解读requests.session()获取Cookies全过程
MicoJack Honey 人气:0通过requests.session()查看默认配置下请求头
import requests
session = requests.session()
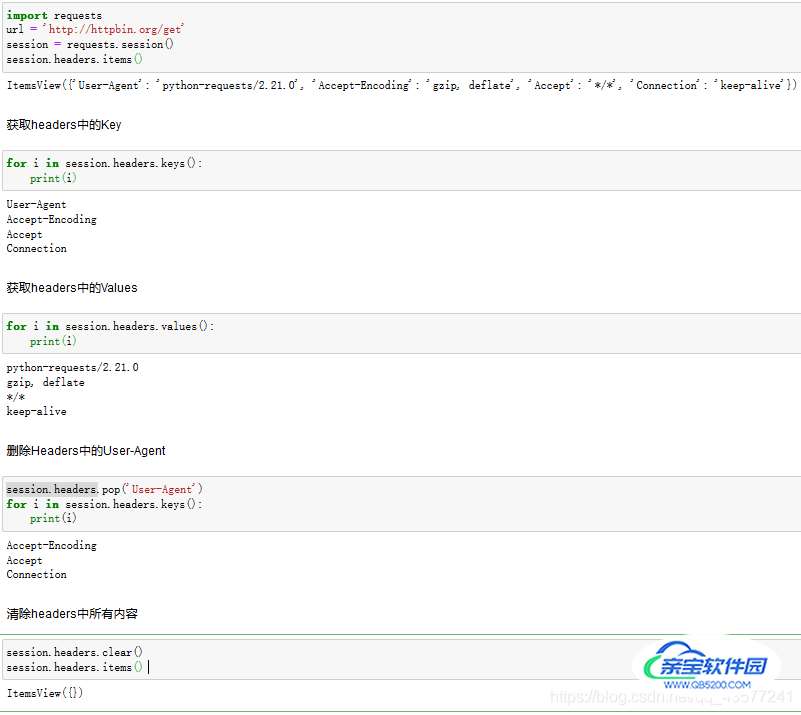
print("默认配置下的请求头:",session.headers.items())
# 默认配置下的请求头:
ItemsView({'User-Agent': 'python-requests/2.21.0',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'})"我们可以看到在默认情况下,请求头的内容很机器,没有灵性。
如果大家使用的IDE是Pycharm的话,ctrl+右键点击session.headers的headers查看源码。
得到如图:

使用的是default_headers()(默认请求头),这里我们依然看不到print打印在终端的内容,所以继续ctrl+右击点击default_headers()。
得到如图:

OK! But it’s not over,这里我们还有User-Agent的value没有看到,但是经过猜测我们不难得到default_user_agent()的内容就是python-requests/2.21.0。
包装请求头,让他看起来更帅气
首先,了解对headers进行一个简单的增删改查操作
包装

包装我们的Headers
- 方式一
headers = {
'Origin': 'https://***.com',
'Host': '***.com',
'Referer': 'https://**.com/,
'User-Agent': 'Mozilla/5.0',
}
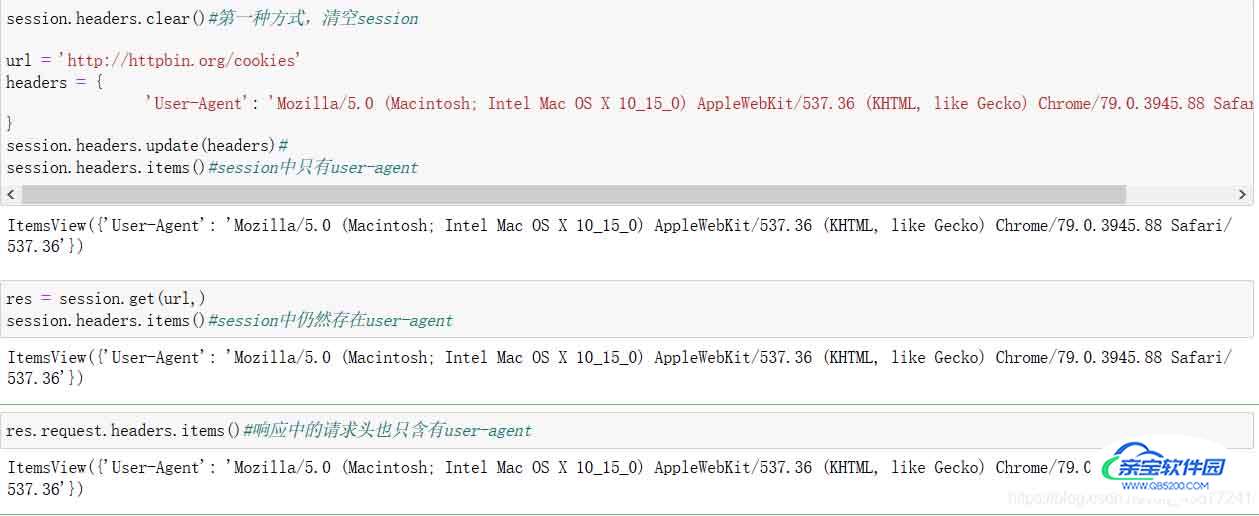
session.headers.update(headers)#字典的更新方法- 方式二
换一种大家都在用的方式,在请求的时候添加headers参数即可:
response = session.get(url, headers=headers)
验证两种方式是否得到的效果一样
- 第一种方式
- 第二种方式
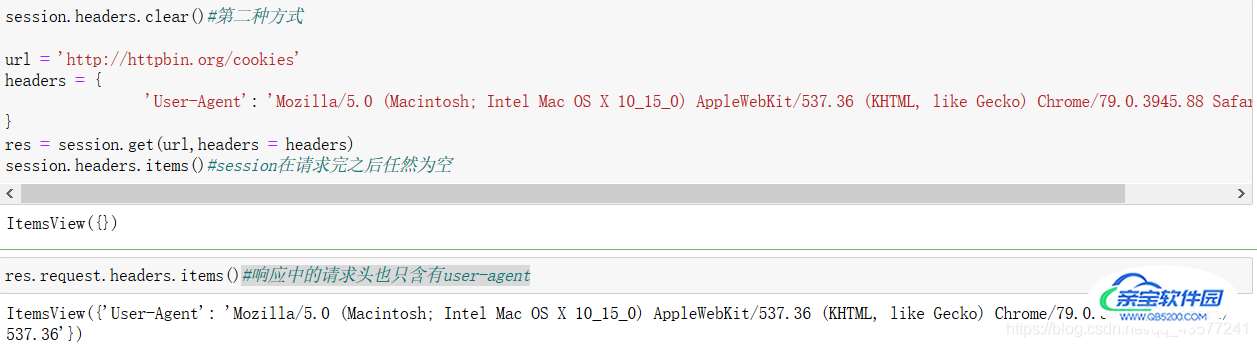
结论:两种方式在response端看到的效果等同,区别在于第一种方式session是永久的,而第二种常用的方式只是在请求的时候携带过去的,所以当我们查看session的时候为空,那么这就有一个问题,我们在后续的请求中任然需要带上headers=这个参数,似乎它并没有那么好?
这是在github上copy 的部分爬虫代码如下:

连续带了两次Headers,这样没有什么不好,你开心就好~~~。
cookies获取过程
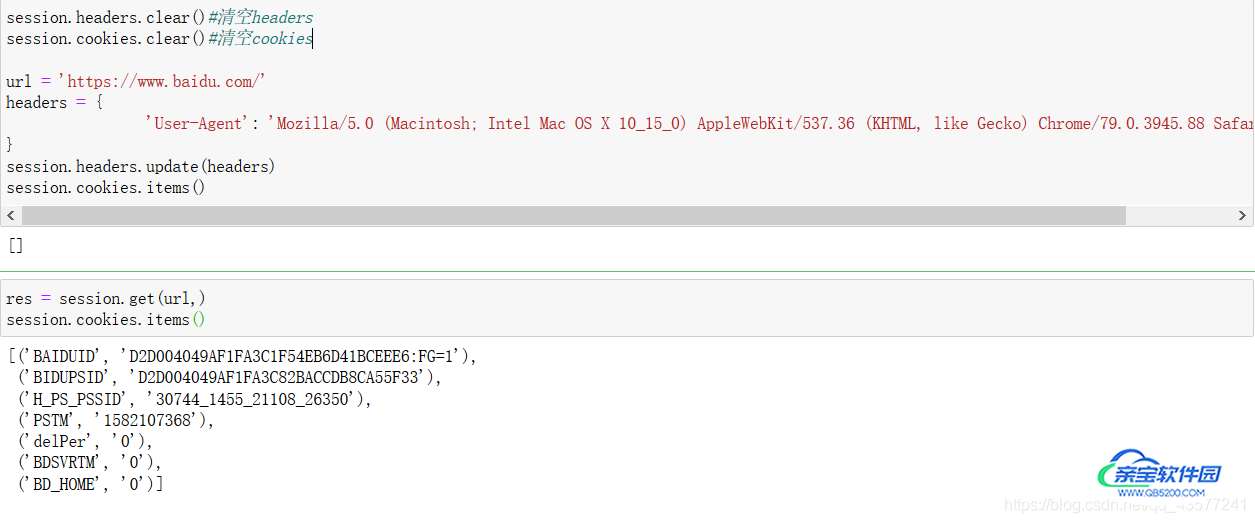
- 请求之前我们先清空
Headers,Cookies内的信息 headers中仅写入user-agent,Cookies为空- 请求之后查看
session中Cookies,得到响应端返回的cookies
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。
加载全部内容