ORACLE正则表达式
阿诺伯格 人气:0ORACLE正则表达式我基本用到的就一下几种,前四种最长用到
- REGEXP_LIKE(source_char, pattern, match_parameter)
- REGEXP_SUBSTR(source_char, pattern, position, occurrence,match_parameter)
- REGEXP_INSTR(source_char, pattern, position, occurrence,match_parameter)
- REGEXP_REPLACE
- REGEXP_COUNT
- REGEXP_EXTRACT
- REGEXP_MATCH_COUNT
分享之前先给大家讲讲这些参数
1、source_char,输入的字符串,可以是列名或者字符串常量、变量。
2、pattern,正则表达式。
3、match_parameter,匹配选项。
match_parameter的取值模式:
i:大小写不敏感;
c:大小写敏感;
n:点号 . 不匹配换行符号;
m:多行模式;
x:扩展模式,忽略正则表达式中的空白字符。
4、position,标识从第几个字符开始正则表达式匹配。
5、occurrence:标识第几个匹配组。
6、return_option:
0:pattern的起始位置 ,1:pattern下一个字符起始位置, 默认为0
7、replace_string,替换的字符串。
下面我给大家介绍第一种
1.REGEXP_LIKE标量函数
REGEXP_LIKE标量函数返回一个布尔值,该布尔值指示是否在字符串中找到了正则表达式模式。这个函数和LIKE函数几乎很相近,只是LIKE函数匹配的是具体的字符或者数字,而这个函数匹配的是正则表达式。
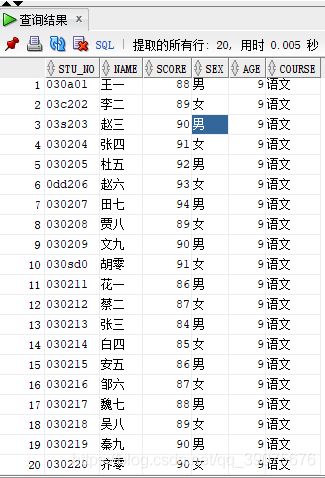
例如一张学生表中的学号既有全数字的也有数字字符混在的,现在学校希望将有字符混在的学号跳出来,这事就这可以用这个函数
表数据如下:
SELECT * FROM STUDENTS WHERE REGEXP_LIKE(STU_NO, '[a-z]+');
下面就是我们抽取的对象
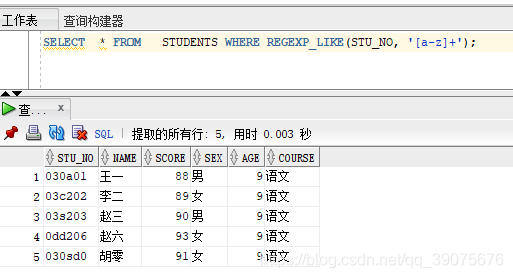
其他几种用法比较类似,就不一一说明了。
补充:综合应用的例子
col row_line format a30;
with sudoku as (
select '020000080568179234090000010030040050040205090070080040050000060289634175010000020' as line
from dual
),
tmp as (
select regexp_substr(line,'\d{9}',1,level) row_line,
level col
from sudoku
connect by level<=9
)
select regexp_replace( row_line ,'(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)(\d)','\1 \2 \3 \4 \5 \6 \7 \8 \9') row_line
from tmp;
ROW_LINE
------------------------------
0 2 0 0 0 0 0 8 0
5 6 8 1 7 9 2 3 4
0 9 0 0 0 0 0 1 0
0 3 0 0 4 0 0 5 0
0 4 0 2 0 5 0 9 0
0 7 0 0 8 0 0 4 0
0 5 0 0 0 0 0 6 0
2 8 9 6 3 4 1 7 5
0 1 0 0 0 0 0 2 0
总结
加载全部内容