unified如何处理markdown解析器详解
kukiiu 人气:0unified是什么
unified是用于文档处理的生态系统,核心包提供了文档处理的流程控制,具体功能由生态系统中各个插件提供。例如我们如果需要处理markdown,就需要使用markdown处理相关的插件。当然除了markdwon以外,还提供了处理HTML、JSX等的插件。其良好的扩展能力能让我们很方便的在解析文档过程中添加各种新功能。
如果我们遇到了需要处理markdown文档、markdown转HTML、HTML转markdown等操作,那么可以尝试使用unified来作为解析器。
unified生态简介
上面说到unified除了用于解析markdown外,还有各种各样的插件用于不同类型的文档解析。
unified主要有以下四个生态系统:
每个生态系统下面都有用于处理各自文档类型的插件,以remark生态来说,如常用有以下插件:
- remark-parse - 用于将markdown字符串转换为语法树。通常来讲处理markdown都会首先用到这个插件,后续的插件会根据业务场景增删或替换语法树内容。
- remark-stringify - 用于将markdown语法树转换为markdown字符串,是
remark-parse的逆过程,经过处理后的语法树可通过该插件恢复成为markdown输出。 - remark-frontmatter - 用于处理markdown的‘元信息’,
frontmatter是一种在文档头部用于备注元信息的格式,通常我们用于配置该markdown的基本属性如标题、作者、标签等,这个插件可以帮助我们提取这些信息并转成结构化对象。
工作原理
unified工作流程由三个阶段组成:
| ............................... process ....................................... |
| .......... 解析(parse) ... | ... 处理(run) ... | ... 序列化(stringify) ..........|
+--------+ +----------+
Input ->- | Parser | ->- Syntax Tree ->- | Compiler | ->- Output
+--------+ | +----------+
X
|
+--------------+
| Transformers |
+--------------+
Parse
该阶段用于将Markdown, HTML, 或其他格式文档转换为抽象语法树(AST),基于语法树可以让程序更容易处理非结构化文档。常用的语法树有以下几种
remark-parse插件就是在该阶段工作。
Transform
该阶段用于根据业务场景处理AST,是整个流程的核心阶段,生态中大部分插件及我们自定义的插件大都运行在这个阶段。当然这个阶段是可选的,没有这个阶段也能运行,但是没有太大意义。remark-frontmatter插件就是在这个阶段工作。
还有一类称为桥接(Bridge)的插件也是运行在这个阶段,这类插件用于不同结构的AST相互转换。例如我们需要将处理后的Markdown转换为HTML,就需要将mdast转换为hast,常见的几种Bridge插件有:
- remark-rehype — Markdown 转 HTML
- rehype-remark — HTML 转 Markdown
- remark-retext — Markdown 转 自然语言
- rehype-retext — HTML 转 自然语言
Stringify
该阶段用于将AST序列化为字符串输出。 remark-stringify插件就是在这个阶段工作。
牛刀小试
环境搭建
安装依赖
npm install unified remark-parse remark-stringify remark-frontmatter js-yaml
编写运行代码
// index.js
const unified = require('unified')
console.log(unified)
运行
node index.js
报错
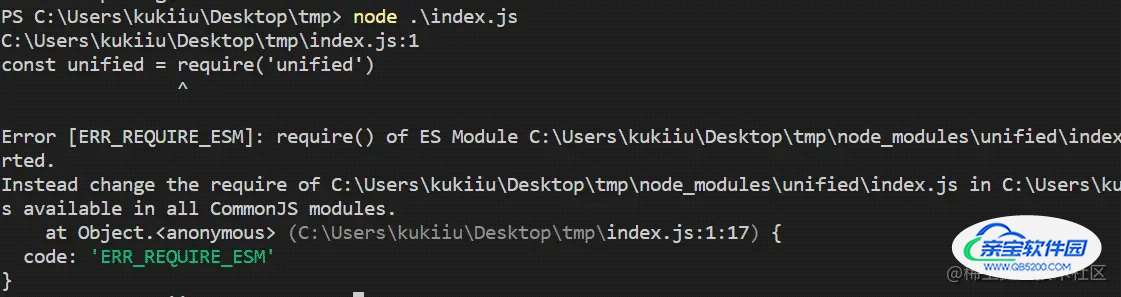
处理ESM类型包
由于unified使用的是ESM方式打包,而我们通常写的node代码用CommonJS方式在这里是无法正常运行的,所以我们需要使用ESM的方式来编写运行代码。
- 首先将
index.js改名为index.mjs(使用package.json配置也行,这里不举例了) - 将引入方式改为
ESM的import
// index.mjs
// 由于unified没有导出default,这里要用{}括起来
import { unified } from 'unified'
console.log(unified)
- 运行
node index.mjs
可以看到已经可以正常运行,基本运行环境就完成了。
最简用法
修改运行文件
import { unified } from 'unified'
import remarkParse from 'remark-parse'
import remarkStringify from 'remark-stringify'
// 初始化一个unified解析器
const res = unified()
// 使用Markdown解析器将文本转为AST
.use(remarkParse)
// 将MarkdownAST转为字符串
.use(remarkStringify)
// 开始同步执行解析
.processSync('# hello unified')
console.log(res)
这个例子仅是最基础的运行没有什么实际功能,运行结果:
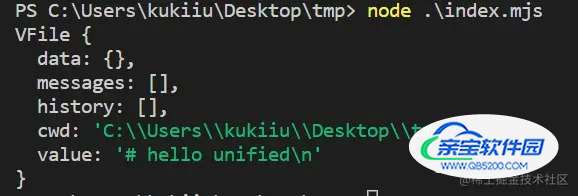
加载文档meta
import { unified } from 'unified'
import remarkParse from 'remark-parse'
import remarkFrontmatter from 'remark-frontmatter'
import remarkStringify from 'remark-stringify'
import yaml from 'js-yaml'
const res = unified()
.use(remarkParse)
// 添加解析yaml的插件,会将具有yaml块标志(默认为---)的文档块解析成为yaml类型节点,
.use(remarkFrontmatter, ['yaml'])
// 添加一个自定义插件来处理yaml类型节点
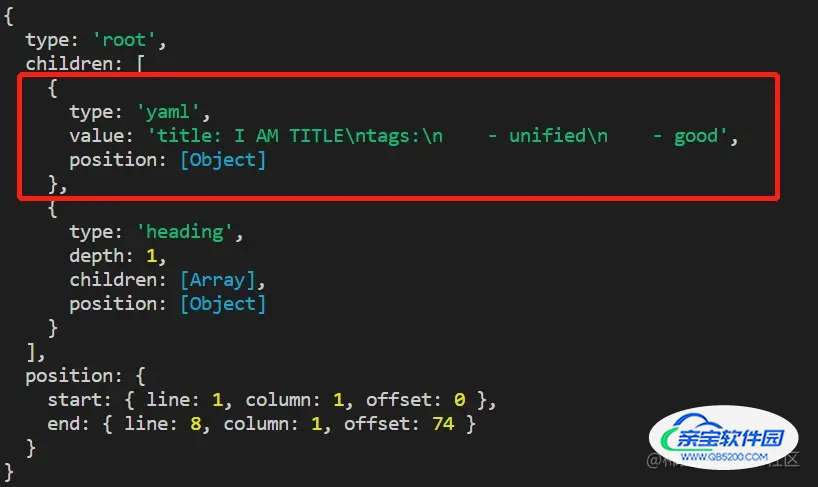
.use(() => (tree, vFile) => {
console.log(tree)
// unist-util-visit 提供了更多便捷访问AST的工具,这里我们先简单获取
const node = tree.children.find(n => n.type == 'yaml')
if(node) {
// 使用yaml解析器解析yaml格式字符串
const meta = yaml.load(node.value)
// { title: 'I AM TITLE', tags: [ 'unified', 'good' ] }
console.log(meta)
// 赋值到该文件的解析数据中返回给外部使用
vFile.data.meta = meta
}
})
.use(remarkStringify)
.processSync(`---
title: I AM TITLE
tags:
- unified
- good
---
# hello unified'
`)
console.log(res)
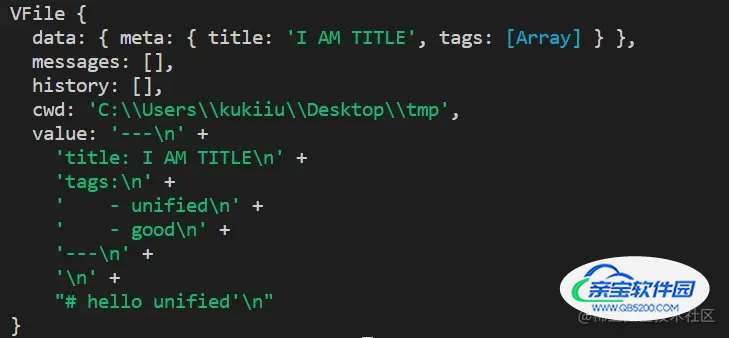
从打印结果可以看到,经过remark-frontmatter处理后,被---标志包含的文档块被转换成了yaml类型的节点,我们就可以方便的基于这个节点来解析数据了。
同时我们还自定义了一个简易的插件,用于处理yaml类型的节点,最终结果如下所示,已经正确提取出出来Markdown中的自定义属性数据:
一个实际使用例子:
该项目使用了unified来将markdown转换为react-jsx,markdown用于写组件说明文档,jsx用于渲染为网站。其中除了使用unified生态的部分插件外,dumi还实现了许多自定义的功能插件用于扩展markdown的语法。
本章后续将逐一拆解相关代码,深入学习unified插件开发及实战运用,更多关于unified处理markdown解析器的资料请关注其它相关文章!
加载全部内容