深入解析桶排序算法及Node.js上JavaScript的代码实现
人气:01. 桶排序介绍
桶排序(Bucket sort)是一种基于计数的排序算法,工作的原理是将数据分到有限数量的桶子里,然后每个桶再分别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。当要被排序的数据内的数值是均匀分配的时候,桶排序时间复杂度为Θ(n)。桶排序不同于快速排序,并不是比较排序,不受到时间复杂度 O(nlogn) 下限的影响。
桶排序按下面4步进行:
(1)设置固定数量的空桶。
(2)把数据放到对应的桶中。
(3)对每个不为空的桶中数据进行排序。
(4)拼接从不为空的桶中数据,得到结果。
桶排序,主要适用于小范围整数数据,且独立均匀分布,可以计算的数据量很大,而且符合线性期望时间。
2. 桶排序算法演示
举例来说,现在有一组数据[7, 36, 65, 56, 33, 60, 110, 42, 42, 94, 59, 22, 83, 84, 63, 77, 67, 101],怎么对其按从小到大顺序排序呢?
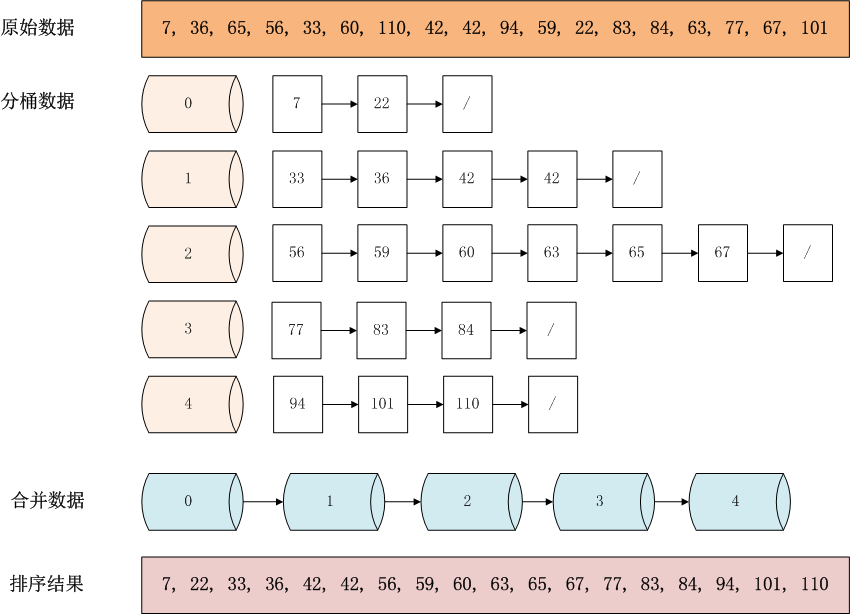
操作步骤说明:
(1)设置桶的数量为5个空桶,找到最大值110,最小值7,每个桶的范围20.8=(110-7+1)/5 。
(2)遍历原始数据,以链表结构,放到对应的桶中。数字7,桶索引值为0,计算公式为floor((7 – 7) / 20.8), 数字36,桶索引值为1,计算公式floor((36 – 7) / 20.8)。
(3)当向同一个索引的桶,第二次插入数据时,判断桶中已存在的数字与新插入数字的大小,按照左到右,从小到大的顺序插入。如:索引为2的桶,在插入63时,桶中已存在4个数字56,59,60,65,则数字63,插入到65的左边。
(4)合并非空的桶,按从左到右的顺序合并0,1,2,3,4桶。
(5)得到桶排序的结构
3. Nodejs程序实现
像桶排序这种成熟的算法,自己实现一下并不难,按照上文的思路,我写了一个简单的程序实现。我感觉其中最麻烦的部分,是用Javascript操作链表。
现实代码如下:
'use strict';
/////////////////////////////////////////////////
// 桶排序
/////////////////////////////////////////////////
var _this = this
, L = require('linklist');//链表
/**
* 普通数组桶排序,同步
*
* @param arr Array 整数数组
* @param num 桶的个数
*
* @example:
* sort([1,4,1,5,3,2,3,3,2,5,2,8,9,2,1],5)
* sort([1,4,1,5,3,2,3,3,2,5,2,8,9,2,1],5,0,5)
*/
exports.sort = function (arr, count) {
if (arr.length == 0) return [];
count = count || (count > 1 ? count : 10);
// 判断最大值、最小值
var min = arr[0], max = arr[0];
for (var i = 1; i < arr.length; i++) {
min = min < arr[i] ? min : arr[i];
max = max > arr[i] ? max : arr[i];
}
var delta = (max - min + 1) / count;
// console.log(min+","+max+","+delta);
//初始化桶
var buckets = [];
//存储数据到桶
for (var i = 0; i < arr.length; i++) {
var idx = Math.floor((arr[i] - min) / delta); // 桶索引
if (buckets[idx]) {//非空桶
var bucket = buckets[idx];
var insert = false;//插入标石
L.reTraversal(bucket, function (item, done) {
if (arr[i] <= item.v) {//小于,左边插入
L.append(item, _val(arr[i]));
insert = true;
done();//退出遍历
}
});
if (!insert) { //大于,右边插入
L.append(bucket, _val(arr[i]));
}
} else {//空桶
var bucket = L.init();
L.append(bucket, _val(arr[i]));
buckets[idx] = bucket; //链表实现
}
}
var result = [];
for (var i = 0, j = 0; i < count; i++) {
L.reTraversal(buckets[i], function (item) {
// console.log(i+":"+item.v);
result[j++] = item.v;
});
}
return result;
}
//链表存储对象
function _val(v) {
return {v: v}
}
运行程序:
var algo = require('./index.js');
var data = [ 7, 36, 65, 56, 33, 60, 110, 42, 42, 94, 59, 22, 83, 84, 63, 77, 67,101 ];
console.log(data);
console.log(algo.bucketsort.sort(data,5));//5个桶
console.log(algo.bucketsort.sort(data,10));//10个桶
输出:
[ 7, 36, 65, 56, 33, 60, 110, 42, 42, 94, 59, 22, 83, 84, 63, 77, 67, 101 ] [ 7, 22, 33, 36, 42, 42, 56, 59, 60, 63, 65, 67, 77, 83, 84, 94, 101, 110 ] [ 7, 22, 33, 36, 42, 42, 56, 59, 60, 63, 65, 67, 77, 83, 84, 94, 101, 110 ]
需要说明的是:
(1)桶内排序,可以像程序中所描述的,在插入过程中实现;也可以插入不排序,在合并过程中,再进行排序,可以调用快度排序。
(2)链表,在Node的底层API中,有一个链表的实现,我没有直接使用,而是通过linklist包调用的:https://github.com/nodejs/node-v0.x-archive/blob/master/lib/_linklist.js
4. 案例:桶排序统计高考分数
桶排序最出名的一个应用场景,就是统计高考的分数。一年的全国高考考生人数为900万人,分数使用标准分,最低200 ,最高900 ,没有小数,如果把这900万数字进行排序,应该如何做呢?
算法分析:
(1)如果使用基于比较的排序,快速排序,平均时间复杂度为O(nlogn) = O(9000000*log9000000)=144114616=1.44亿次比较。
(2)如果使用基于计数的排序,桶排序,平均的时候复杂度,可以控制在线性复杂度,当创建700桶时从200分到900分各一个桶,O(N)=O(9000000),就相当于扫描一次900W条数据。
我们跑一个程序,对比一次快速排序和桶排序。
//产生100W条,[200,900]闭区间的数据
var data = algo.data.randomData(1000*1000,200,900);
var s1 = new Date().getTime();
algo.quicksort.sort(data);//快速排序
var s2 = new Date().getTime();
algo.bucketsort.sort(data,700);//装到700个桶
var s3 = new Date().getTime();
console.log("quicksort time: %sms",s2-s1);
console.log("bucket time: %sms",s3-s2);
输出:
quicksort time: 14768ms bucket time: 1089ms
所以,对于高考计分的案例来说,桶排序是更适合的!我们把合适的算法,用在适合的场景,会给程序带来超越硬件的性能提升。
5. 桶排序代价分析
BUT....
桶排序利用函数的映射关系,减少了几乎所有的比较工作。实际上,桶排序的f(k)值的计算,其作用就相当于快排中划分,已经把大量数据分割成了基本有序的数据块(桶)。然后只需要对桶中的少量数据做先进的比较排序即可。
对N个关键字进行桶排序的时间复杂度分为两个部分:
(1) 循环计算每个关键字的桶映射函数,这个时间复杂度是O(N)。
(2) 利用先进的比较排序算法对每个桶内的所有数据进行排序,其时间复杂度为 ∑ O(Ni*logNi) 。其中Ni 为第i个桶的数据量。
很显然,第(2)部分是桶排序性能好坏的决定因素。尽量减少桶内数据的数量是提高效率的唯一办法(因为基于比较排序的最好平均时间复杂度只能达到O(N*logN)了)。因此,我们需要尽量做到下面两点:
(1) 映射函数f(k)能够将N个数据平均的分配到M个桶中,这样每个桶就有[N/M]个数据量。
(2) 尽量的增大桶的数量。极限情况下每个桶只能得到一个数据,这样就完全避开了桶内数据的“比较”排序操作。 当然,做到这一点很不容易,数据量巨大的情况下,f(k)函数会使得桶集合的数量巨大,空间浪费严重。这就是一个时间代价和空间代价的权衡问题了。
对于N个待排数据,M个桶,平均每个桶[N/M]个数据的桶排序平均时间复杂度为:
O(N)+O(M*(N/M)*log(N/M))=O(N+N*(logN-logM))=O(N+N*logN-N*logM)
当N=M时,即极限情况下每个桶只有一个数据时。桶排序的最好效率能够达到O(N)。
6. 总结
桶排序的平均时间复杂度为线性的O(N+C),其中C=N*(logN-logM)。如果相对于同样的N,桶数量M越大,其效率越高,最好的时间复杂度达到O(N)。 当然桶排序的空间复杂度 为O(N+M),如果输入数据非常庞大,而桶的数量也非常多,则空间代价无疑是昂贵的。此外,桶排序是稳定的。
其实我个人还有一个感受:在查找算法中,基于比较的查找算法最好的时间复杂度也是O(logN)。比如折半查找、平衡二叉树、红黑树等。但是Hash表却有O(C)线性级别的查找效率(不冲突情况下查找效率达到O(1))。大家好好体会一下:Hash表的思想和桶排序是不是有一曲同工之妙呢?
加载全部内容