MySQL Count函数使用教程
爱吃南瓜糕的北络 人气:0COUNT 是一个汇总函数(聚集函数),它接受一个表达式作为参数:
COUNT(expr)
COUNT函数用于统计在符合搜索条件的记录中,指定的表达式expr不为NULL的行数有多少。这里需要特别注意的是,expr不仅仅可以是列名,其他任意表达式都是可以的。
一、COUNT 的使用
select COUNT(key1) FROM t;
这个语句是用于统计在 t 表 key1 列 值不为 NULL 的行数是多少。
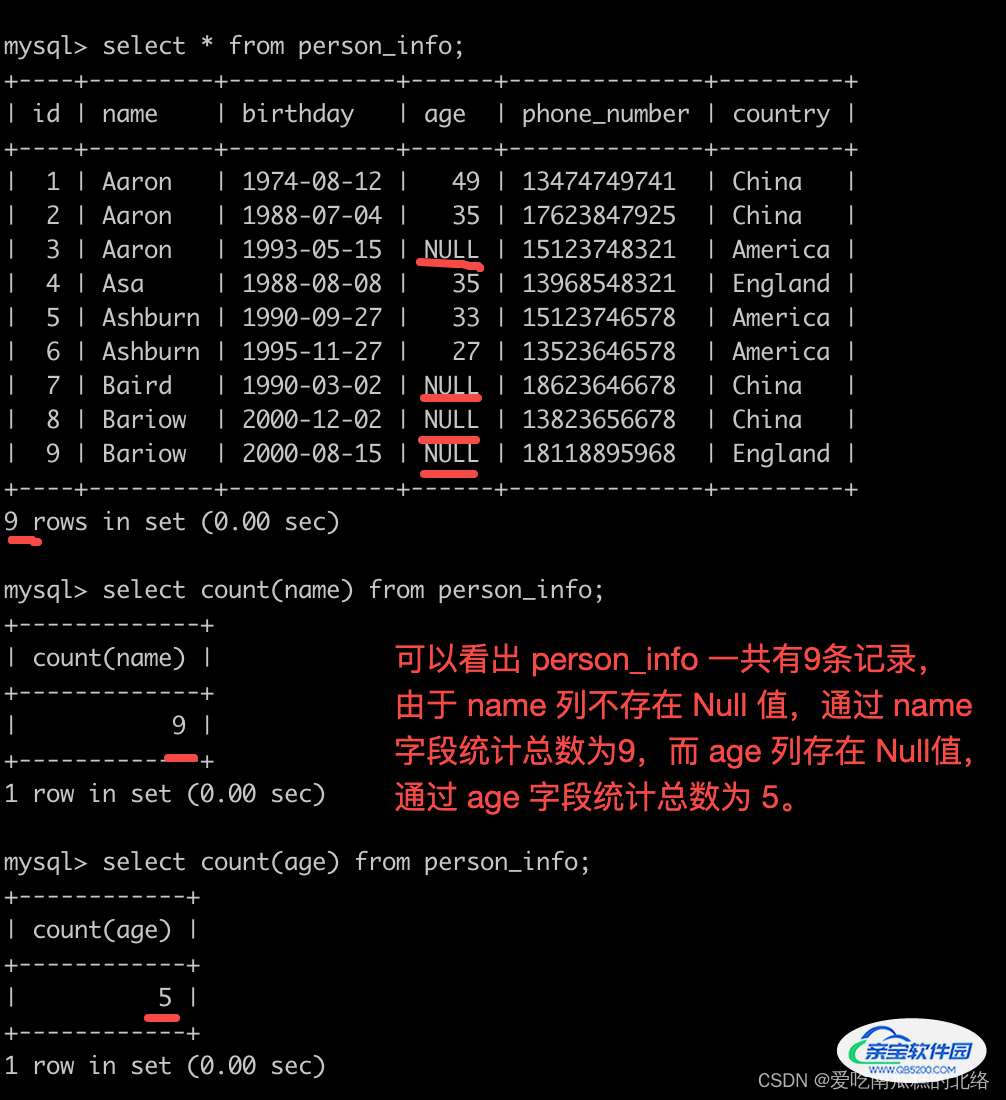
看下面的这个:
select COUNT('abc') FROM t;这个语句是用于统计在 t 表的所有记录中,‘abc’ 这个表达式不为 NULL的行数是多少。很显然,‘abc’ 这个表达式永远不为 NULL, 所以上述语句其实就是统计 t 表里有多少条记录。
再看这个:
select COUNT(*) from t;
这个语句就是直接统计 t 表中有多少条记录。
总结 + 注意:COUNT函数的参数可以是任意表达式, 该函数用于统计在符合搜索条件的记录中,指定的表达式不为NULL的行数有多少。
二、COUNT是怎么样运行的
mysql> select count(*) from single_table; +----------+ | count(*) | +----------+ | 12610 | +----------+ 1 row in set (0.00 sec) ####### single_table 表结构 ######## CREATE TABLE `single_table` ( `id` int NOT NULL AUTO_INCREMENT, `key1` varchar(100) DEFAULT NULL, `key2` int DEFAULT NULL, `key3` varchar(100) DEFAULT NULL, `key_part1` varchar(100) DEFAULT NULL, `key_part2` varchar(100) DEFAULT NULL, `key_part3` varchar(100) DEFAULT NULL, `common_field` varchar(100) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `idx_key2` (`key2`), KEY `idx_key1` (`key1`), KEY `idx_key3` (`key3`), KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`) ) ENGINE=InnoDB AUTO_INCREMENT=20000 DEFAULT CHARSET=utf8mb3 |
这个语句是要去查询表 single_table 中共包含多少条记录。由于聚簇索引和二级索引中的记录是一一对应的,而二级索引记录中包含的列是少于聚簇索引记录的,所以同样数量的二级索引记录可以比聚簇索引记录占用更少的存储空间。如果我们使用二级索引执行上述查询,即数一下idx_key2中共有多少条二级索引记录(存在多个二级索引,为什么选择idx_key2,下面会具体说明),是比直接数聚簇索引中共有多少聚簇索引记录可以节省很多I/O成本。所以优化器会决定使用idx_key2执行上述查询。
mysql> explain select count(*) from single_table; +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ | 1 | SIMPLE | single_table | NULL | index | NULL | idx_key2 | 5 | NULL | 12590 | 100.00 | Using index | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
在执行上述查询时,server层会维护一个名叫count的变量,然后:
(1)server层向InnoDB要第一条记录。
(2)InnoDB找到idx_key1的第一条二级索引记录,并返回给server层(注意:由于此时只是统计记录数量,所以并不需要回表)。
(3)由于COUNT函数的参数是*,MySQL会将*当作常数0处理。由于0并不是NULL,server层给count变量加1。
(4)server层向InnoDB要下一条记录。
(5)InnoDB通过二级索引记录的next_record属性找到下一条二级索引记录,并返回给server层。
(6)server层继续给count变量加1。
(7)... 重复上述过程,直到InnoDB向server层返回没记录可查的消息。
(8)server层将最终的count变量的值发送到客户端。
三、COUNT函数的索引使用情况
下面我们增对 count(*),count(1),count(常数),count(主键列),count(普通列(有索引)),count(普通列(无索引))
(1)count(*),count(1),count(常数)
mysql> show create table single_table;
+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| single_table | CREATE TABLE `single_table` (
`id` int NOT NULL AUTO_INCREMENT,
`key1` varchar(100) DEFAULT NULL,
`key2` int DEFAULT NULL,
`key3` varchar(100) DEFAULT NULL,
`key_part1` varchar(100) DEFAULT NULL,
`key_part2` varchar(100) DEFAULT NULL,
`key_part3` varchar(100) DEFAULT NULL,
`common_field` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_key2` (`key2`),
KEY `idx_key1` (`key1`),
KEY `idx_key3` (`key3`),
KEY `idx_key_part` (`key_part1`,`key_part2`,`key_part3`)
) ENGINE=InnoDB AUTO_INCREMENT=20000 DEFAULT CHARSET=utf8mb3 |
+--------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> select count(*) from single_table;
+----------+
| count(*) |
+----------+
| 12610 |
+----------+
1 row in set (0.00 sec)
## count(*) 采用了 idx_key2 索引
mysql> explain select count(*) from single_table;
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | single_table | NULL | index | NULL | idx_key2 | 5 | NULL | 12590 | 100.00 | Using index |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
## count(1) 采用了 idx_key2 索引
mysql> explain select count(1) from single_table;
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | single_table | NULL | index | NULL | idx_key2 | 5 | NULL | 12590 | 100.00 | Using index |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
## count('abc') 采用了 idx_key2 索引
mysql> explain select count('abc') from single_table;
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | single_table | NULL | index | NULL | idx_key2 | 5 | NULL | 12590 | 100.00 | Using index |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)通过上述查询结果可以看出:
count(*)、count(1)、count('abc') 均采用了 idx_key2,而索引idx_key2 对应的索引列为 key2,字段类型为 int,占用空间为最小的索引列。
结论:
对于 COUNT(*)、COUNT(1) 或者任意的 COUNT(常数) 来说,读取哪个索引的记录其实并不重要,因为server层只关心存储引擎是否读到了记录,而并不需要从记录中提取指定的字段来判断是否为NULL。所以优化器会使用占用存储空间最小的那个索引来执行查询。
(2)count(主键列)
## count(id) 采用了 idx_key2 索引 mysql> explain select count(id) from single_table; +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ | 1 | SIMPLE | single_table | NULL | index | NULL | idx_key2 | 5 | NULL | 12590 | 100.00 | Using index | +----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+ 1 row in set, 1 warning (0.00 sec)
通过上述查询结果可以看出:
count(id)采用了 idx_key2,而索引idx_key2 对应的索引列为 key2,字段类型为 int,占用空间为最小的索引列。
结论:
对于 COUNT(id) 来说,由于id是主键,不论是聚簇索引记录,还是任意一个二级索引记录中都会包含主键字段,所以其实读取任意一个索引中的记录都可以获取到id字段,此时优化器也会选择占用空间最小的那个索引来执行查询。
(3)count(普通列(有索引))
## count('key1') 采用了 idx_key1 索引
mysql> explain select count(key1) from single_table;
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | single_table | NULL | index | NULL | idx_key1 | 303 | NULL | 12590 | 100.00 | Using index |
+----+-------------+--------------+------------+-------+---------------+----------+---------+------+-------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
## count(common_field) 未采用任何索引
mysql> explain select count(common_field) from single_table;
+----+-------------+--------------+------------+------+---------------+------+---------+------+-------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------------+------------+------+---------------+------+---------+------+-------+----------+-------+
| 1 | SIMPLE | single_table | NULL | ALL | NULL | NULL | NULL | NULL | 12590 | 100.00 | NULL |
+----+-------------+--------------+------------+------+---------------+------+---------+------+-------+----------+-------+
1 row in set, 1 warning (0.00 sec)通过上述查询结果可以看出:
count(key1)采用了 idx_key1,索引idx_key1对应的索引列即为key1。count(common_field)未采用任何索引,common_field也不存在任何索引。
结论:
对于COUNT(非主键列)来说,我们指定的列可能并不会包含在每一个索引中。这样优化器只能选择包含我们指定的列的索引去执行查询,这就可能导致优化器选择的索引并不是最小的那个。
四、补充
对于count(非空普通列)来说,使用索引情况会怎么样?会不会直接采用最小占用空间索引呢?
mysql> show create table person_info; +-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Table | Create Table | +-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | person_info | CREATE TABLE `person_info` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(100) NOT NULL, `birthday` date NOT NULL, `age` int DEFAULT NULL, `phone_number` char(11) NOT NULL, `country` varchar(100) NOT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`), KEY `idx_age` (`age`) ) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb3 | +-------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 1 row in set (0.00 sec) mysql> explain select count(phone_number) from person_info; +----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------+ | 1 | SIMPLE | person_info | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | NULL | +----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-------+ 1 row in set, 1 warning (0.00 sec)
通过上述查询结果可以看出:
虽然 phone_number 字段为 not null,count(phone_number) 和 count(*) 结果一致,但是 phone_number 仍然并有选择走索引。
五、总结
(1)对于COUNT(*)、COUNT(常数)、COUNT(主键) 形式的COUNT函数来说,优化器可以选择最小索引执行查询,从而提升效率,它们的执行过程是一样的,只不过在判断表达式是否为NULL时选择不同的判断方式,这个判断为NULL的过程的代价可以忽略不计,所以我们可以认为 COUNT(*)、COUNT(常数)、COUNT(主键) 所需要的代价是相同的。
(2)对于 COUNT(非主键列) 来说,server层必须要从InnoDB中读到包含非主键列的记录,所以优化器并不能随心所欲的选择占用空间最小的索引去执行。
加载全部内容