pytorch使用voc分割数据集训练FCN流程讲解
专业女神杀手 人气:0语义分割是对图像中的每一个像素进行分类,从而完成图像分割的过程。分割主要用于医学图像领域和无人驾驶领域。

和其他算法一样,图像分割发展过程也经历了传统算法到深度学习算法的转变,传统的分割算法包括阈值分割、分水岭、边缘检测等等,面临的问题也跟其他传统图像处理算法一样,就是鲁棒性不够,但在一些场景单一不变的场合,传统图像处理依旧用的较多。
FCN是2014年的一篇论文,深度学习语义分割的开山之作,从思想上奠定了语义分割的基础。
Fully Convolutional Networks for Semantic Segmentation
Submitted on 14 Nov 2014
https://arxiv.org/abs/1411.4038
一、FCN理论介绍
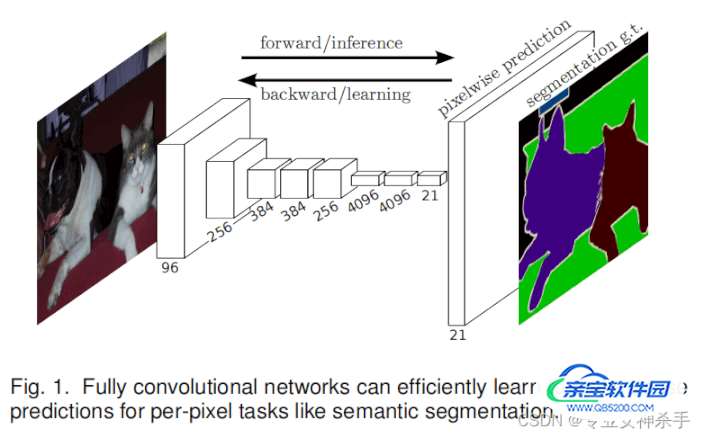
上图是原论文中的截图,从整体架构上描绘了FCN的网络架构。其实就是图像经过一系列卷积运算,然后再上采样成原图大小,输出每一个像素的类别概率。
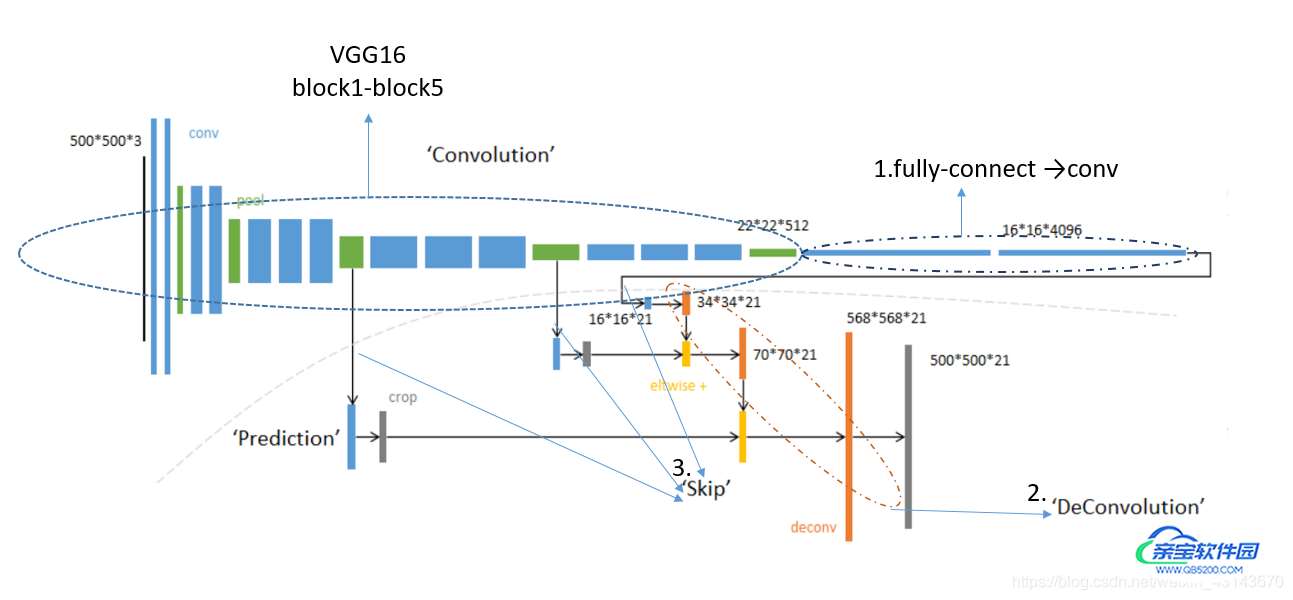
上图更加细致的描述了FCN的网络。backbone采用VGG16,把VGG的fully-connect层用卷积来表示,即conv6-7(一个大小和feature_map同样size的卷积核,就相当于全连接)。总的来说,网络有下列几个关键点:
1. Fully Convolution: 用于解决像素的预测问题。通过将基础网络(如VGG16)最后全连接层替换为卷积层,可实现任意大小的图像输入,并且输出图像大小与输入相对应;
2.Transpose Convolution: 上采样过程,用于恢复图片尺寸,方便后续进行逐个像素的预测;
3. Skip Architecture : 用于融合高底层特征信息。因为卷积是个下采样操作,而转置卷积虽然恢复了图像尺寸,但毕竟不是卷积的逆操作,所以信息肯定有丢失,而skip architecture可以融合千层的细粒度信息和深层的粗粒度信息,提高分割的精细程度。

FCN-32s: 没有跳连接,按照每层转置卷积放大2倍的速度放大,经过五层后放大32倍复原原图大小。
FCN-16s: 一个skip-connect,(1/32)放大为(1/16)后,再与vgg的(1/16)相加,然后继续放大,直到原图大小。
FCN-8s: 两个skip-connect,一个是(1/32)放大为(1/16)后,再与vgg的(1/16)相加;另外一个是(1/16)放大为(1/8)之后,再与vgg的(1/8)相加,然后继续放大,直到原图大小。
二、训练过程
pytorch训练深度学习模型主要实现三个文件即可,分别为data.py, model.py, train.py。其中data.py里实现数据批量处理功能,model.py定义网络模型,train.py实现训练步骤。
2.1 voc数据集介绍
下载地址:Pascal VOC Dataset Mirror
图片的名称在/ImageSets/Segmentation/train.txt ans val.txt里
图片都在./data/VOC2012/JPEGImages文件夹下面,需要在train.txt读取的每一行后面加上.jpg
标签都在./data/VOC2012/SegmentationClass文件夹下面,需要在读取的每一行后面加上.png
voc_seg_data.py
import torch
import torch.nn as nn
import torchvision.transforms as T
from torch.utils.data import DataLoader,Dataset
import numpy as np
import os
from PIL import Image
from datetime import datetime
class VOC_SEG(Dataset):
def __init__(self, root, width, height, train=True, transforms=None):
# 图像统一剪切尺寸(width, height)
self.width = width
self.height = height
# VOC数据集中对应的标签
self.classes = ['background','aeroplane','bicycle','bird','boat',
'bottle','bus','car','cat','chair','cow','diningtable',
'dog','horse','motorbike','person','potted plant',
'sheep','sofa','train','tv/monitor']
# 各种标签所对应的颜色
self.colormap = [[0,0,0],[128,0,0],[0,128,0], [128,128,0], [0,0,128],
[128,0,128],[0,128,128],[128,128,128],[64,0,0],[192,0,0],
[64,128,0],[192,128,0],[64,0,128],[192,0,128],
[64,128,128],[192,128,128],[0,64,0],[128,64,0],
[0,192,0],[128,192,0],[0,64,128]]
# 辅助变量
self.fnum = 0
if transforms is None:
normalize = T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
self.transforms = T.Compose([
T.ToTensor(),
normalize
])
# 像素值(RGB)与类别label(0,1,3...)一一对应
self.cm2lbl = np.zeros(256**3)
for i, cm in enumerate(self.colormap):
self.cm2lbl[(cm[0]*256+cm[1])*256+cm[2]] = i
if train:
txt_fname = root+"/ImageSets/Segmentation/train.txt"
else:
txt_fname = root+"/ImageSets/Segmentation/val.txt"
with open(txt_fname, 'r') as f:
images = f.read().split()
imgs = [os.path.join(root, "JPEGImages", item+".jpg") for item in images]
labels = [os.path.join(root, "SegmentationClass", item+".png") for item in images]
self.imgs = self._filter(imgs)
self.labels = self._filter(labels)
if train:
print("训练集:加载了 " + str(len(self.imgs)) + " 张图片和标签" + ",过滤了" + str(self.fnum) + "张图片")
else:
print("测试集:加载了 " + str(len(self.imgs)) + " 张图片和标签" + ",过滤了" + str(self.fnum) + "张图片")
def _crop(self, data, label):
"""
切割函数,默认都是从图片的左上角开始切割。切割后的图片宽是width,高是height
data和label都是Image对象
"""
box = (0,0,self.width,self.height)
data = data.crop(box)
label = label.crop(box)
return data, label
def _image2label(self, im):
data = np.array(im, dtype="int32")
idx = (data[:,:,0]*256+data[:,:,1])*256+data[:,:,2]
return np.array(self.cm2lbl[idx], dtype="int64")
def _image_transforms(self, data, label):
data, label = self._crop(data,label)
data = self.transforms(data)
label = self._image2label(label)
label = torch.from_numpy(label)
return data, label
def _filter(self, imgs):
img = []
for im in imgs:
if (Image.open(im).size[1] >= self.height and
Image.open(im).size[0] >= self.width):
img.append(im)
else:
self.fnum = self.fnum+1
return img
def __getitem__(self, index: int):
img_path = self.imgs[index]
label_path = self.labels[index]
img = Image.open(img_path)
label = Image.open(label_path).convert("RGB")
img, label = self._image_transforms(img, label)
return img, label
def __len__(self) :
return len(self.imgs)
if __name__=="__main__":
root = "./VOCdevkit/VOC2012"
height = 224
width = 224
voc_train = VOC_SEG(root, width, height, train=True)
voc_test = VOC_SEG(root, width, height, train=False)
# train_data = DataLoader(voc_train, batch_size=8, shuffle=True)
# valid_data = DataLoader(voc_test, batch_size=8)
for data, label in voc_train:
print(data.shape)
print(label.shape)
break- 我这里为了省事把一些辅助函数,如_crop(), _filter(),还是有变量colormap等都写到类里面了。实际上脱离出来另外写一个数据预处理的文件比较好,这样在训练结束后,推理测试时可以直接调用相应的处理函数。
- 数据处理的结果是得到data, label。data是tensor格式的图像,label也是tensor,且已经把像素(RGB)替换为了int类别号。这样在训练时候,交叉熵函数直接会实现one-hot处理,就跟训练分类网络一样。
2.2 网络定义
fcn8s_net.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
from torchsummary import summary
from torchvision import models
class FCN8s(nn.Module):
def __init__(self, num_classes=21):
super(FCN8s,self).__init__()
net = models.vgg16(pretrained=True) # 从预训练模型加载VGG16网络参数
self.premodel = net.features # 只使用Vgg16的五层卷积层(特征提取层)(3,224,224)----->(512,7,7)
# self.conv6 = nn.Conv2d(512,512,kernel_size=1,stride=1,padding=0,dilation=1)
# self.conv7 = nn.Conv2d(512,512,kernel_size=1,stride=1,padding=0,dilation=1)
# (512,7,7)
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512,512,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1) # x2
self.bn1 = nn.BatchNorm2d(512)
# (512, 14, 14)
self.deconv2 = nn.ConvTranspose2d(512,256,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1) # x2
self.bn2 = nn.BatchNorm2d(256)
# (256, 28, 28)
self.deconv3 = nn.ConvTranspose2d(256,128,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1) # x2
self.bn3 = nn.BatchNorm2d(128)
# (128, 56, 56)
self.deconv4 = nn.ConvTranspose2d(128,64,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1) # x2
self.bn4 = nn.BatchNorm2d(64)
# (64, 112, 112)
self.deconv5 = nn.ConvTranspose2d(64,32,kernel_size=3,stride=2,padding=1,dilation=1,output_padding=1) # x2
self.bn5 = nn.BatchNorm2d(32)
# (32, 224, 224)
self.classifier = nn.Conv2d(32, num_classes, kernel_size=1)
# (num_classes, 224, 224)
def forward(self, input):
x = input
for i in range(len(self.premodel)):
x = self.premodel[i](x)
if i == 16:
x3 = x # maxpooling3的feature map (1/8)
if i == 23:
x4 = x # maxpooling4的feature map (1/16)
if i == 30:
x5 = x # maxpooling5的feature map (1/32)
# 五层转置卷积,每层size放大2倍,与VGG16刚好相反。两个skip-connect
score = self.relu(self.deconv1(x5)) # out_size = 2*in_size (1/16)
score = self.bn1(score + x4)
score = self.relu(self.deconv2(score)) # out_size = 2*in_size (1/8)
score = self.bn2(score + x3)
score = self.bn3(self.relu(self.deconv3(score))) # out_size = 2*in_size (1/4)
score = self.bn4(self.relu(self.deconv4(score))) # out_size = 2*in_size (1/2)
score = self.bn5(self.relu(self.deconv5(score))) # out_size = 2*in_size (1)
score = self.classifier(score) # size不变,使输出的channel等于类别数
return score
if __name__ == "__main__":
model = FCN8s()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
print(model)FCN的网络代码实现上,在网上查的都有所差异,不过总体都是卷积+转置卷积+跳链接的结构。实际上只要实现特征提取(提取抽象特征)——转置卷积(恢复原图大小)——给每一个像素分类的过程就够了。
本次实验采用vgg16的五层卷积层作为特征提取网络,然后接五个转置卷积(2x)恢复到原图大小,然后再接一个卷积层把feature map的通道调整为类别个数(21)。最后再softmax分类就行了。
2.3 训练
train.py
import torch
import torch.nn as nn
from torch.utils.data import DataLoader,Dataset
from voc_seg_data import VOC_SEG
from fcn_net import FCN8s
import os
import numpy as np
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
mask = (label_true >= 0) & (label_true < n_class)
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
# 根据混淆矩阵计算Acc和mIou
def label_accuracy_score(label_trues, label_preds, n_class):
"""Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
"""
hist = np.zeros((n_class, n_class))
for lt, lp in zip(label_trues, label_preds):
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
acc = np.diag(hist).sum() / hist.sum()
with np.errstate(divide='ignore', invalid='ignore'):
acc_cls = np.diag(hist) / hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
with np.errstate(divide='ignore', invalid='ignore'):
iu = np.diag(hist) / (
hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)
)
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
return acc, acc_cls, mean_iu
def main():
# 1. load dataset
root = "./VOCdevkit/VOC2012"
batch_size = 32
height = 224
width = 224
voc_train = VOC_SEG(root, width, height, train=True)
voc_test = VOC_SEG(root, width, height, train=False)
train_dataloader = DataLoader(voc_train,batch_size=batch_size,shuffle=True)
val_dataloader = DataLoader(voc_test,batch_size=batch_size,shuffle=True)
# 2. load model
num_class = 21
model = FCN8s(num_classes=num_class)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
# 3. prepare super parameters
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.7)
epoch = 50
# 4. train
val_acc_list = []
out_dir = "./checkpoints/"
if not os.path.exists(out_dir):
os.makedirs(out_dir)
for epoch in range(0, epoch):
print('\nEpoch: %d' % (epoch + 1))
model.train()
sum_loss = 0.0
for batch_idx, (images, labels) in enumerate(train_dataloader):
length = len(train_dataloader)
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images) # torch.size([batch_size, num_class, width, height])
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
sum_loss += loss.item()
predicted = torch.argmax(outputs.data, 1)
label_pred = predicted.data.cpu().numpy()
label_true = labels.data.cpu().numpy()
acc, acc_cls, mean_iu = label_accuracy_score(label_true,label_pred,num_class)
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% | Acc_cls: %.03f%% |Mean_iu: %.3f'
% (epoch + 1, (batch_idx + 1 + epoch * length), sum_loss / (batch_idx + 1),
100. *acc, 100.*acc_cls, mean_iu))
#get the ac with testdataset in each epoch
print('Waiting Val...')
mean_iu_epoch = 0.0
mean_acc = 0.0
mean_acc_cls = 0.0
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(val_dataloader):
model.eval()
images, labels = images.to(device), labels.to(device)
outputs = model(images)
predicted = torch.argmax(outputs.data, 1)
label_pred = predicted.data.cpu().numpy()
label_true = labels.data.cpu().numpy()
acc, acc_cls, mean_iu = label_accuracy_score(label_true,label_pred,num_class)
# total += labels.size(0)
# iou = torch.sum((predicted == labels.data), (1,2)) / float(width*height)
# iou = torch.sum(iou)
# correct += iou
mean_iu_epoch += mean_iu
mean_acc += acc
mean_acc_cls += acc_cls
print('Acc_epoch: %.3f%% | Acc_cls_epoch: %.03f%% |Mean_iu_epoch: %.3f'
% ((100. *mean_acc / len(val_dataloader)), (100.*mean_acc_cls/len(val_dataloader)), mean_iu_epoch/len(val_dataloader)) )
val_acc_list.append(mean_iu_epoch/len(val_dataloader))
torch.save(model.state_dict(), out_dir+"last.pt")
if mean_iu_epoch/len(val_dataloader) == max(val_acc_list):
torch.save(model.state_dict(), out_dir+"best.pt")
print("save epoch {} model".format(epoch))
if __name__ == "__main__":
main()整体训练流程没问题,读者可以根据需要更改其模型评价标准和相关代码。在本次训练中,主要使用Acc作为评价指标,其实就是分类正确的像素个数除以全部像素个数。最终训练结果如下:
0.8

训练集的Acc来到了0.8, 验证集的Acc来到了0.77。由于有一些函数是复制过来的,如_hist等,所以其他指标暂时不参考。
加载全部内容