python使用xlsx和pandas处理Excel表格的操作步骤
水w 人气:0一、使用xls和xlsx处理Excel表格
xls是excel2003及以前版本所生成的文件格式;
xlsx是excel2007及以后版本所生成的文件格式;
(excel 2007之后版本可以打开上述两种格式,但是excel2013只能打开xls格式);
1.1 用openpyxl模块打开Excel文档,查看所有sheet表
openpyxl.load_workbook()函数接受文件名,返回一个workbook数据类型的值。这个workbook对象代表这个Excel文件,这个有点类似File对象代表一个打开的文本文件。
workbook = xlrd2.open_workbook("1.xlsx") # 返回一个workbook数据类型的值
sheets = workbook.sheet_names()
print(sheets)
# 结果:
# ['Sheet1', 'Sheet2']或者
workbook = openpyxl.load_workbook("1.xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
# 结果:
# ['Sheet1', 'Sheet2']1.2 通过sheet名称获取表格
workbook = openpyxl.load_workbook("数据源总表(1).xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
sheet = workbook['Sheet1'] # 获取指定sheet表
print(sheet)
# 结果:
# ['Sheet1', 'Sheet2']
# <Worksheet "Sheet1">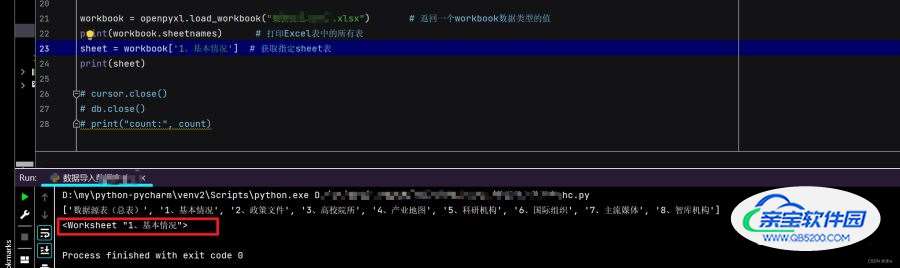
1.3 获取活动表的获取行数和列数
方法1:自己写一个for循环
方法2:使用
- sheet.max_row 获取行数
- sheet.max_column 获取列数
workbook = openpyxl.load_workbook("数据源总表(1).xlsx") # 返回一个workbook数据类型的值
print(workbook.sheetnames) # 打印Excel表中的所有表
sheet = workbook['1、基本情况'] # 获取指定sheet表
print(sheet)
print('rows', sheet.max_row, 'column', sheet.max_column) # 获取行数和列数
◼ 读取xlsx文件错误:xlrd.biffh.XLRDError: Excel xlsx file; not supported
运行代码时,会出现以下报错。
xlrd.biffh.XLRDError: Excel xlsx file; not supported
(1)检查第三方库xlrd的版本:
我这里的版本为xlrd2.0.1最新版本,问题就出在这里,我们需要卸载最新版本,安装旧版本,卸载安装过程如下。
(2)在File-Settings下的Project-Python Interpreter中重新按照旧版本xlrd2,
按照上述步骤卸载xlrd后再安装xlrd2后,
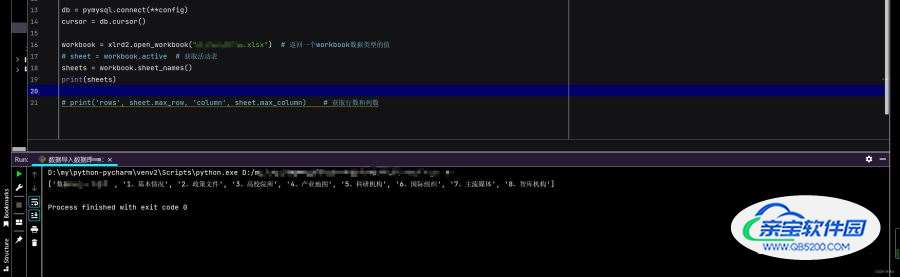
可以看到错误解决了。
二、使用pandas读取xlsx
pyCharm pip安装pandas库,请移步到python之 pyCharm pip安装pandas库失败_水w的博客-CSDN博客_pandas安装失败
2.1 读取数据
import pandas as pd
#1.读取前n行所有数据
df1=pd.read_excel('d1.xlsx')#读取xlsx中的第一个sheet
data1=df1.head(10) #读取前10行所有数据
data2=df1.values #list【】 相当于一个矩阵,以行为单位
#data2=df.values() 报错:TypeError: 'numpy.ndarray' object is not callable
print("获取到所有的值:\n{0}".format(data1))#格式化输出
print("获取到所有的值:\n{0}".format(data2))
#2.读取特定行特定列
data3=df1.iloc[0].values #读取第一行所有数据
data4=df1.iloc[1,1] #读取指定行列位置数据:读取(1,1)位置的数据
data5=df1.iloc[[1,2]].values #读取指定多行:读取第一行和第二行所有数据
data6=df1.iloc[:,[0]].values #读取指定列的所有行数据:读取第一列所有数据
print("数据:\n{0}".format(data3))
print("数据:\n{0}".format(data4))
print("数据:\n{0}".format(data5))
print("数据:\n{0}".format(data6))
#3.获取xlsx文件行号、列号
print("输出行号列表{}".format(df1.index.values)) #获取所有行的编号:0、1、2、3、4
print("输出列标题{}".format(df1.columns.values)) #也就是每列的第一个元素
#4.将xlsx数据转换为字典
data=[]
for i in df1.index.values: #获取行号的索引,并对其遍历
#根据i来获取每一行指定的数据,并用to_dict转成字典
row_data=df1.loc[i,['id','name','class','data','score',]].to_dict()
data.append(row_data)
print("最终获取到的数据是:{0}".format(data))
#iloc和loc的区别:iloc根据行号来索引,loc根据index来索引。
#所以1,2,3应该用iloc,4应该有loc读取特定的某几列的数据:
import pandas as pd file_path = r'int.xlsx' # r对路径进行转义,windows需要 df = pd.read_excel(file_path, header=0, usecols=[3, 4]) # header=0表示第一行是表头,就自动去除了, 指定读取第3和4列
2.2 使用pandas查找两个列表中相同的元素
解决:查找两个列表中相同的元素,可以把列表转为元祖/集合,进行交运算。
import pandas as pd
file_path = r'int.xlsx' # r对路径进行转义,windows需要
df = pd.read_excel(file_path, header=0, usecols=[3, 4]) # header=0表示第一行是表头,就自动去除了, 指定读取第3和4列
i, o = list(df['i']), list(df['o'])
in_links, out_links = [], []
a = set(in_links) # 转成元祖
b = set(out_links)
c = (a & b) # 集合c和b中都包含了的元素
print(a, '\n', b)
print('两个列表中相同的元素是:', list(c))
◼ 解决ValueError: Excel file format cannot be determined, you must specify an engine manually.
报错:我在使用python的pandas读取表格的数据,但是报错了,
import pandas as pd file_path = 'intersection.xlsx' # r对路径进行转义,windows需要 df = pd.read_excel(file_path, header=0, usecols=[0]) # header=0表示第一行是表头,就自动去除了, 指定读取第1列 print(df)
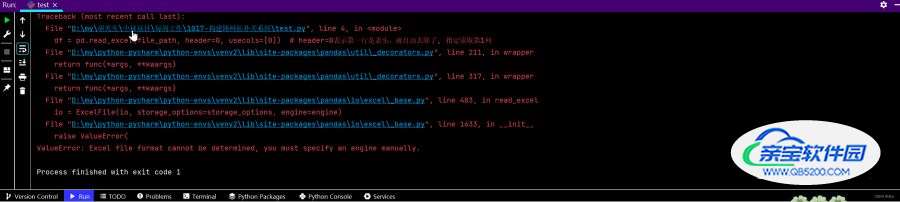
问题:问题在于原表格格式可能有些问题。
解决:最直接的办法就是把表格的内容复制到一个自己新建的表格中,然后改成之前表格的路径,
然后再安装这个openpyxl第三方库。
pip install openpyxl

重新运行代码,
ok,问题解决。
◼ 解决but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
报错:
but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
问题:xxx文件里有中文字符。
解决:在py文件的代码第一行 加上,
# -*-coding:utf8 -*-

◼ 解决MatplotlibDeprecationWarning: Support for FigureCanvases without a required_interactive_framework attribute was deprecated in Matplotlib 3.6 and will be removed two minor releases later.
报错:在使用pandas读取文件时,显示错误。
MatplotlibDeprecationWarning: Support for FigureCanvases without a required_interactive_framework attribute was deprecated in Matplotlib 3.6 and will be removed two minor releases later.
问题:matplotlib3.2以后就把mpl-data分离出去了 。
解决:卸载原来的版本,安装3.1版本。
pip uninstall matplotlib # 卸载原来的版本 pip install matplotlib==3.1.1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com # 安装3.1版本
总结
加载全部内容