Python/MySQL实现Excel文件自动处理数据功能
酸菜鱼土豆大侠 人气:0问题描述
在没有服务器存储数据,只有excel文件的情况下,如何利用SQL和python实现数据分析和数据自动处理的功能?
例如:消费者购买商品时,会挑选商品然后再对商品付款。现在需要查找出用户挑中但是没有付款的商品并标识为未下单,付款的商品标注为下单。并且每隔一段时间自动执行上述操作。
目的:定时抽取上面的数据分析用户购买商品的行为。对比付款和选中未下单的商品的性能、价格等信息来发掘用户喜好,从而提高选品下单率。
注意:
- 用户的信息主要以excel的形式存储,没有服务器。
- 商品表里面存了用户挑选的商品信息。
- 订单表里面存了用户付款的商品信息。
解决方案
一、SQL查询
首先想到的是利用SQL语言实现这样的查询。具体实现过程如下:
(1) 建立dingdan表和shangpin表:
-- ----------------------------
-- Table structure for dingdan
-- ----------------------------
DROP TABLE IF EXISTS `dingdan`;
CREATE TABLE `dingdan` (
`d_id` int(11) NOT NULL,
`UPC` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`d_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of dingdan
-- ----------------------------
INSERT INTO `dingdan` VALUES (1, '6972470560664');
INSERT INTO `dingdan` VALUES (2, '6972470560664');
INSERT INTO `dingdan` VALUES (3, '6972470561227');
INSERT INTO `dingdan` VALUES (4, '6972470561890');
INSERT INTO `dingdan` VALUES (5, '6972470561906');
SET FOREIGN_KEY_CHECKS = 1;
-- ----------------------------
-- Table structure for shangpin
-- ----------------------------
DROP TABLE IF EXISTS `shangpin`;
CREATE TABLE `shangpin` (
`UPC` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`商品` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`UPC`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of shangpin
-- ----------------------------
INSERT INTO `shangpin` VALUES ('6972470560657', 'A');
INSERT INTO `shangpin` VALUES ('6972470560664', 'A');
INSERT INTO `shangpin` VALUES ('6972470561210', 'D');
INSERT INTO `shangpin` VALUES ('6972470561227', 'B');
INSERT INTO `shangpin` VALUES ('6972470561890', 'C');
INSERT INTO `shangpin` VALUES ('6972470651791', 'B');
SET FOREIGN_KEY_CHECKS = 1;

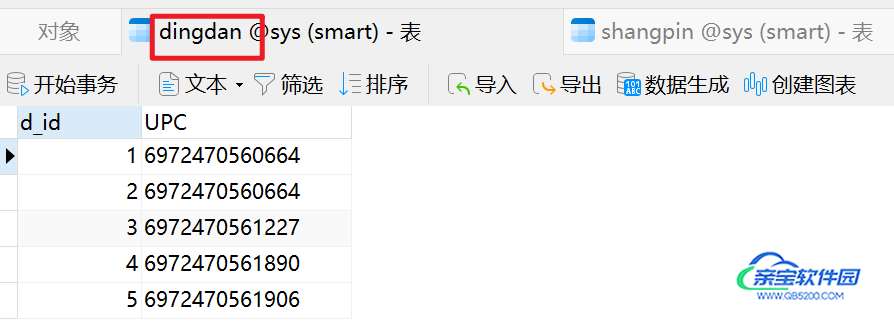
(2) 将excel数据导入SQL软件中。
执行下面的查询语句进行查找:
-- 搜索未下单的商品信息 SELECT *, if(bb.UPC IS NULL,'未下单', '下单') as 下单情况 FROM shangpin aa LEFT JOIN dingdan bb ON aa.UPC = bb.UPC
得到以下查询结果:
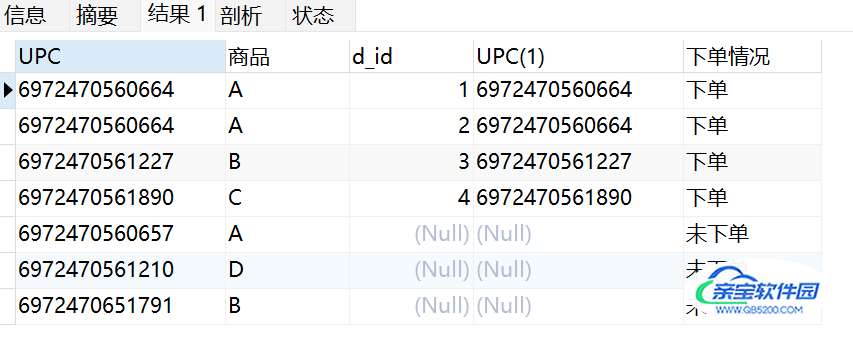
(3) 将搜索结果导出为excel。
(4) 隔一段时间,需要人工重复上面的操作。
二、SQL、python处理
利用SQL查询、python做定时处理。具体实现过程如下:
(1) 重复方案1中的步骤1和2,将数据导入到数据库中。
(2) 用python连接数据库并查找数据。
import pymysql #导入PyMySQL库
import datetime
import warnings
import pandas as pd
import matplotlib.pyplot as plt
warnings.filterwarnings('ignore')
# 1. 连接数据库,创建连接对象 db
# 连接对象作用是:连接数据库、发送数据库信息、处理回滚操作(查询中断时,数据库回到最初状态)、
# 创建新的光标对象
def connect_database(database, password):
db = pymysql.connect(host ="localhost", #host属性
user ="sys", #用户名
password = password, #此处填登录数据库的密码
database = database, #数据库名
charset="utf8" # 如果中文显示乱码,则需要添加charset = "utf8"
)
return db
def read_data(db):
# 2. 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 3. 利用MySQL语句查找数据并转化为FrameData(包含列名)
try:
# 使用 execute() 方法执行 SQL 查询
mysql = "SELECT *, if(bb.UPC IS NULL,'未下单', '下单') as 下单情况 FROM shangpin aa LEFT JOIN dingdan bb ON aa.UPC = bb.UPC" # SQL语句
cursor.execute(mysql)
data = cursor.fetchall()
# 下面为将获取的数据转化为 dataframe 格式
columnDes = cursor.description #获取连接对象的描述信息
#print("cursor.description中的内容:",columnDes)
columnNames = [columnDes[i][0] for i in range(len(columnDes))] #获取列名
df = pd.DataFrame([list(i) for i in data],columns=columnNames) #得到的data为二维元组,逐行取出,转化为列表,再转化为df
print(df)
"""
db.commit()若对数据库进行了修改,需进行提交之后再关闭
"""
# 提交到数据库执行
#db.commit()
#print("OK")
except:
# 如果发生错误则回滚
db.rollback()
print("失败")
"""
使用完成之后需关闭游标和数据库连接,减少资源占用,cursor.close(),db.close()
db.commit()若对数据库进行了修改,需进行提交之后再关闭
"""
# 关闭数据库连接
cursor.close()
db.close()
return df
(3) 做定时任务
## 定时任务
import time
from apscheduler.schedulers.blocking import BlockingScheduler
def job():
dt = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time()))
print('{} --- {}'.format(text, t))
database = 'sys' #数据库名称
password = 'sys' #数据库用户密码
db = connect_database(database, password)
data_sp = read_data(db)
data_sp.to_excel('../data/data_ans.xlsx', sheet_name='未下单情况')
scheduler = BlockingScheduler()
# 在每天22和23点的25分,运行一次 job 方法
scheduler.add_job(job, 'cron', hour='22-23', minute='25')
scheduler.start()
## 测试
# 执行任务
def time_printer():
# 输出时间
now = datetime.datetime.now()
ts = now.strftime('%Y-%m-%d %H:%M:%S')
print('do func time :', ts)
# 定时任务
def loop_monitor():
while True:
time.sleep(20) # 暂停20秒
if __name__ == "__main__":
loop_monitor()
打开data_ans的excel文件即可查看数据。
程序需要一直运行,如果因为关机导致程序终止,需要重新运行。
三、python处理
python处理。具体实现过程如下:
(1) 导入excel数据并利用python完成数据查询,以excel的形式导出查询好的数据。
参考
import pandas as pd
def taskTime():
## 1. 分别导入2个表的数据
product = pd.read_excel('d:/python_code/crontab/data/taskdata.xlsx', sheet_name='商品') # 换成自己的路径和sheet名称
order = pd.read_excel('d:/python_code/crontab/data/taskdata.xlsx', sheet_name='订单')
## 2. 抽取数据
product=product.rename(columns={'UPC':'ID'}) # 对商品表里面的UPC重命名未ID(为了保留订单表里面的CPU着一列)
PO=pd.merge(product,order,left_on='ID', right_on='UPC',how='left') # 左连接抽取数据
PO.loc[pd.isnull(PO['UPC']), '下单情况'] = '未下单' # 找到选中但是未下单的数据标注为未下单
PO['下单情况'] = PO['下单情况'].fillna(value='下单') # 找到下单的数据,在'下单情况'这一列中标注为下单
## 3. 以excel的形式导出查询好的数据
PO = PO.loc[:, ['ID', 'UPC', '下单情况', '产品名称E', '产品参数C', '价格', '建议零售价','订单日期', '品牌', 'PO#', 'SKU','配置', '单价', '数量', '销售金额', '成本单价', '成本', '成本价含税/未税']] # 按列名导出需要的数据
PO.to_excel('d:/python_code/crontab/data/data_python.xlsx', sheet_name='未下单情况') # 导出excel表
return PO
if __name__ == "__main__":
taskTime()
print('执行成功')
(2) 定时处理
## 2. 定时处理
import datetime
from apscheduler.schedulers.blocking import BlockingScheduler
def job():
now = datetime.datetime.now()
ts = now.strftime('%Y-%m-%d %H:%M:%S')
print('执行时间 :', ts) # 输出时间
taskTime() # 执行代码
scheduler = BlockingScheduler() ## 定时
# 在每天17和23点的25分,运行一次 job 方法
scheduler.add_job(job, 'cron', hour='17-23', minute='22')
scheduler.start()
打开data_python的excel文件即可查看数据。
程序需要一直运行,如果因为关机导致程序终止,需要重新运行。
四、优化python处理
1.手动执行代码
如果电脑需要关机,这时候代码不能一直运行,只能在需要数据的时候执行一下代码。有以下2个执行方法:
(1)用命令行执行代码,具体操作如下:
win + R 输入cmd 再输入 路径以及文件名
python d:\python_code\crontab\code\test.py
见下图
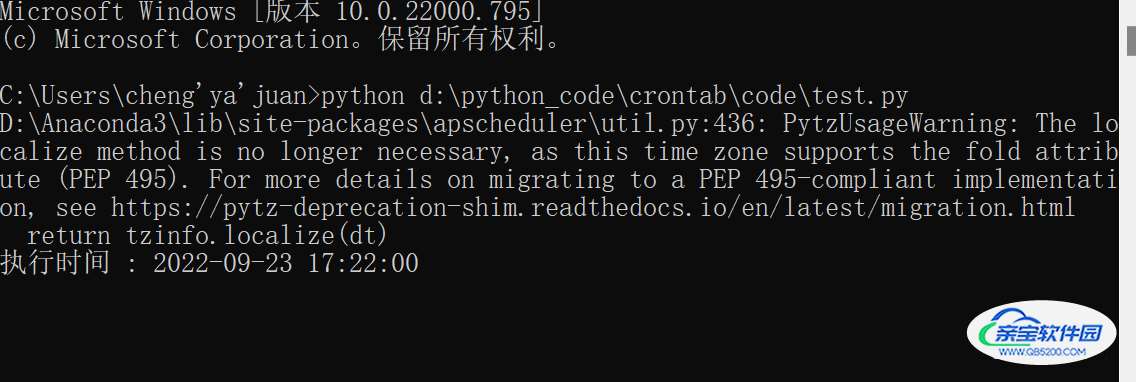
注意:数据还有代码的路径要写对
如果不想用命令行。直接用.bat文件执行也可以。
首先,需要新建一个.bat文件(用来运行脚本),在这个文件里面写上如下代码后保存:
python 路径\文件名.py

将这个文件放到桌面,使用时点击即可。
2.开机自动执行代码
将已经保存的.bat文件复制到该目录(C:\Users\Administrator\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup)下,可能杀毒软件会阻止,选择允许,然后重启电脑即可。
注:开机自启以后会打开一个cmd窗口,关闭窗口,python程序将停止运行。
注意:开启自启动可能会让电脑变慢、发热。。。
对比四种方案
| 方案名称 | 优点 | 缺点 |
|---|---|---|
| SQL查询 | 代码简单,实现简单 | 数据一旦更新需要执行导入导出excel的操作。并且需要手动操作,不能自动提醒。 |
| SQL、python处理 | 避免导出excel;可以自动提醒 | 还是需要导入excel;同时操作SQL和python;自动提醒需要程序一直运行 |
| python处理 | 避免导入导出;可以自动提醒,只操作python | 查询时的处理不好做(对新手来说);自动提醒需要程序一直运行 |
| 优化python处理 | 避免导入导出;自动提醒不需要程序一直运行,开机自启动 | 需要配置一下 |
总结
在没有服务器,以excel存储数据的情况下,同样可以利用SQL和python来做数据处理和分析,在遇到excel处理数据特别麻烦的时候可以选择上面的方案做处理,即可以锻炼自己的SQL和python编程的能力,又可以高效地解决问题。
加载全部内容