React 数据获取性能优化
KooFE 人气:0引言
如果你尝试过对 React 中的数据获取 (data fetching) 进行一些思考,就会发现它涉及了众多内容:数据管理类库层出不穷,是否要拥抱 GraphQL;useEffect 是引起瀑布流的祸首,救世主 Suspence 尚处于实验阶段;fetch-on-render、 fetch-then-render 和 render-as-you-fetch 这些模式不由得让人上头。那么问题来了,在 React 中获取数据的 “正确方式” 是什么?本文将给予解答。
数据获取的分类
一般来说,在现代前端中,我们可以将 “数据获取” 大致分为两类:初始数据获取 (initial data fetching) 和按需数据获取 (data fetching on demand)。
按需数据获取,是用户和页面发生交互后再请求数据,以便提高页面的交互体验。所有的自动填充、动态表单和内容搜索都属于这一类数据。在 React 中,通常是在事件的回调函数中请求这些数据。
初始数据获取,是在打开页面时我们期望立刻能看到数据,我们要在组件出现在屏幕之前拿到这些数据。这些内容对于用户体验比较重要,需要尽快展示出来。在 React 中,通常是在 useEffect (或者 componentDidMount) 中来发起这类数据请求。
有趣的是,虽然它们在概念上看起来完全不同,但获取数据的核心原则和基本模式是完全相同的。对于大部分人来说,初始数据获取通常是至关重要的。在这一阶段,你的应用程序给用户留下第一印象,要么是 “慢如黄牛” 要么是 “快如闪电”。正是因为这个原因,本文将用大量的篇幅来介绍初始数据获取,以及如何在保证性能的前提下正确的实现数据获取。
React 获取数据与类库支持
首先要回答一个问题,在 React 中要用第三方类库来获取数据吗?是,也不是。这要取决于我们的具体场景,如果我们只是简单的请求一次数据,那么就不需要第三方库支持。在 useEffect 中直接使用 fetch 即可:
const Component = () => {
const [data, setData] = useState();
useEffect(() => {
// fetch data
const dataFetch = async () => {
const data = await (
await fetch(
"https://run.mocky.io/v3/b3bcb9d2-d8e9-43c5-bfb7-0062c85be6f9"
)
).json();
// set state when the data received
setState(data);
};
dataFetch();
}, []);
return <>...</>
}
但是当我们的场景变得复杂时,就会面临一些棘手的问题。错误处理要怎么实现?如何处理多个组件从同一个接口获取数据?这些数据是否要缓存?缓存时间是多久?竞态问题 (race conditions) 要如何处理?如果要从屏幕上删除组件,那该怎么办?应该取消这次请求吗?内存泄漏又要怎么解决?问题诸如此类。
上面提出的问题并不只是针对于 React,这些是网络请求中数据获取的常见问题。解决这些问题(还有更多)只有两条路:要么重新发明轮子编写大量代码来解决这些问题,要么依靠一些已经存在的成熟类库。
这些类库,比如 axios,将对一些功能进行抽象和封装,如请求取消等,但是并不提供针对 React 的 API。其他类库,比如 swr,将为我们处理了几乎所有的事情,包括缓存。但本质上,技术的选择在这里并不重要。世界尚不存在这样的类库,仅通过自身就能提高应用程序的性能。它们只是让一些事情变得更容易,同时也让另外一些事情变得更困难。为了编写高性能的应用程序,我们始终需要了解数据获取的基础知识和数据编排的模式以及其他相关的技术。
React 应用的性能
在介绍具体模式和代码示例之前,让我们先讨论一下应用的 “性能” 到底是什么。你如何确定这个应用的 “性能” 是否良好呢?对于一个简单的组件来说,相对比较直观的:只需要测量渲染的耗时即可。数字越小,组件 “性能” 越好(速度更快)。数据获取属于典型的异步操作,在大型应用中从用户体验角度来看性能,就不是那么直观了。
假设我们正在开发一个用来追踪 issue 的应用。页面的左侧是一个 Sidebar 侧边栏,展示了一个链接列表;中间部分是主内容区,它的上半部分是用于展示 issue 的详情区,比如标题、描述等;issue 详情区的下方是评论区。
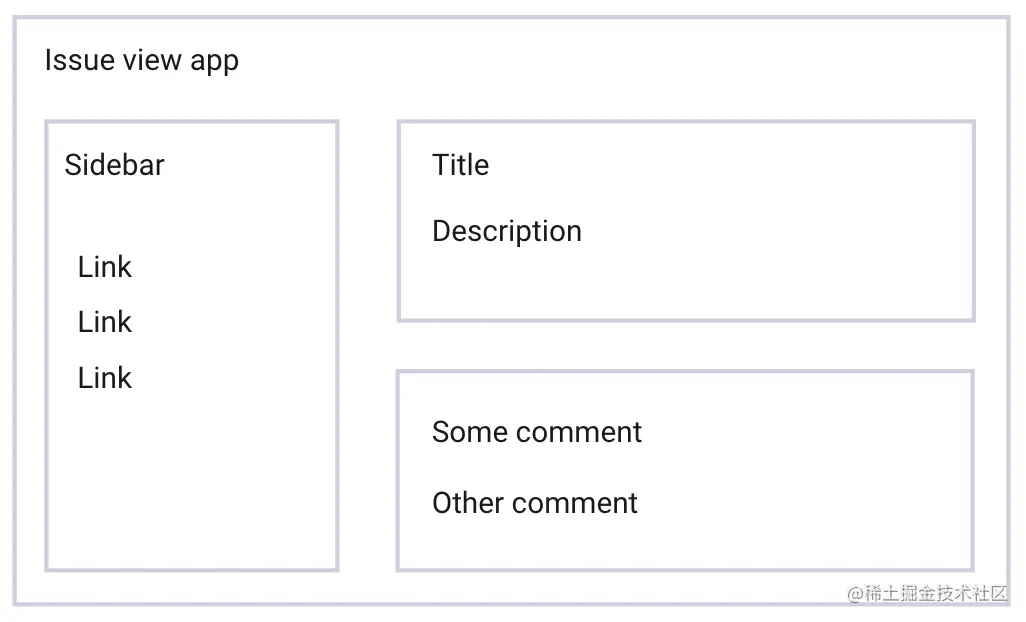
假如这个应用程序用下面三种不同的方式来实现:
- 展示一个 loading 状态,直至所有数据加载完毕,然后一次性渲染出所有数据。大约花费了 3s。
- 展示一个 loading 状态,侧边栏的数据加载完成后,渲染出侧边栏,然后继续保持 loading 状态,直到中间的内容区域的数据加载完成。侧边栏的需要 1s 的时间完成渲染,其他部分需要 3s 的时间。加到一起,大约花费了 4s。
- 展示一个 loading 状态,加载完主内容区的 issue 并渲染它,保持 loading 状态并加载侧边栏和评论的数据。侧边栏完成数据请求和渲染之后,继续为评论数据的加载保持 loading 状态。issue 的加载和渲染需要 2s,sidebar 在它之后需要 1s,评论需要额外的 2s 完成渲染。共计花费了 5s。
那么这个页面用哪种方案来实现的性能会更高呢?你是怎么认为的呢?当然,这个答案很棘手,还是要依据具体情况而定:
第一种实现方案总共花费 3s,是所有实现方案中最快的。单纯从数字的角度来看,毫无疑问它是胜出的。但是,在 3s 的时间里,它没有为用户呈现任何内容,这段白屏也是所有实现方案中最长的。
第二种实现方案只用了 1s 就在页面上显示出了一部分内容(Sidebar)。从尽可能快地展示内容的角度来看,它无疑是胜出的。但是,它是所有方案中主内容区耗时最长的。
第三种实现方案中,首先完成了主内容区的 issue 加载。从主内容区的加载速度来看,它是胜出的。但是,在从左到右的语言中,信息的自然流动方向是从左上到右下。这也是我们通常的阅读方式。这个页面违反了这个这个规则,这带来了最糟糕的用户体验。除此之外,它的加载时间是最长的。
对于方案的选择,通常取决于我们要向用户传递什么样的信息。把自己当作一个讲故事的人,而页面就是我们要讲述的故事。这个故事中最重要的部分是什么呢?次重要的部分又是什么呢?故事的情节是否连贯呢?你是想拆解成不同的章节讲述呢,还是立刻让用户看到故事的全貌呢?
只有当你对故事的样子有所了解,才是将故事整合在一起,并尽可能快地优化故事的时候。同理,应用的性能优化也是如此。而让我们解决问题的不是各种类库,Graphql 或 Suspense,而是下面的知识:
- 开始数据获取的合适的时机是什么?
- 在数据获取正在进行时,我们能做些什么?
- 在数据获取完成之后,我们应该做些什么?
以及使用一些技术手段,让我们在这三个阶段中控制数据请求。但在开始介绍这些技术之前,我们需要了解两个更基础的内容:React 生命周期和浏览器资源,以及其对我们目标的影响。
React 生命周期与数据获取
在我们设计数据请求的方案时,需要特别注意 React 生命周期被触发的时机。比如下面的代码:
const Child = () => {
useEffect(() => {
// do something here, like fetching data for the Child
}, []);
return <div>Some child</div>
};
const Parent = () => {
// set loading to true initially
const [isLoading, setIsLoading] = useState(true);
if (isLoading) return 'loading';
return <Child />;
}
在 Parent 组件中,Child 组件能否渲染取决于 state 的值。在 Child 组件中,useEffect 里的数据请求会被触发吗?很明显不会被触发。只有 Parent 组件中的 isLoading 被置为 false 时,Child 组件才会被渲染并且触发数据请求。那么再看下面的这段代码:
const Parent = () => {
// set loading to true initially
const [isLoading, setIsLoading] = useState(true);
// child is now here! before return
const child = <Child />;
if (isLoading) return 'loading';
return child;
}
功能基本完全一致:当 isLoading 被置为 false 时 展示 Child,如果为 true 则展示 loading 状态。不同的是,把 <Child /> 元素放在了 if 条件的前面。这样改变之后,Child 组件中的 useEffect 会被触发吗?答案不是那么明显,我看到过很多人在这里纠结。答案同样是不能触发请求。
尽管我们写下了 const child = <Child /> 这样的代码,但是这句代码并不会渲染组件。<Child/> 只不过是一种语法糖,在函数中用来描述将要创建的元素。只有这种描述信息在实际可见的渲染树中,它才会被渲染 -- 比如在组件中作为返回值。在这之前,它什么都不做,安安静静地待在那里。
当然,还有许多关于 React 生命周期的事情需要了解:生命周期触发的顺序是怎样的,绘制之前和之后会触发哪些内容,是什么减慢了什么以及如何触发的,LayoutEffect 钩子怎样使用等等。但是,当你已经很好地协调了所有事情,在一个复杂的应用中挣扎了几秒之后,所有这些就会变得密切相关了。在这里就不展开讨论这个问题了,否则这篇文章会变成一本书。
浏览器限制和数据获取
也许你会有这样的想法:这太复杂了,难道我们就不能尽快发出所有请求,并且将数据放入某个全局存储,然后在可用时使用它?为什么还要为生命周期和请求编排而烦恼呢?
是的,如果这个应用程序很简单,并且只需要很少的请求,我们确实可以这样做。但在大型应用程序中,我们可能有几十个数据请求,这种实现方案很可能适得其反。甚至忽视了服务器的负载能否可以处理。假设服务器可以,问题是我们的浏览器却不能!
你知道吗,浏览器对相同 host 可以处理的并行请求数是有限制的。假设服务器是 HTTP1(仍占互联网的70%),那么这个数字并没有那么大。在 Chrome 中,最多只能有 6 个并行请求!如果你同时发起更多请求,剩下的所有请求都必须排队,等待可以发送请求的时机。
在一个大型应用程序中,有 6 个以上的初始数据获取请求并非不合理。在我们上面提到的非常简单的 “追踪 issue 应用” 示例中已经有 3 个请求了,我们甚至还没有实现任何有价值的东西。
想象一下,如果你只是添加了一个稍微慢一些的用于数据分析的请求,在应用的最开始它几乎什么都不做,最终它却减慢整个体验,你会不会整个人都不好了。
下面是一个比较简单代码:
const App = () => {
// I extracted fetching and useEffect into a hook
const { data } = useData('/fetch-some-data');
if (!data) return 'loading...';
return <div>I'm an app</div>
}
假如在 App 中的数据请求非常快,只用了 50ms。如果在 App 之前再加 6 个请求,每个请求耗时都是 10s,那么整个 App 的加载时间也要花费 10s (当然这里是在 Chrome 浏览器中运行)。
// no waiting, no resolving, just fetch and drop it
fetch('https://some-url.com/url1');
fetch('https://some-url.com/url2');
fetch('https://some-url.com/url3');
fetch('https://some-url.com/url4');
fetch('https://some-url.com/url5');
fetch('https://some-url.com/url6');
const App = () => {
... same app code
}
假如我们删除其中某个请求,那么请求的时间就会降低很多。
出现请求瀑布流的原因
最后,是时候认真编码了!现在,我们已经拥有了所有需要的技术,并知道它们是如何组合在一起的,是时候开始编写我们的 Issue 追踪应用了。让我们来完成这个示例,看看如何讲述这个故事。
让我们首先完成组件布局,然后再进行数据获取。我们先实现应用的 App 组件,它将渲染 Sidebar 和 Issue,Issue 中渲染评论 Comments。
const App = () => {
return (
<>
<Sidebar />
<Issue />
</>
)
}
const Sidebar = () => {
return // some sidebar links
}
const Issue = () => {
return <>
// some issue data
<Comments />
</>
}
const Comments = () => {
return // some issue comments
}
现在来实现获取数据功能,首先将 fetch、useEffect 和状态管理封装到一个自定义 hook 中,代码如下:
export const useData = (url) => {
const [state, setState] = useState();
useEffect(() => {
const dataFetch = async () => {
const data = await (await fetch(url)).json();
setState(data);
};
dataFetch();
}, [url]);
return { data: state };
};
然后,我们将在更大的组件中请求数据:在 Issue 组件中请求 issue 数据,在 Comments 组件中请求评论列表。当然,还要在等待请求结果的过程中展示 loading 状态:
const Comments = () => {
// fetch is triggered in useEffect there, as normal
const { data } = useData('/get-comments');
// show loading state while waiting for the data
if (!data) return 'loading';
// rendering comments now that we have access to them!
return data.map(comment => <div>{comment.title}</div>)
}
在 Issue 中完成同样的代码,并且在 loading 结束之后,渲染 Comments 组件:
const Issue = () => {
// fetch is triggered in useEffect there, as normal
const { data } = useData('/get-issue');
// show loading state while waiting for the data
if (!data) return 'loading';
// render actual issue now that the data is here!
return (
<div>
<h3>{data.title}</h3>
<p>{data.description}</p>
<Comments />
</div>
)
}
App 的代码如下:
const App = () => {
// fetch is triggered in useEffect there, as normal
const { data } = useData('/get-sidebar');
// show loading state while waiting for the data
if (!data) return 'loading';
return (
<>
<Sidebar data={data} />
<Issue />
</>
)
}
当运行这段示例代码,你会发现执行起来很慢。我们这里所实现的是一个比较经典的请求瀑布流。还记得上面提到的 React 生命周期吗?组件只有作为返回值被返回时,才会被挂载和渲染,然后再去执行组件内部的 useEffect 和 数据请求。在这个实现方案中,各个组件在等待请求结果时,都返回的是 loading 状态。只有数据加载完成后,子组件才开始在组件树中渲染。然后子组件开始请求数据,展示 loading 状态,重复着和父组件一样的过程。
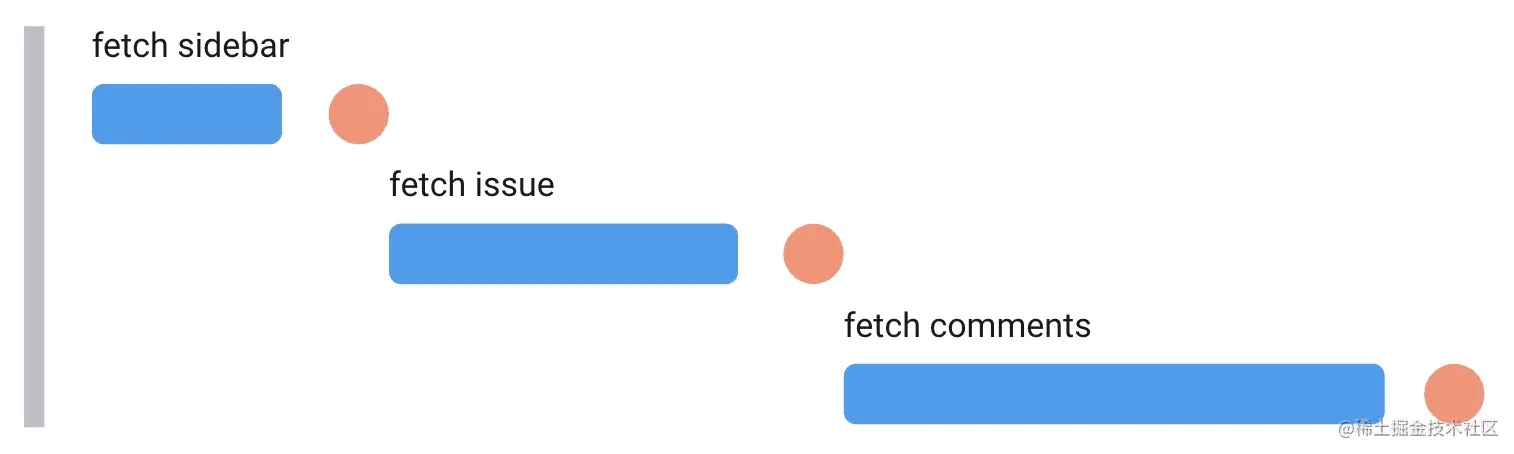
当我们想要尽快的展示应用页面时,像这样的瀑布流请求并不是一个好的解决方案。幸运的是,还有其他的方法来处理这个问题。
解决请求瀑布流的方案
Promise.all 方案
最简单的解决方案是,将这些请求尽可能的放在组件树的最顶层。在我们的示例中,这个最外层就是根组件 App。值得注意的是,我们并不是简简单单的将代码“换”个位置,还需要做一些额外的处理,像比如下面的代码是不行的:
useEffect(async () => {
const sidebar = await fetch('/get-sidebar');
const issue = await fetch('/get-issue');
const comments = await fetch('/get-comments');
}, [])
这是另外一种形式的瀑布流,只不过它位于一个组件中。当我们请求 sidebar 数据时会 await,当我们请求 issue 数据时会 await,请求 comment 数据时也会 await。当所有数据都可用时才会开始渲染,这个过程要等待的时间:1s + 2s + 3s = 6s。我们要做的是将所有请求同时发出,以并行的方式请求数据。这些请求中用时最长的时间,就是我们要等待的时间:3s,这样我们的性能就提升了 50%。
可以使用 Promise.all 来实现:
useEffect(async () => {
const [sidebar, issue, comments] = await Promise.all([
fetch('/get-sidebar'),
fetch('/get-issue'),
fetch('/get-comments')
])
}, [])
然后在父组件中把数据提供给 state 并通过 props 传递给子组件:
const useAllData = () => {
const [sidebar, setSidebar] = useState();
const [comments, setComments] = useState();
const [issue, setIssue] = useState();
useEffect(() => {
const dataFetch = async () => {
// waiting for allthethings in parallel
const result = (
await Promise.all([
fetch(sidebarUrl),
fetch(issueUrl),
fetch(commentsUrl)
])
).map((r) => r.json());
// and waiting a bit more - fetch API is cumbersome
const [sidebarResult, issueResult, commentsResult] = await Promise.all(
result
);
// when the data is ready, save it to state
setSidebar(sidebarResult);
setIssue(issueResult);
setComments(commentsResult);
};
dataFetch();
}, []);
return { sidebar, comments, issue };
};
const App = () => {
// all the fetches were triggered in parallel
const { sidebar, comments, issue } = useAllData()
// show loading state while waiting for all the data
if (!sidebar || !comments || !issue) return 'loading';
// render the actual app here and pass data from state to children
return (
<>
<Sidebar data={state.sidebar} />
<Issue comments={state.comments} issue={state.issue} />
</>
)
}
这也是我们在本文开始介绍的第一种方案的实现方式。
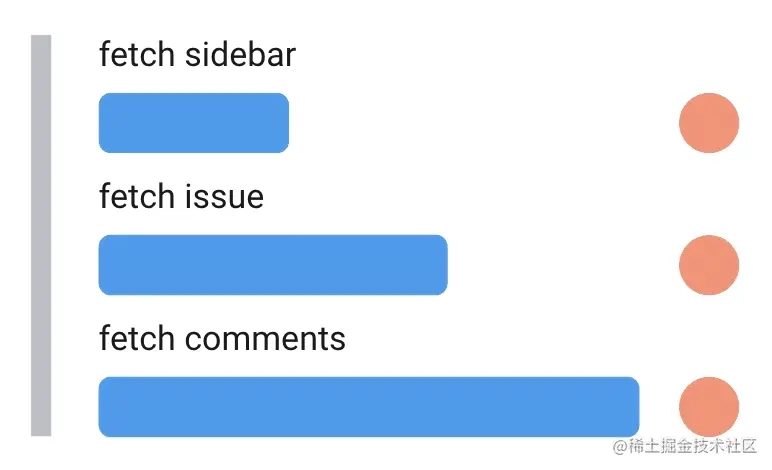
并行 Promise 方案
如果我们不想等到所有的数据请求都完成,该如何处理呢?comments 的请求比较慢,而且在页面中并不重要,因为它而阻塞 sidebar 渲染,是极其不明智的。是否能所有请求同时发出,各个组件独自等待各自的请求结果吗?
当然可以,只需将这些 fetch 从 async/await 转移到 Promise.then,在 then 的回调函数中处理数据。
fetch('/get-sidebar').then(data => data.json()).then(data => setSidebar(data));
fetch('/get-issue').then(data => data.json()).then(data => setIssue(data));
fetch('/get-comments').then(data => data.json()).then(data => setComments(data));
现在每个 fetch 请求都是并行的,在 App 的 render 函数中我们可用做更多的事情,比如:只要请求的数据给到 state,就可以渲染 SiderBar 和 Issue:
const App = () => {
const { sidebar, issue, comments } = useAllData();
// show loading state while waiting for sidebar
if (!sidebar) return 'loading';
// render sidebar as soon as its data is available
// but show loading state instead of issue and comments while we're waiting for them
return (
<>
<Sidebar data={sidebar} />
<!-- render local loading state for issue here if its data not available -->
<!-- inside Issue component we'd have to render 'loading' for empty comments as well -->
{issue ? <Issue comments={comments} issue={issue} /> : 'loading''}
</>
)
}
在这个代码中,只要数据准备好就可以渲染 Sidebar、Issue 和 Comments 组件。这与前面提到的瀑布的行为完全相同。但是由于我们并行的触发请求,总耗时从 6s 降低至 3s。我们大幅的提升了它的性能,同时保证了功能不受影响。

还有一件事不得不提,在这个方案中触发了三次 state 变化,这会引起父组件三次重新渲染。考虑到这些重新渲染发生在顶层组件,像这样不必要的重新渲染会引起 App 中较多不必要的重新渲染。始终要牢记,组件的顺序和组件的大小都会对性能产生影响。想要了解如何解决不必要的重新渲染,可以参考 React 重新渲染指南。
Data providers 抽象封装数据获取
像上面示例代码中那样,将数据加载提升到顶层组件,虽然在性能方面有很大的提升,但是对于应用架构和代码可读性来说简直就是噩梦。把所有的数据请求和大量的 props 放在一起,让我们得到了一个巨石组件。
存在一种简单的方案:可以为页面引入 “data providers” 的概念。在这里,data providers 是对数据请求的一种抽象,能让我们在 app 中的某个地方请求数据,然后在其他地方访问数据,可以绕过中间的所有组件。本质上就像为每个请求做了一层迷你的缓存。在原生的 React 中,它其实就是一个 context:
const Context = React.createContext();
export const CommentsDataProvider = ({ children }) => {
const [comments, setComments] = useState();
useEffect(async () => {
fetch('/get-comments').then(data => data.json()).then(data => setComments(data));
}, [])
return (
<Context.Provider value={comments}>
{children}
</Context.Provider>
)
}
export const useComments = () => useContext(commentsContext);
这三个请求中的逻辑完全相同,由于篇幅原因其他两个的代码不在这里列出。然后将我们的巨石组件 App 改造得更简单:
const App = () => {
const sidebar = useSidebar();
const issue = useIssue();
// show loading state while waiting for sidebar
if (!sidebar) return 'loading';
// no more props drilling for any of those
return (
<>
<Sidebar />
{issue ? <Issue /> : 'loading''}
</>
)
}
用这三个的 provider 来包裹 App 组件,只要它们被挂载,就会立即并行请求数据:
export const VeryRootApp = () => {
return (
<SidebarDataProvider>
<IssueDataProvider>
<CommentsDataProvider>
<App />
</CommentsDataProvider>
</IssueDataProvider>
</SidebarDataProvider>
)
}
在像 Comments 这种组件中(层级比较深的组件),只需通过 “data provider” 来访问数据:
const Comments = () => {
// Look! No props drilling!
const comments = useComments();
}
在 React 之前请求数据
关于瀑布流问题,最后一条要了解的技巧。把数据请求放在 React 前面,会发生什么。这是一个非常危险的做法,需要谨慎的去使用。
让我们再回顾一下 Comments 组件,在我们解决瀑布流问题的第一个方案中,在组件内部进行数据请求和处理:
const Comments = () => {
const [data, setData] = useState();
useEffect(() => {
const dataFetch = async () => {
const data = await (await fetch('/get-comments')).json();
setData(data);
};
dataFetch();
}, [url]);
if (!data) return 'loading';
return data.map(comment => <div>{comment.title}</div>)
}
注意第 6 行代码,fetch('/get-comments') 是一个在 useEffect await 的 promise。在这个场景中,它并不依赖 React 的任何东西,没有 对 props、state 或者其他内部变量有依赖。所以,把它移动到最顶部,放在声明 Comments 组件之前,会发生什么呢?并且然后在 useEffect 中 await 这个 promise 呢?
const commentsPromise = fetch('/get-comments');
const Comments = () => {
useEffect(() => {
const dataFetch = async () => {
// just await the variable here
const data = await (await commentsPromise).json();
setState(data);
};
dataFetch();
}, [url]);
}
发生了有趣的事情:fetch 基本上 “逃离” 了所有的 React 生命周期,只要页面加载完 JavaScript 就会进行数据请求,这时任何的 useEffect 还未被执行,甚至根组件 App 中的第一个请求也还未被发出。当这个请求发出去之后,JavaScript 进程会去处理其他事情,而返回的数据会安静地等待着被 resolve。我们在 Comments 的 useEffect 中做进行 resolve。
再看一下第一个方案的瀑布流的图:
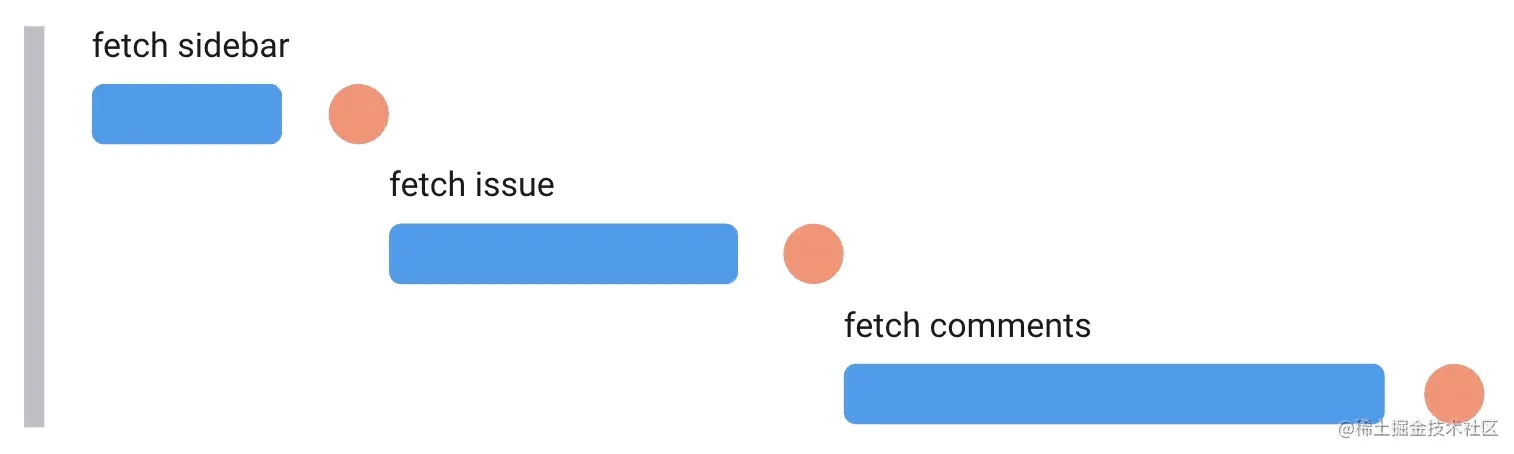
将 fetch 移到 Comments 的外面:

从技术角度来讲,可以将所有的 promise 移到组件的外面,这样就可以解决瀑布流的问题,这样就不需要做请求提升和 data providers。
但是为什么我们不去这样做呢?为什么它不是一种通用的模式呢?
还记得上面提到的浏览器限制吗,最多只能支持 6 个请求并行发出,剩下的请求要放到队列中等待。像这种在 React 组件外部发出的请求,完全是不可控的。在应用程序中,一个请求大量数据的组件,基本不可能立即开始渲染,以 “传统” 瀑布方法实现该组件,在实际渲染之前不会打扰任何人。但如果使用这种 hack 方式,会存在那些关键的数据可能被阻塞的风险。那么就会带来这样的问题:位于某个角落里毫不起眼、甚至还未被渲染的组件会拖慢整个应用页面。
对于这种模式,我只能想到两种 “适用” 场景:在路由层预加载一些关键资源,以及在 lazy-loaded 组件中预请求数据。
在第一种情况下,您实际上需要尽快获取数据,并且您肯定知道数据是比较关键的,并且是立即需要的。而且,lazy-loaded 组件的 JavaScript 只有在它们最终出现在呈现树中时才会被下载和执行,所以根据定义,在获取和呈现所有关键数据之后。所以它是安全的。
使用第三方类库做数据获取
直到现在为止,在上面的所有的代码示例中,我们使用的都是原生 fetch。目的是为了演示 React 中基础的数据请求模式,以及这些模式与类库无关的。无论你使用了和将要使用哪种第三方类库,瀑布流方法的原则、在 React 生命周期内外获取数据的方法始终是一致的。
Axios 这样和 React 无关的类库,是在 fetch 的基础上做了更复杂的抽象。我们可以将示例中的 fetch 更换为 axios.get,示例代码的运行结果不会有任何变化。
还有一些与 React 集成的类库,使用了 hooks 和 query-like API,比如 swr 抽象处理了更多的东西: useCallback、state、以及错误处理和缓存等。而不是像下面这样一大坨代码,需要实现很多东西才能用于生产环境:
const Comments = () => {
const [data, setData] = useState();
useEffect(() => {
const dataFetch = async () => {
const data = await (await fetch('/get-comments')).json();
setState(data);
};
dataFetch();
}, [url]);
// the rest of comments code
}
使用 swr 则简单明了:
const Comments = () => {
const { data } = useSWR('/get-comments', fetcher);
// the rest of comments code
}
所有的事情都在底层处理好了:使用 useEffect 请求数据,将数据更新至 state,触发组件重新渲染。
关于 Suspense
在介绍 React 数据获取时,如果不提一下 Suspence,是不完整的。所以 Suspense 解决了哪些数据获取方面的问题?并没有解决多少问题。在写这篇文章时,Suspense 数据获取还是实验特性,所以我不建议在任何生产相关的环境中使用它。
但让我们设想一下,如果 Suspense 的 API 已经固化下来保持不变,并将在不久后正式发布。它会从根本上解决数据获取问题吗?它会使上述一切问题成为历史吗?一点也不会。因为,我们仍然会受到浏览器资源限制、受到 React 生命周期以及请求瀑布流的限制。
Suspense 只是一种非常复杂和聪明的方式,用来取代对 loading 状态的处理。对于下面的代码:
const Comments = ({ commments }) => {
if (!comments) return 'loading';
// render comments
}
只需提升 loading 状态并执行以下操作:
const Issue = () => {
return <>
// issue data
<Suspence fallback="loading">
<Comments />
</Suspence>
</>
}
在使用 Suspence 时,也不要忘记上面的所有核心原则和限制。
总结
接下来对本文的重点做一个总结:
- 在 React 中获取数据不一定要用第三方类库,但它们也很有用
- 性能是主观的,始终取决于用户体验
- 可用的浏览器资源有限,只有 6 个并行请求;不要滥用 pre-fetching
- useEffect 本身不会导致瀑布,它们只是组件组合和 loading 状态带来的自然结果
加载全部内容