详解Java Map中三个冷门容器的使用
JAVA旭阳 人气:0概述
本篇文章主要讲解下Map家族中3个相对冷门的容器,分别是WeakHashMap、EnumMap、IdentityHashMap, 想必大家在平时的工作中也很少用到,或者压根不知道他们的特性以及适用场景,本篇文章就带你一探究竟。
WeakHashMap
介绍
WeakHashMap称为弱三列映射,实现了Map接口,具有如下特性:
- WeakHashMap中的entry是一个弱引用,当除了自身有对key的引用外,此key没有其他引用,那么GC之后此map会自动丢弃此值。
- 不是线程安全的
- 可以存储null
演示案例
public static void main(String[] args) {
String a = new String("a");
String b = new String("b");
Map weakmap = new WeakHashMap();
weakmap.put(a, "aaa");
weakmap.put(b, "bbb");
a = null;
b = null;
// 进行gc
System.gc();
Iterator j = weakmap.entrySet().iterator();
while (j.hasNext()) {
Map.Entry en = (Map.Entry) j.next();
System.out.println("weakmap:" + en.getKey() + ":" + en.getValue());
}
}
运行结果:

已经被gc回收了。
原理实现

从这里我们可以看到其内部的Entry继承了WeakReference,也就是弱引用,所以就具有了弱引用的特点。
弱引用的特点是在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程,因此不一定会很快发现那些只具有弱引用的对象。
WeakReference中有个成员变量ReferenceQueue,他的作用是GC会清理掉对象之后,引用对象会被放到ReferenceQueue中,然后遍历这个queue进行删除即可Entry。WeakHashMap内部有一个expungeStaleEntries函数,在这个函数内部实现移除其内部不用的entry从而达到的自动释放内存的目的。因此我们每次访问WeakHashMap的时候,都会调用这个expungeStaleEntries函数清理一遍。

使用场景
在如今的并发泛滥的大环境下,大家应该都用过缓存,缓存都是放在内存中的,而内存几乎是计算机中最宝贵也是最稀缺的资源,所以需要谨慎的使用,不然很容易就出现 OOM。缓存的主要作用是为了更快的处理业务、降低服务器的压力,那么就要保证缓存命中率,这里假设整个缓存是一个 key-value 结构的(以键值对缓存为例),HashMap 作为强引用对象在没有主动将 key 删除时是不会被 JVM 回收的,这样 HashMap 中的对象就会越积越多直到 OOM 错误;那么如何做到既让缓存的命中率高又不占用那么多的内存,这里就可以采用 WeakHashMap,当然不会有 HashMap 100% 的命中率(假设内存足够),但是在保证程序正常的前提下更好的实现了缓存这套解决方案。
EnumMap
介绍
用于枚举类型键的专用Map实现。枚举映射中的所有键必须来自创建映射时显式或隐式指定的单个枚举类型。
相对于HashMap中枚举作为key, EnumMap内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
- 不是线程安全的
- 可以存放null值
演示案例
public static void main(String[] args) {
// 构造函数传入类型
Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);
map.put(DayOfWeek.MONDAY, "星期一");
map.put(DayOfWeek.TUESDAY, "星期二");
map.put(DayOfWeek.WEDNESDAY, "星期三");
map.put(DayOfWeek.THURSDAY, "星期四");
map.put(DayOfWeek.FRIDAY, "星期五");
map.put(DayOfWeek.SATURDAY, "星期六");
map.put(DayOfWeek.SUNDAY, "星期日");
System.out.println(map);
System.out.println(map.get(DayOfWeek.MONDAY));
}
enum DayOfWeek {
MONDAY, TUESDAY, WEDNESDAY, THURSDAY, FRIDAY, SATURDAY, SUNDAY
}
原理实现
put方法源码如下:
public V put(K key, V value) {
// 对枚举类型进行检查,看key和构造函数传入的class类型是否一致
typeCheck(key);
// 枚举的顺序
int index = key.ordinal();
// 原来位置的值
Object oldValue = vals[index];
// 设置值
vals[index] = maskNull(value);
if (oldValue == null)
size++;
return unmaskNull(oldValue);
}
通过put源码发现是通过数组的方式实现存储,而且也不需要进行扩容。
使用场景
如果项目中遇到针对枚举作为key的映射容器,可以优先选择EnumMap。
IdentityHashMap
介绍
该类使用散列表实现Map接口,在比较键(和值)时使用引用相等代替对象相等。换句话说,在一个IdentityHashMap中,当且仅当(k1k2)两个键k1和k2被认为是相等的。(在正常的Map实现(如HashMap)两个键k1和k2被认为是相等的,当且仅当(k1null ?k2 = = null: k1.equals (k2)))。
- 不是线程安全的
- 无序
- key不可以是null
演示案例
public static void main(String[] args) {
// hashMap
Map<Integer, String> hashMap = new HashMap<>();
// identityHashMap
Map<Integer, String> identityHashMap = new IdentityHashMap<>();
hashMap.put(new Integer(200), "a");
hashMap.put(new Integer(200), "b");
identityHashMap.put(new Integer(200), "a");
identityHashMap.put(new Integer(200), "b");
//遍历hashmap
System.out.println("hashmap 结果:");
hashMap.forEach((key, value) -> {
System.out.println("key = " + key + ", value = " + value);
});
//遍历hashmap
System.out.println("identityHashMap 结果:");
identityHashMap.forEach((key, value) -> {
System.out.println("key = " + key + ", value = " + value);
});
}
运行结果:

原理实现
IdentityHashMap底层的数据结构就是数组,我们关注下put方法:

调用hash方法,获取key在table的位置index,然后进行赋值操作,也是分成了3种情况:
1.item == k,找到了对应的key,value存在key右相邻的位置,对tab[i + 1]进行更新,并返回原来的值;
2.item == null,表示table中没有对应的key值,跳出for循环,执行tab[i] = k和tab[i + 1] = value进行新key的插入操作。个人觉得这里的扩容时机选择的不太好,好不容易找到的更新位置,因为扩容给整没了,还得再次重新计算,可以和HashMap一样,在更新后再扩容。
3.item != null && item != key,表示hash冲突发生,调用nextKeyIndex获取处理冲突后的index位置,然后重复上面的过程。
我们再来看下hash方法:
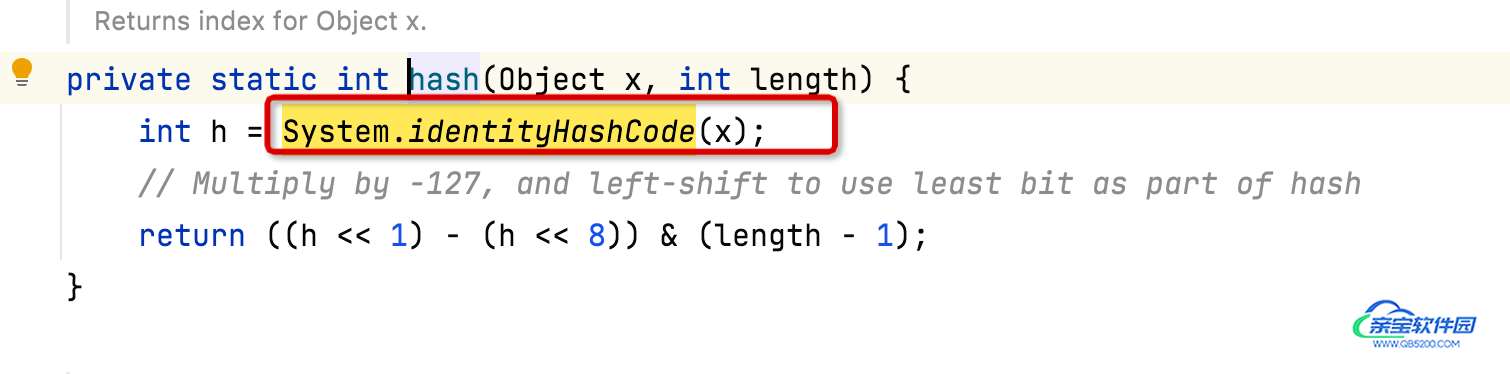
IdentityHashMap中获取hash值采用的System.identityHashCode方法,在不重写Object.hashCode方法时,System.identityHashCode和Object.hashCode返回的值相同,相当于对象的唯一的HashCode。System.identityHashCode(null)始终返回0, 无论是否重写Object.hashCode,都不影响System.identityHashCode的执行结果。
使用场景
当我们必须使用地址相等来判断值相等的场合,以及我们确定只要其地址不相等,则其equals方法的结果也必定不相等的场合。
加载全部内容