Redis实现好友关注的示例代码
卒获有所闻 人气:0一、关注和取关
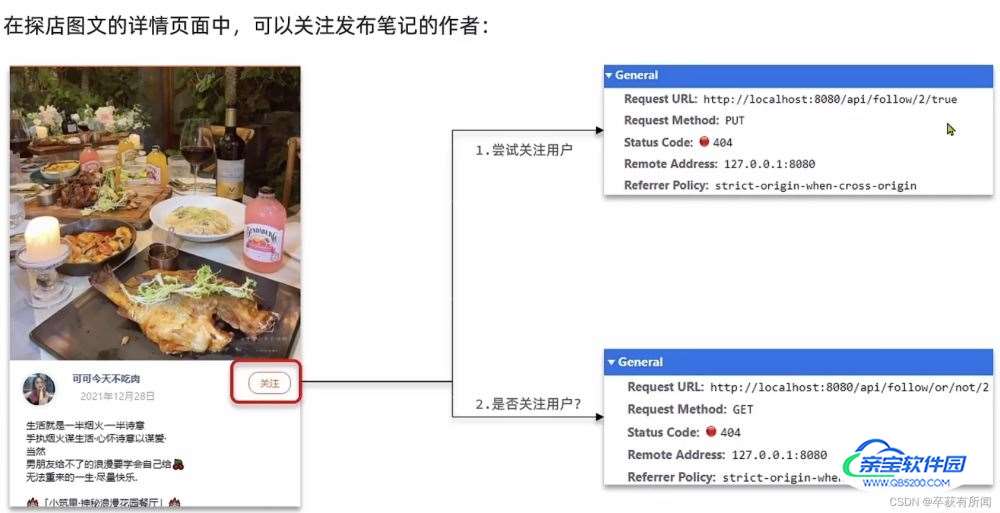
加载的时候会先发请求看是否关注了,来显示是关注按钮还是取关按钮
当我们点击关注或取关之后再发请求进行操作
数据库表结构
关注表(主键、用户id、关注用户id)
需求
- 关注和取关接口
- 判断是否关注接口
/**
* 关注用户
* @param id
* @param isFollow
* @return
*/
@PutMapping("/{id}/{isFollow}")
public Result follow(@PathVariable("id") Long id, @PathVariable("isFollow") Boolean isFollow){
return followService.follow(id,isFollow);
}
/**
* 判断是否关注指定用户
* @param id
* @return
*/
@GetMapping("/or/not/{id}")
public Result isFollow(@PathVariable("id") Long id){
return followService.isFollow(id);
}/**
* 关注用户
* @param id
* @param isFollow
* @return
*/
@Override
public Result follow(Long id, Boolean isFollow) {
//获取当前用户id
Long userId = UserHolder.getUser().getId();
//判断是关注操作还是取关操作
if(BooleanUtil.isTrue(isFollow)){
//关注操作
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(id);
save(follow);
}else{
//取关操作
remove(new QueryWrapper<Follow>().eq("user_id",userId).eq("follow_user_id",id));
}
return Result.ok();
}
/**
* 判断是否关注指定用户
* @param id
* @return
*/
@Override
public Result isFollow(Long id) {
//获取当前用户id
Long userId = UserHolder.getUser().getId();
Integer count = query().eq("user_id", userId).eq("follow_user_id", id).count();
if(count>0){
return Result.ok(true);
}
return Result.ok(false);
}二、共同关注
需求:利用redis中恰当的数据结构,实现共同关注功能,在博主个人页面展示当前用户和博主的共同好友
可以用redis中set结构的取交集实现
先在关注和取关增加存入redis
/**
* 关注用户
* @param id
* @param isFollow
* @return
*/
@Override
public Result follow(Long id, Boolean isFollow) {
//获取当前用户id
Long userId = UserHolder.getUser().getId();
String key = "follow:" + userId;
//判断是关注操作还是取关操作
if(BooleanUtil.isTrue(isFollow)){
//关注操作
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(id);
boolean success = save(follow);
if(success){
//插入set集合中
stringRedisTemplate.opsForSet().add(key,id.toString());
}
}else{
//取关操作
boolean success = remove(new QueryWrapper<Follow>().eq("user_id", userId).eq("follow_user_id", id));
//从set集合中移除
if(success){
stringRedisTemplate.opsForSet().remove(key,id.toString());
}
}
return Result.ok();
}然后就可以开始写查看共同好友接口了
/**
* 判断是否关注指定用户
* @param id
* @return
*/
@GetMapping("common/{id}")
public Result followCommons(@PathVariable("id") Long id){
return followService.followCommons(id);
}/**
* 共同关注
* @param id
* @return
*/
@Override
public Result followCommons(Long id) {
Long userId = UserHolder.getUser().getId();
//当前用户的key
String key1 = "follow:" + userId;
//指定用户的key
String key2 = "follow:" + id;
//判断两个用户的交集
Set<String> intersect = stringRedisTemplate.opsForSet().intersect(key1, key2);
if(intersect==null||intersect.isEmpty()){
//说明没有共同关注
return Result.ok();
}
//如果有共同关注,则获取这些用户的信息
List<Long> userIds = intersect.stream().map(Long::valueOf).collect(Collectors.toList());
List<UserDTO> userDTOS = userService.listByIds(userIds).stream().map(item -> (BeanUtil.copyProperties(item, UserDTO.class))).collect(Collectors.toList());
return Result.ok(userDTOS);
}三、关注推送(feed流)
关注推送也叫做fedd流,直译为投喂。为用户持续的提供"沉浸式"的体验,通过无限下拉刷新获取新的信息。feed模式,内容匹配用户。
Feed流产品有两种常见模式:
Timeline:不做内容筛选,简单的按照内容发布时间排序,常用于好友或关注。例如朋友圈
- 优点:信息全面,不会有缺失。并且实现也相对简单
- 缺点:信息噪音较多,用户不一定感兴趣,内容获取效率低
智能排序:利用智能算法屏蔽掉违规的、用户不感兴趣的内容。推送用户感兴趣信息来吸引用户
- 优点:投喂用户感兴趣信息,用户粘度很高,容易沉迷
- 缺点:如果算法不精准,可能起到反作用
本例中是基于关注的好友来做Feed流的,因此采用Timeline的模式。
1、Timeline模式的方案
该模式的实现方案有
- 拉模式
- 推模式
- 推拉结合
拉模式
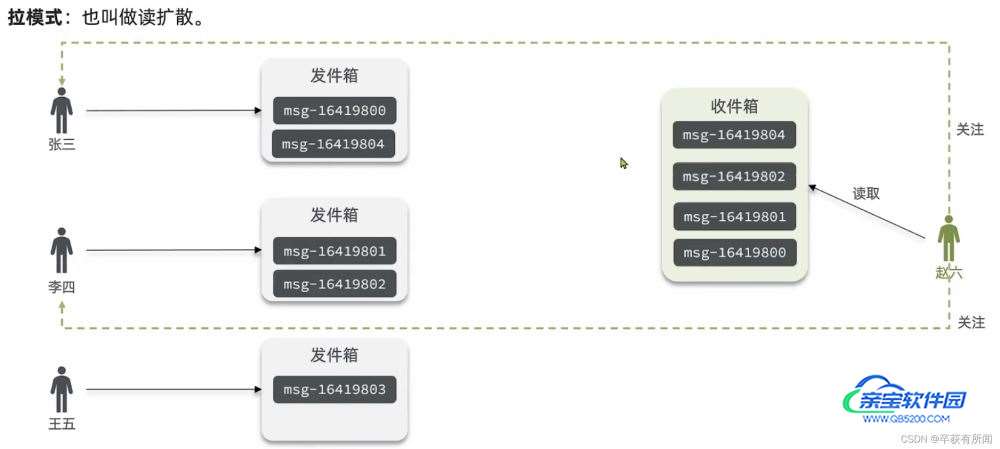
优点:节省内存消息,只用保存一份,保存发件人的发件箱,要读的时候去拉取就行了
缺点:每次读取都要去拉,耗时比较久
推模式
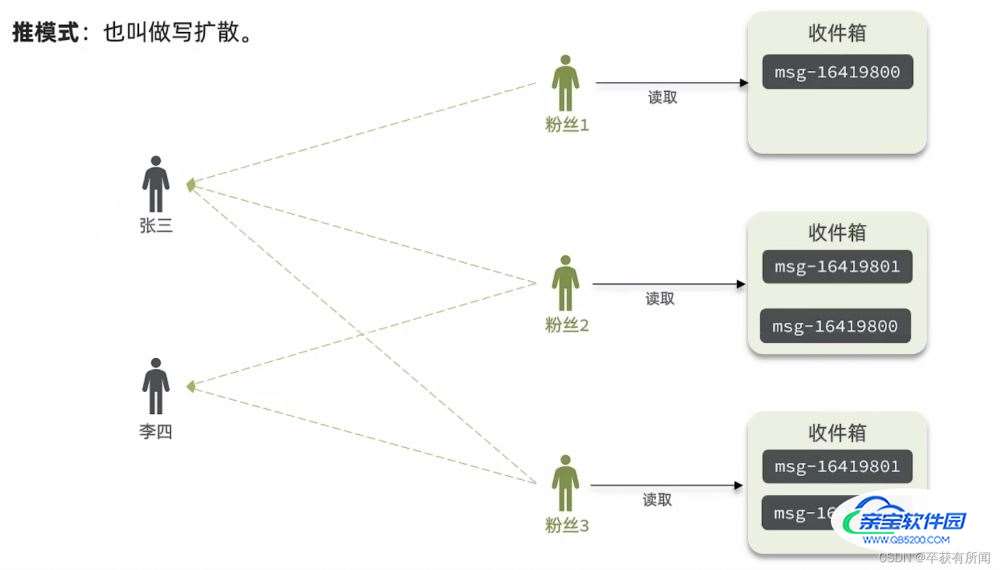
优点:延迟低
缺点:太占空间了,一个消息要保存好多遍
推拉结合模式
推拉结合分用户,比如大v很多粉丝就采用推模式,有自己的发件箱,让用户上线之后去拉取。普通人发的话就用推模式推给每个用户,因为粉丝数也不多直接推给每个人延迟低。粉丝也分活跃粉丝和普通粉丝,活跃粉丝用推模式有主机的收件箱,因为他天天都看必看,而普通粉丝用拉模式,主动上线再拉取,僵尸粉直接不会拉取,就节省空间。
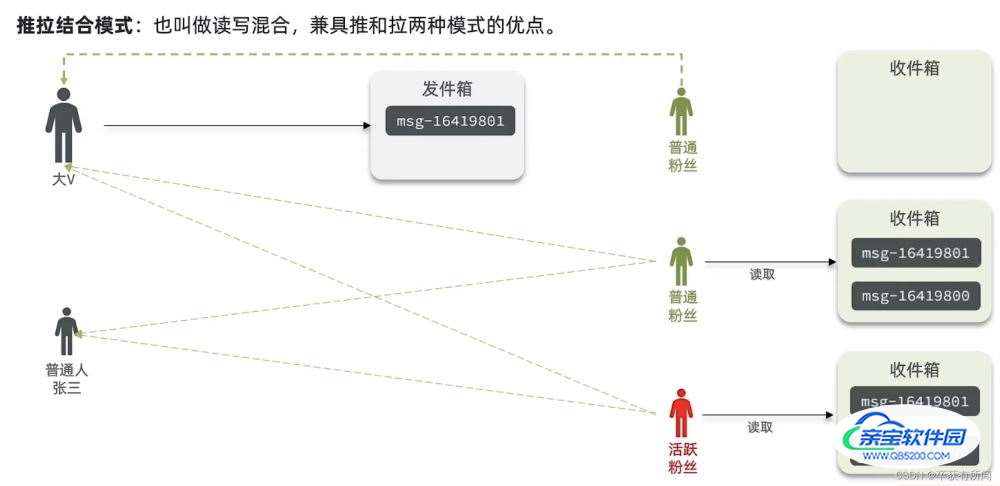
总结
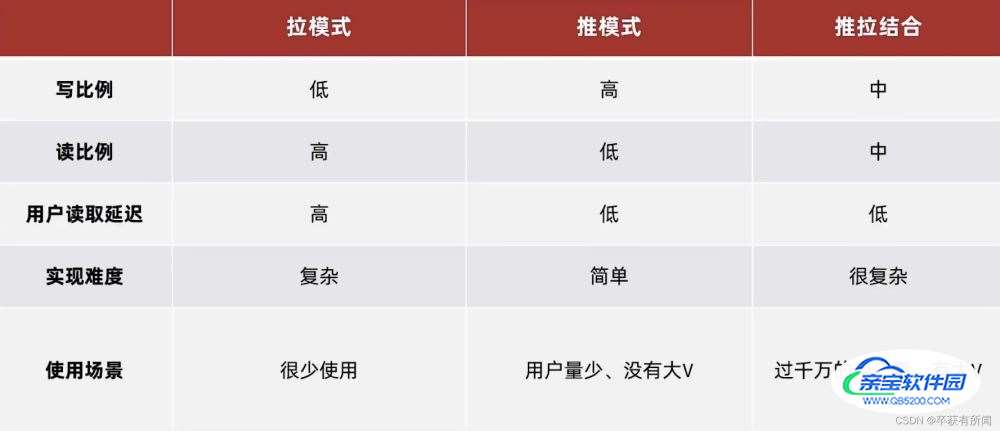
由于我们这点评网站,用户量比较小,所以我们采用推模式(千万以下没问题)。
2、推模式实现关注推送
需求
(1)修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
(2)收件箱满足可以根据时间排序,必须用redis的数据结构实现
(3)查询收件箱数据时,可以实现分页查询
要进行分页查询,那么我们存入redis采用什么数据类型呢,是list还是zset呢
feed流分页问题
假如我们在分页查询的时候,这个时候加了新的内容11, 再查询下一页的时候,6就重复出现了,为了解决这种问题,我们必须使用滚动分页
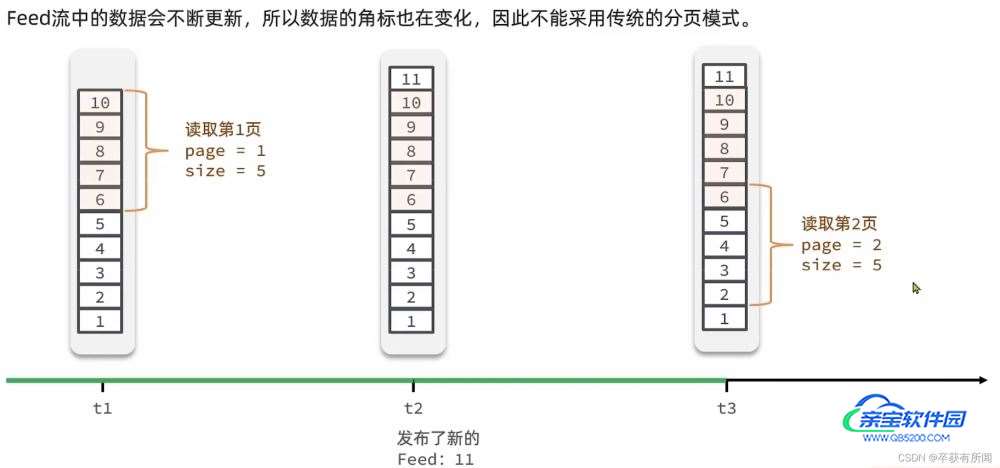
feed流的滚动分页
滚动分页就是每次都记住最后一个id,方便下一次进行查询,用这种lastid的方式来记住,不依赖于角标,所以我们不会收到角标的影响。所以我们不能用list来存数据,因为他依赖于角标,zset可以根据分数值范围查询。我们按时间排序,每次都记住上次最小的,然后从比这小的开始。
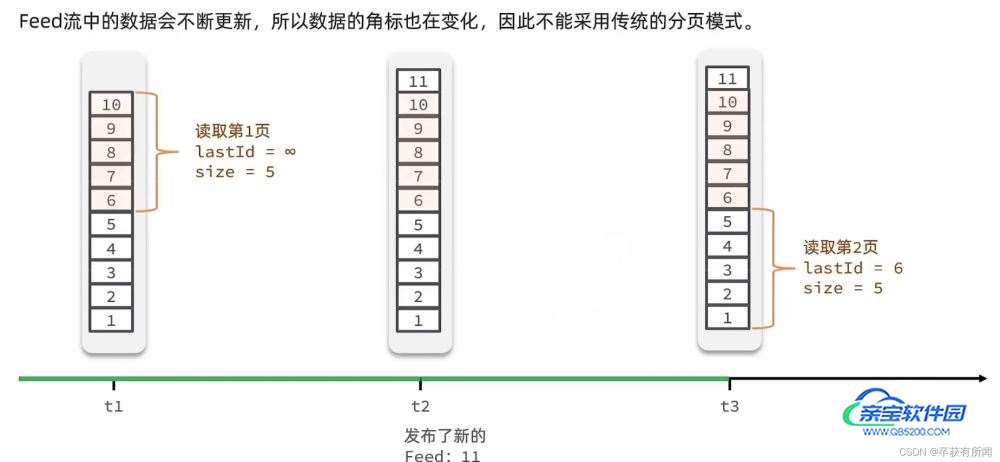
实现推送到粉丝的收件箱
修改新增探店笔记的业务,在保存blog到数据库的同时,推送到粉丝的收件箱
@Override
public Result saveBlog(Blog blog) {
// 1.获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 2.保存探店笔记
boolean isSuccess = save(blog);
if(!isSuccess){
return Result.fail("新增笔记失败!");
}
// 3.查询笔记作者的所有粉丝 select * from tb_follow where follow_user_id = ?
List<Follow> follows = followService.query().eq("follow_user_id", user.getId()).list();
// 4.推送笔记id给所有粉丝
for (Follow follow : follows) {
// 4.1.获取粉丝id
Long userId = follow.getUserId();
// 4.2.推送
String key = FEED_KEY + userId;
stringRedisTemplate.opsForZSet().add(key, blog.getId().toString(), System.currentTimeMillis());
}
// 5.返回id
return Result.ok(blog.getId());
}滚动分页接收思路
第一次查询是分数(时间)从1000(很大的数)开始到0(最小)这个范围,然后限制查3个(一页数量),偏移量是0,然后记录结尾(上一次的最小值)
以后每次都是从上一次的最小值到0,限定查3个,偏移量是1(因为记录的那个值不算),再记录结尾的值。
但是有一种情况,如果有相同的时间,分数一样的话,比如两个6分,而且上一页都显示完,我们下一页是按照第一个6分当结尾的,第二个6分可能会出现的,所以我们这个偏移量不能固定是1,要看有几个和结尾相同的数,如果是两个就得是2,3个就是3。
滚动分页查询参数:
- 最大值:当前时间戳 | 上一次查询的最小时间戳
- 最小值:0
- 偏移量:0 | 最后一个值的重复数
- 限制数:一页显示的数

实现滚动分页查询
前端需要传来两条数据,分别是lastId和offset,如果是第一次查询,那么这两个值是固定的,会由前端来指定,lastId是发起查询时的时间戳,而offset就是零,当后端查询完分页信息后需要返回三条数据,第一条自然就是分页信息,第二条是此次分页查询数据中最后一条数据的时间戳,第三条信息是偏移量,我们需要在分页查询后计算有多少条信息的时间戳与最后一条是相同的,作为偏移量来返回。而前端拿到这后两个参数之后就会分别保存在前端的lastId和offset中,下一次分页查询时就会将这两条数据作为请求参数来访问,然后不断循环上述过程,这样也就实现了分页查询。
定义返回值实体类
@Data
public class ScrollResult {
private List<?> list;
private Long minTime;
private Integer offset;
}Controller
@GetMapping("/of/follow")
public Result queryBlogOfFollow(
@RequestParam("lastId") Long max, @RequestParam(value = "offset", defaultValue = "0") Integer offset){
return blogService.queryBlogOfFollow(max, offset);
}BlogServiceImpl
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
//获取当前用户
Long userId = UserHolder.getUser().getId();
//组装key
String key = RedisConstants.FEED_KEY + userId;
//分页查询收件箱,一次查询两条 ZREVRANGEBYSCORE key Max Min LIMIT offset count
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet().reverseRangeByScoreWithScores(key, 0, max, offset, 2);
//若收件箱为空则直接返回
if (typedTuples == null || typedTuples.isEmpty()) {
return Result.ok();
}
//通过上述数据获取笔记id,偏移量和最小时间
ArrayList<Long> ids = new ArrayList<>();
long minTime = 0;
//因为这里的偏移量是下一次要传给前端的偏移量,所以初始值定为1
int os = 1;
for (ZSetOperations.TypedTuple<String> typedTuple : typedTuples) {
//添加博客id
ids.add(Long.valueOf(typedTuple.getValue()));
//获取时间戳
long score = typedTuple.getScore().longValue();
//由于数据是按时间戳倒序排列的,因此最后被赋值的就是最小时间
if (minTime == score) {
//如果有两个数据时间戳相等,那么偏移量开始计数
os++;
} else {
//如果当前数据的时间戳与已经记录的最小时间戳不相等,则说明当前时间小于已记录的最小时间戳,将其赋给minTime
minTime = score;
//偏移量重置
os = 1;
}
}
//需要考虑到时间戳相等的消息数量大于2的情况,这时候偏移量就需要加上上一页查询时的偏移量
os = minTime == max ? os : os + offset;
//根据id查询blog
String idStr = StrUtil.join(",", ids);
//查询时需要手动指定顺序
List<Blog> blogs = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
//这里还需要查询博客作者的相关信息,这里对比视频中,用一次查询代替了多次查询,提高效率
List<Long> blogUserIds = blogs.stream().map(blog -> blog.getUserId()).collect(Collectors.toList());
String blogUserIdStr = StrUtil.join(",", blogUserIds);
HashMap<Long, User> userHashMap = new HashMap<>();
userService.query().in("id", blogUserIds).last("ORDER BY FIELD(id," + blogUserIdStr + ")").list().
stream().forEach(user -> {
userHashMap.put(user.getId(), user);
});
//为blog封装数据
Iterator<Blog> blogIterator = blogs.iterator();
while (blogIterator.hasNext()) {
Blog blog = blogIterator.next();
User user = userHashMap.get(blog.getUserId());
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
blog.setIsLike(isLikeBlog(blog.getId()));
}
//返回封装数据
ScrollResult scrollResult = new ScrollResult();
scrollResult.setList(blogs);
scrollResult.setMinTime(minTime);
scrollResult.setOffset(os);
return Result.ok(scrollResult);
}加载全部内容