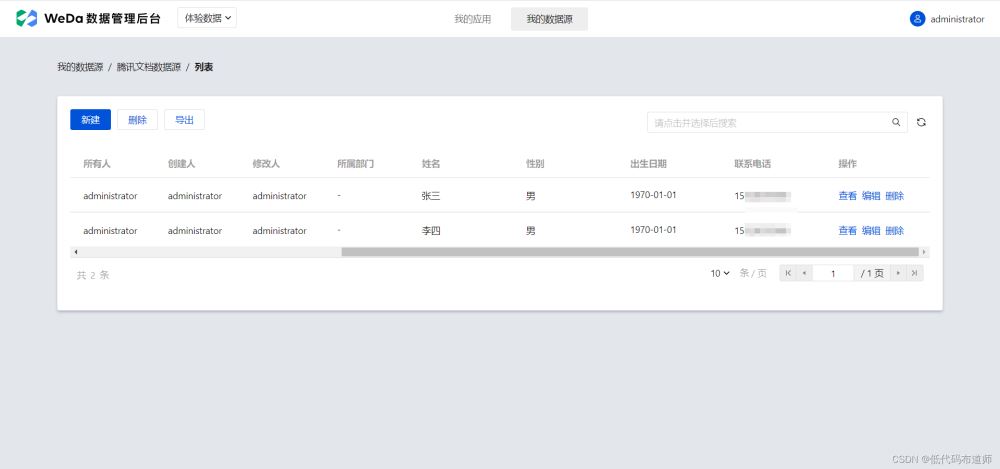
但是有个问题是出生日期没有正确的读出来,入库的日期都是1970-01-01。如果有解决办法的小伙伴可以评论区留言,也方便大家学习。
3 最终的代码
export default async function ({ event, data }) {
console.log(event, data)
const bookID = "DWkxMSFlkU1l2YkRo";
const { sheetData } = await app.cloud.callConnector({
name: 'txwd_jnegl1q',
methodName: 'getSheets',
params: {
bookID,
},
});
console.log(sheetData)
let sheetID = sheetData[0].sheetID
let rowCount = sheetData[0].rowCount
let columnCount = sheetData[0].columnCount
console.log(sheetID, rowCount, columnCount)
const { rows } = await app.cloud.callConnector({
name: 'txwd_jnegl1q',
methodName: 'getRows',
params: {
bookID,
sheetID,
rows: `2-${rowCount}`
},
});
console.log(rows)
const newRecords = [];
const columns = "xm|xb|csrq|lxdh";
for(let r = 0; r < rowCount - 1; r++) {
const { textValues } = rows[r];
const inputParams = {};
const cols = columns.split('|');
cols.forEach((c, i) => {
inputParams[c] = textValues[i];
});
newRecords.push(inputParams);
}
await app.cloud.callModel({
name: 'txwdsjy_q6rop6n',
methodName: 'wedaBatchCreate',
params: {
records: newRecords,
},
});
}
4 总结
我们本篇详细的介绍了低代码中如何解析腾讯文档的数据,如何批量入库。虽然现在低码中还没有批量导入的功能,但是我们通过腾讯文档也是可以做到的,如果学会了赶紧照着做一下吧。
加载全部内容