Tensorflow加载与预处理数据详解实现方法
沐兮Krystal 人气:0数据API
数据集方法不会修改数据集,而是创建新数据集。
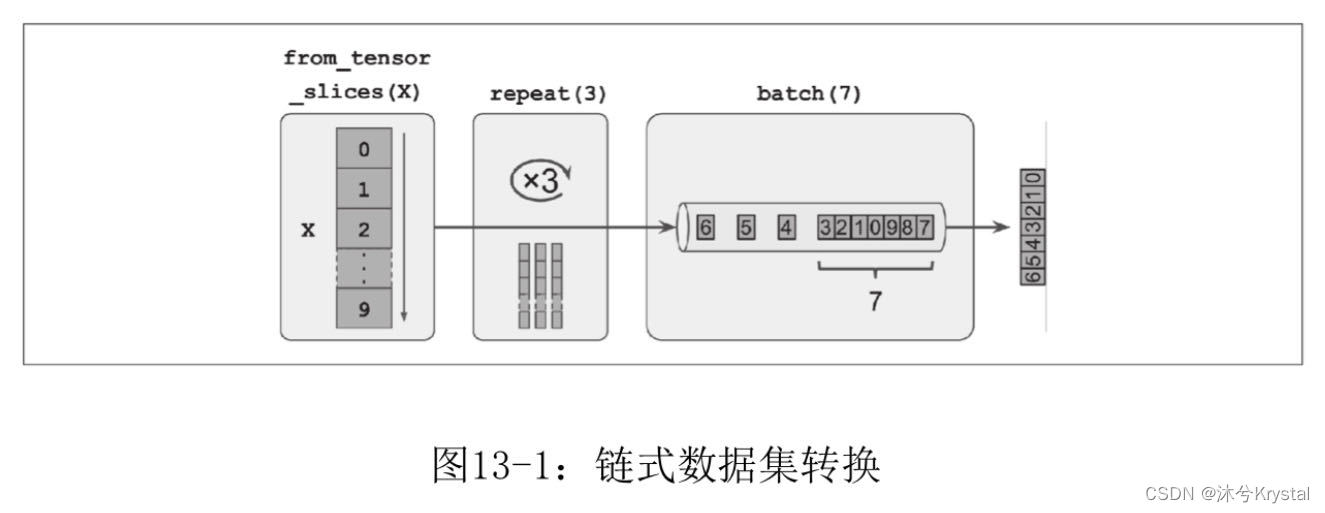
可通过调用 map() 方法将转换应用于每个元素:
dataset = dataset.map(lambda x: x * 2)
乱序数据
交织来自多个文件的行
list_files() 函数返回一个乱序的文件路径的数据集。
filepath_dataset = tf.data.Dataset.list_files(train_filepaths, seed=42)
一次读取5个文件,并交织它们的行。
n_readers = 5 dataset = filepath_dataset.interleave( lambda filepath: tf.data.TextLineDataset(filepath).skip(1), cycle_length=n_readers)
预处理数据
X_mean, X_std = [...] # 每个特征的均值和标准差 n_inputs = 8 # 对应8个特征 def preprocess(line): defs = [0.] * n_inputs + [tf.constant([], dtype=tf.float32)] # 包含csv中每一列的默认值的数组 fields = tf.io.decode_csv(line, record_defaults=defs) # line 是要解析的行,record_defaults 是一个包含CSV文件每一列的默认值的数组 x = tf.stack(fields[:-1]) y = tf.stack(fields[-1:]) return (x - X_mean) / X_std, y
我们在除最后一个(目标值)之外的所有张量上调用 tf.stack() ,从而将这些张量堆叠到一维度组中。然后对目标值执行相同的操作。
合并在一起
def csv_reader_dataset(filepaths, repeat=1, n_readers=5, n_read_threads=None, shuffle_buffer_size=10000, n_parse_threads=5, batch_size=32): dataset = tf.data.Dataset.list_files(filepaths) dataset = filepath_dataset.interleave( lambda filepath: tf.data.TextLineDataset(filepath).skip(1), cycle_length=n_readers, num_parallel_calls=n_read_threads) dataset = dataset.map(preprocess, num_parallel_calls=n_parse_threads) dataset = dataset.shuffle(shuffle_buffer_size).repeat(repeat) return dataset.batch(batch_size).prefetch(1)
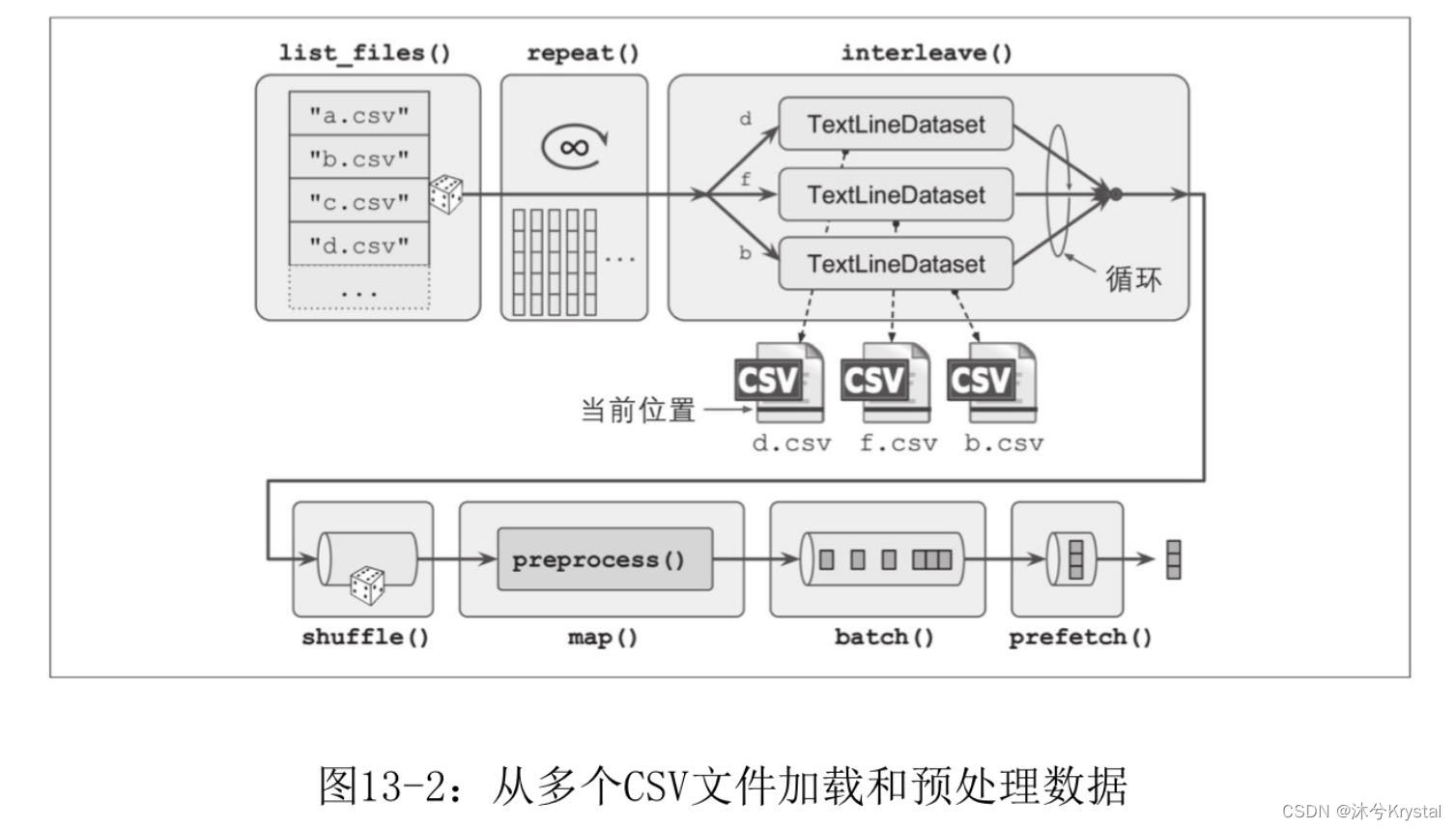
加载全部内容