大咖分享| 百度语义技术及应用全解
百度ERNIE 人气:1分享嘉宾:孙宇,百度NLP主任研发架构师、语义计算技术负责人。
本文根据作者在“2019自然语言处理前沿论坛”语义理解主题的特邀报告整理而成。
本报告提纲分为以下3个部分:
· 语义表示
· 语义匹配
· 未来重点工作
语义计算方向在百度NLP成立之初就开始研究,研究如何利用计算机对人类语言的语义进行表示、分析和计算,使机器具备语义理解能力。相关技术包含语义表示、语义匹配、语义分析、多模态计算等。
本文主要介绍百度在语义表示方向的技术发展和最新的研究成果艾尼(ERNIE),同时也会介绍工业应用价值很大、百度积累多年的语义匹配SimNet的相关内容,最后再谈谈未来的重点工作。
一、语义表示
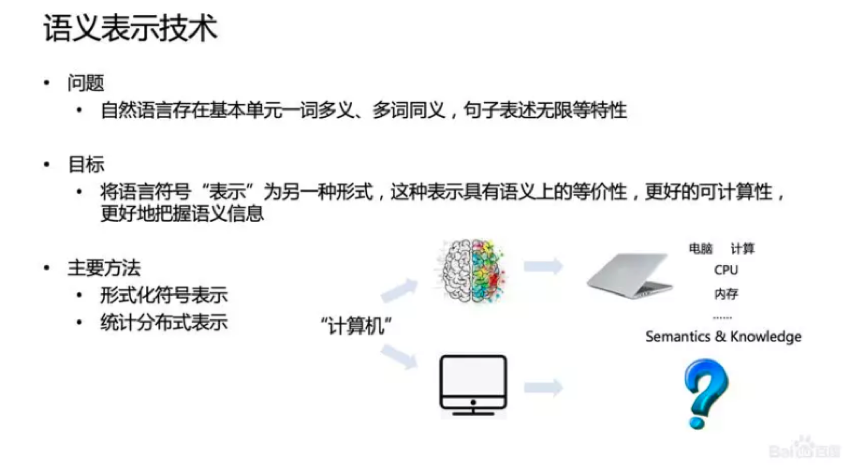
计算机理解语言是一个具有很大挑战的问题。人类在理解语言的过程中,除了语言符号本身的识别,还包含符号背后的语义和知识。举个例子,当人看到“计算机”这个符号时,脑子里能迅速浮现出计算机的画面以及和计算机相关的知识和概念,但是这对于计算机就比较困难。所以如何让计算机能够表示语言是研究的重点,让其既能够蕴含语义信息又可以计算。
当前主要有两类方法,一是基于形式化规则的方法,如通过构建语义关系网络来描述语义的信息;二是基于统计的方法,包括主题模型、Word Embedding等技术。
1、百度早期语义表示技术:基于检索的表示方法

2007年百度便开始语义表示研究,最开始的思路是利用搜索引擎来完成。通过搜索引擎把要表示的句子或者词语检索出来,再根据检索的结果通过Term的分析以及网页的分析,把相关的词、信息抽取出来,做成语言符号的表示。但是这个表示实际上停留在原始词汇空间,表示的空间大小依然是词表的维度,只是相对于One-Hot的表示来说更精细,这个方法是基于1954年Harris提出来的“上下文相似的词,其语义也相似”的假设。
2、百度早期语义表示技术:Topic Model
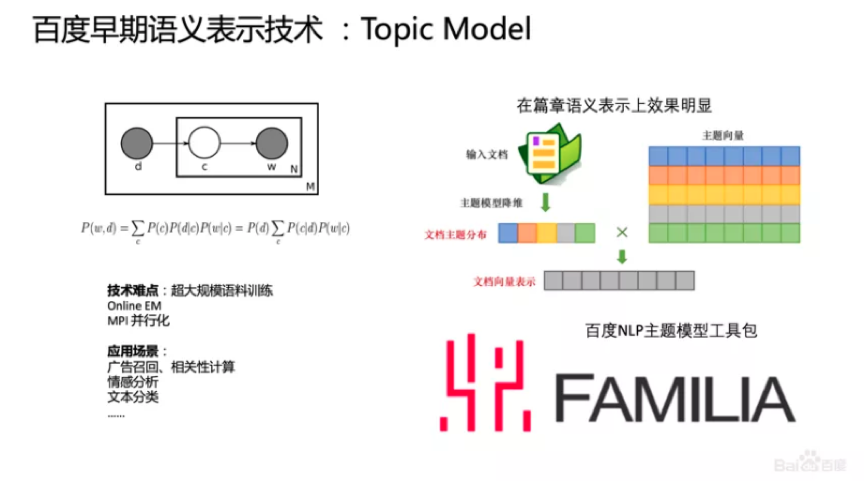
此后,百度又研究了Topic Model的语义表示技术,这种方法的核心思路是把文档词汇空间降维,将文档映射到浅层主题的分布上,而这种主题空间要比词的分布空间更小一些。通过降维的方法,可以得到每个词到主题的映射,通过这种主题的方法做语义的表示。
当时百度主要解决的问题是怎样做这种新文档的表示,难点是超大规模语料训练、Online EM、MPI并行化。此外,百度还将自研的主题模型以及一些主流的主题模型整理为工业应用工具,对外开源了百度NLP主题模型工具包FAMILIA。
3、基于DNN的语义表示技术:Word Embedding
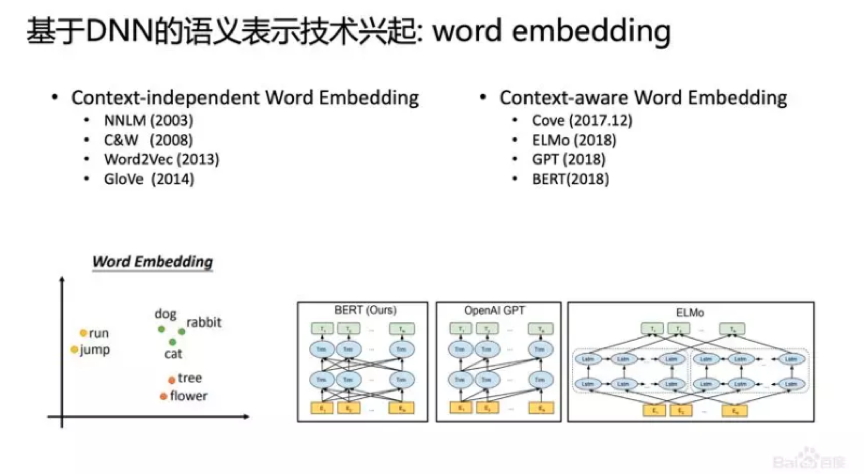
深度学习技术兴起,基于Word Embedding的表示占了主流,此类技术在各种NLP任务中也表现出色。从NNLM到现在BERT的技术,取得了很多进展。2013年的Word2vec成为NLP标配性的初始化向量,2018年有了上下文相关的词向量ELMo等。
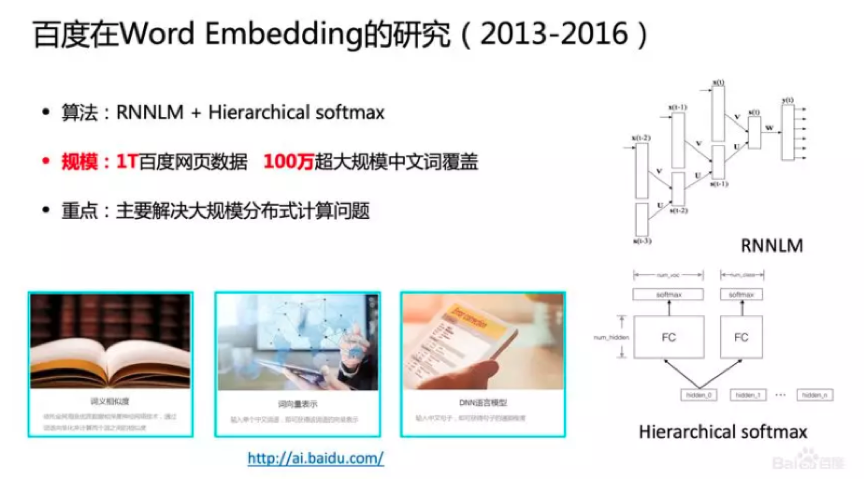
从2013年到2016年,百度也大力投入到Word Embedding的研究,主要研究工作是在工业界如何用大规模分布式从海量数据中计算词向量。比如,怎么才能高效训练规模为1T的语料?如何构建大规模分布式文本计算?此外,算法上我们也有一些研究,比如,如何在一百万超大规模的词表里完成Softmax分类?我们通过一些策略和技术,做成启发式Hierarchical Softmax的方法,从而有效地提升分类的效率。2016年,百度把训练的1T的网页数据和100万词表规模的词向量对业界进行了开放。
4、多特征融合的表示模型
BERT的核心思路还是大力出奇迹,它利用了大规模的无监督数据,同时借助Transformer这种高性能的Encoder的能力,在MASK建模任务上做了一些优化,导致这个效果能够在各个任务上显著提升。
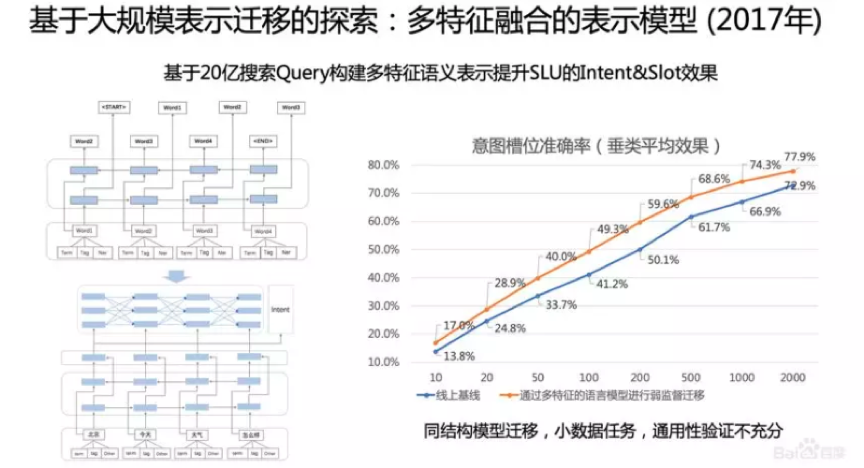
百度实际在2017年进行了这方面的探索,当时是研究基于对话的口语理解问题,这个问题的核心是做意图的分类和槽位的标注。难点在于口语理解的问题标注语料非常少。当时想能不能利用海量的搜索语料做Pre-Training,把这个Model作为初始化模型用到下游的SLU任务里。
我们采用20亿搜索的Query,通过LSTM模型做单向Language Model的预训。我们发现在SLU任务上,在各个垂类上样本数的增加非常显著,从10个样本到2000个样本。但遗憾的是,当时研究的是一个超小规模数据上效果,即2000的数据,在2万甚至是20万的数据上的表现并没有研究,同时在其他应用的通用性上的研究也不够充分。
5、知识增强的语义表示模型
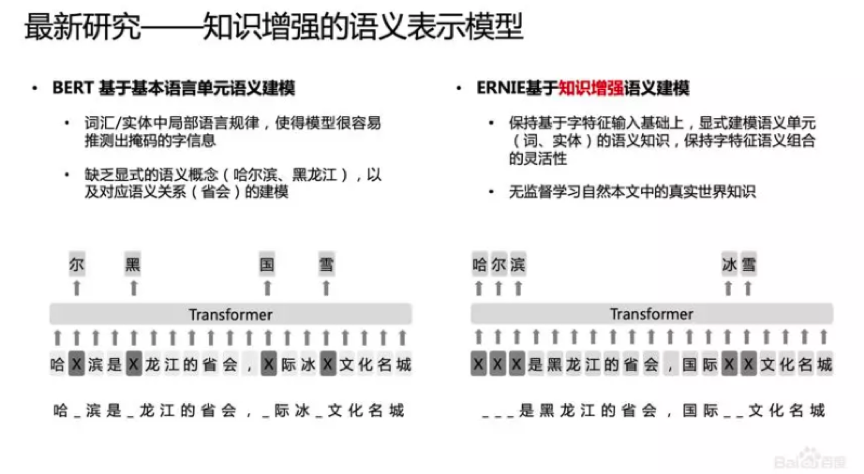 BERT提出后,我们发现一个问题,它学习的还是基础语言单元的Language Model,并没有充分利用先验语言知识,这个问题在中文很明显,它的策略是MASK字,没有MASK知识或者是短语。在用Transformer预测每个字的时候,很容易根据词包含字的搭配信息预测出来。比如预测“雪”字,实际上不需要用Global的信息去预测,可以通过“冰”字预测。基于这个假设,我们做了一个简单的改进,把它做成一个MASK词和实体的方法,学习这个词或者实体在句子里面Global的信号。
BERT提出后,我们发现一个问题,它学习的还是基础语言单元的Language Model,并没有充分利用先验语言知识,这个问题在中文很明显,它的策略是MASK字,没有MASK知识或者是短语。在用Transformer预测每个字的时候,很容易根据词包含字的搭配信息预测出来。比如预测“雪”字,实际上不需要用Global的信息去预测,可以通过“冰”字预测。基于这个假设,我们做了一个简单的改进,把它做成一个MASK词和实体的方法,学习这个词或者实体在句子里面Global的信号。
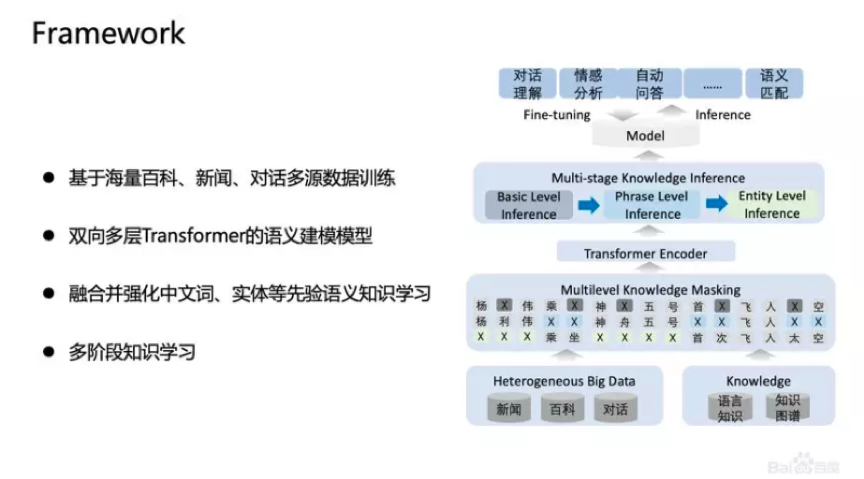
基于上述思想我们发布了基于知识增强的语义表示ERNIE(1.0)。

我们在中文上做了ERNIE(1.0)实验,找了五个典型的中文公开数据集做对比。不管是词法分析NER、推理、自动问答、情感分析、相似度计算,ERNIE(1.0)都能够显著提升效果。
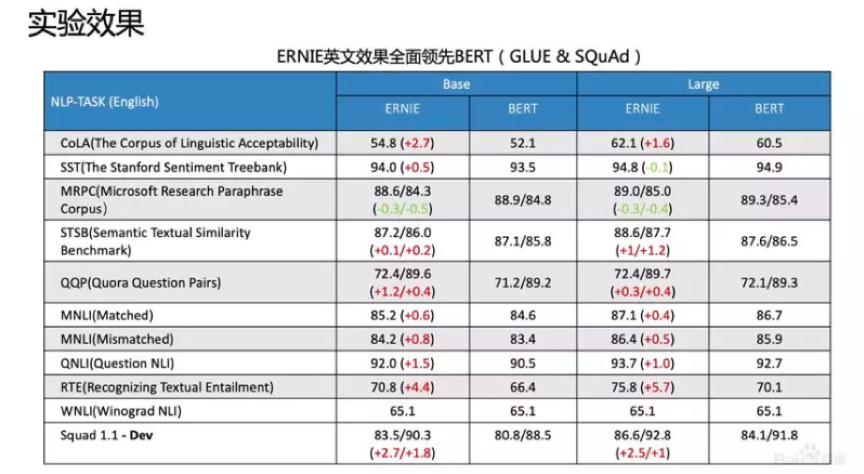
英文上验证了推广性,实验表明ERNIE(1.0)在GLUE和SQuAd1.1上提升也是非常明显的。为了验证假设,我们做了一些定性的分析,找了完形填空的数据集,并通过ERNIE和BERT去预测,效果如上图。
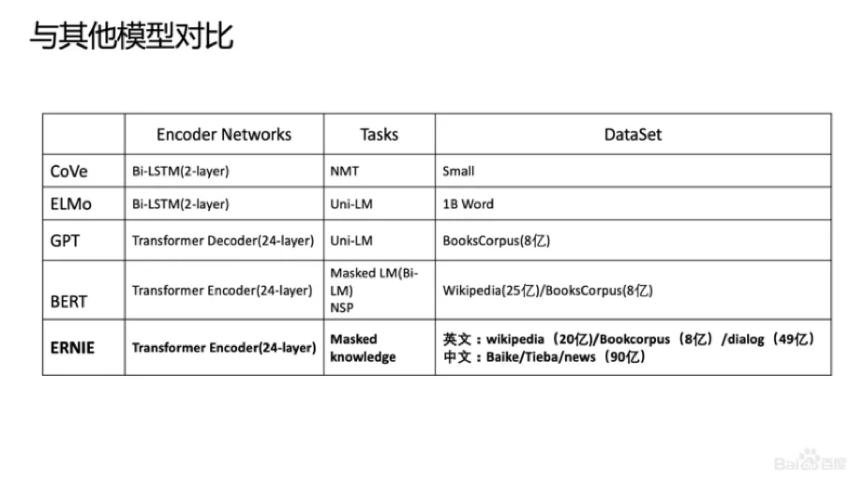
我们对比了ERNIE、BERT、CoVe、GPT、ELMo模型,结果如上图所示。ELMo是早期做上下文相关表示模型的工作,但它没有用Transformer,用的是LSTM,通过单向语言模型学习。百度的ERNIE与BERT、GPT一样,都是做网络上的Transformer,但是ERNIE在建模Task的时候做了一些改进,取得了很不错的效果。
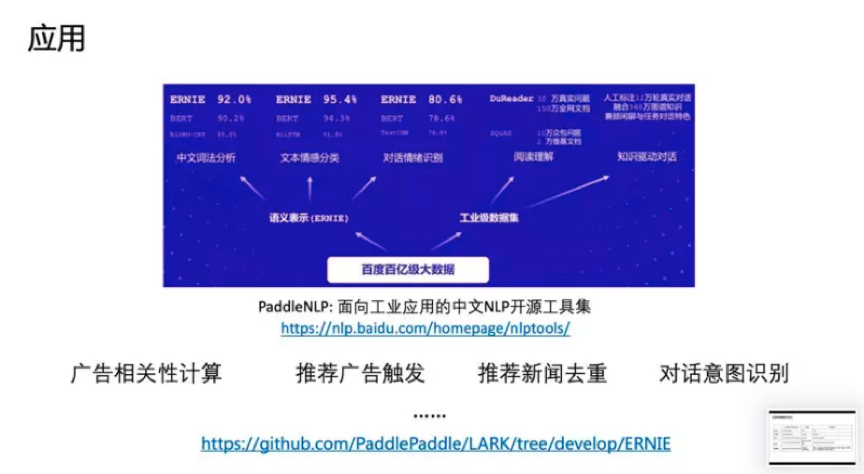
在应用上,ERNIE在百度发布的面向工业应用的中文NLP开源工具集进行了验证,包括ERNIE与BERT在词法分析、情感分类这些百度内部的任务上做了对比分析。同时也有一些产品已经落地,在广告相关性的计算、推荐广告的触发、新闻推荐上都有实际应用。目前模型已经开源(http://github.com/PaddlePaddle/ERNIE),欢迎大家去下载。
7月31日,百度艾尼(ERNIE) 再升级,发布了持续学习语义理解框架ERNIE 2.0,同时借助飞桨(PaddlePaddle)多机多卡高效训练优势发布了基于此框架的ERNIE 2.0 预训练模型。该模型在共计16个中英文任务上超越了BERT 和XLNet,取得了SOTA 效果。
二、语义匹配
1、文本语义匹配及挑战

语义匹配在工业界具有非常大的技术价值,它是一个很基础的问题,很多产品、应用场景都会用到它。很多问题也可以抽象为语义匹配问题,比如,搜索解决的是Query和Document相关性的问题,推荐解决的是User和Item关联度、兴趣匹配度的问题,检索式问答解决的是问题与答案匹配度,以及检索对话Query和Response的匹配问题。由于语言比较复杂,匹配靠传统的方法是比较难的。

百度搜索在匹配相似度计算方面做了较多工作,包括挖掘同义词、词级别泛化、语义紧密度、对齐资源挖掘、共线关联计算等。

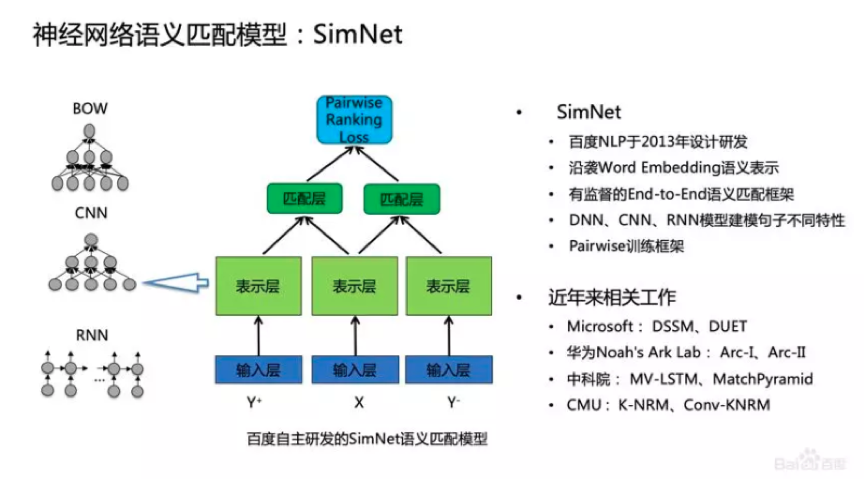
2、神经网络语义匹配模型:SimNet
2013年百度提出SimNet技术,用于解决语义匹配的问题。这个技术基于DNN框架,沿袭Word Embedding的输入,基于End-to-End的训练做表示和匹配,并结合Pairwise训练。当时,微软也提出了DSSM,中科院、CMU等研究机构也做了很多语义匹配研究工作。
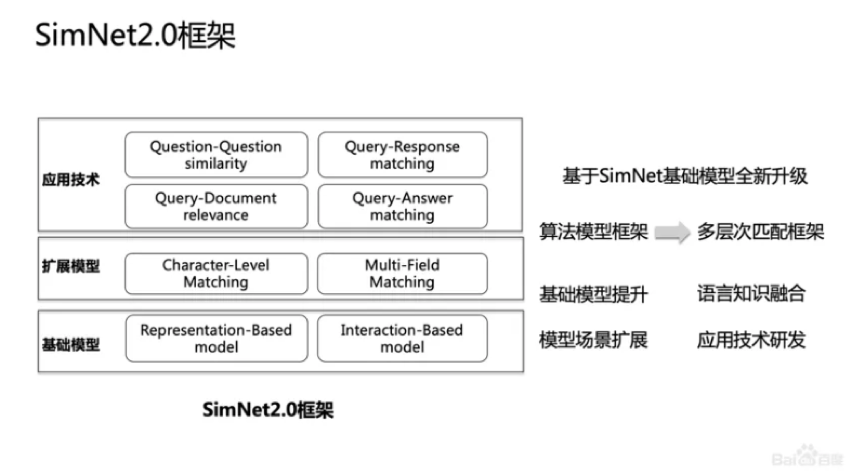
这几年,百度整体上从语义匹配的框架上做了升级,抽象了三个层次,改进了基础算法,包括扩展针对不同场景的模型,比如字和语义的匹配模型;在不同的应用场景,针对问题网页和问题答案的匹配情况分别做了针对性地优化,集成到了匹配框架里。
匹配算法主要有两种范式,一种是基于表示的匹配,首先把自然语言表示成向量,然后再进行相似度计算,这方面也有一些改进,主要是做一些Attention;另一种新匹配范式Interaction-based Model,强调更细的匹配,即一个句子的表示不再是一个向量,而是原来的Term,并把原来的位置信息保留,最后以Attention的方式表示,让匹配更加充分和精细。
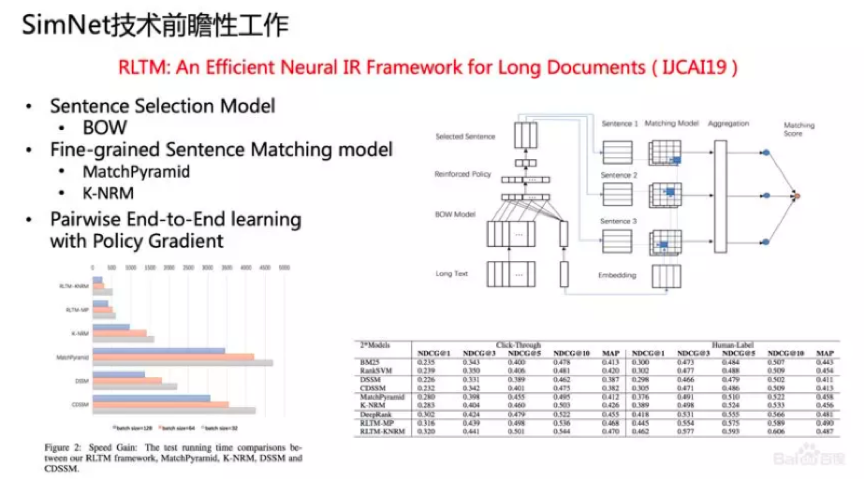
关于SimNet技术前瞻性工作,2019年百度在IJCAI上发表了一篇论文“RLTM:An Efficient Neural IR Framework for Long Documents”,其中长文本匹配有一个很大的挑战,就是让Document直接做表示,如果文本太长,很多信息会丢失,计算效率也非常低。但如果我们先做一个粗匹配,选择好相关的句子以后再做精细化的匹配,效果就比较不错。
3、SimNet的应用
SimNet技术在百度应用非常广泛,包括搜索、资讯推荐、广告、对话平台都在使用。
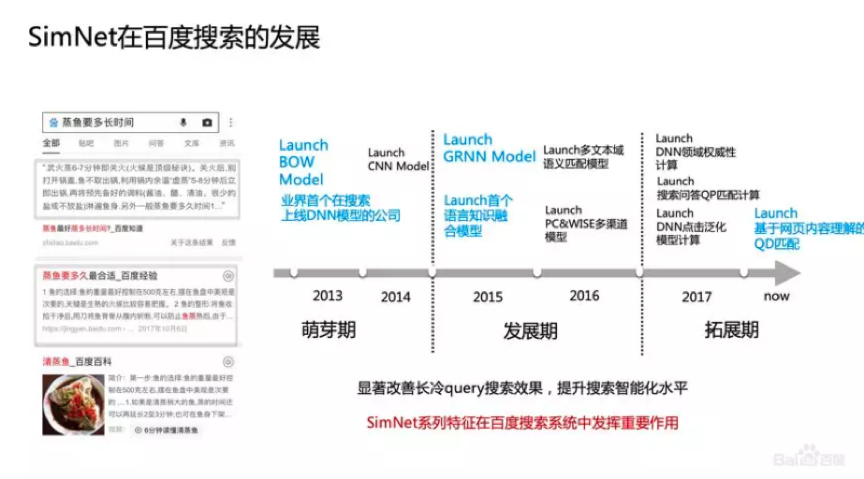
搜索是百度非常重要的产品,搜索有两个核心功能,下图的左侧上方是搜索的精准问答,通过问答技术把精准答案直接呈现出来;下方是自然排序,主要采用LTR框架和相关性、权威性、时效性等Features。
SimNet在百度搜索的发展可以分为三个时期。萌芽期,上线了BOW Model,这是业界第一次在搜索引擎上线DNN模型;发展期,做了CNN、RNN,并把知识融合进RNN,在语义相关性计算中,除了标题很多其他文本域在相关性建模中也很重要,所以,我们还做多文本域融合匹配的Model;拓展期,除了相关性,在权威性、点击模型和搜索问答上都有推广和使用。
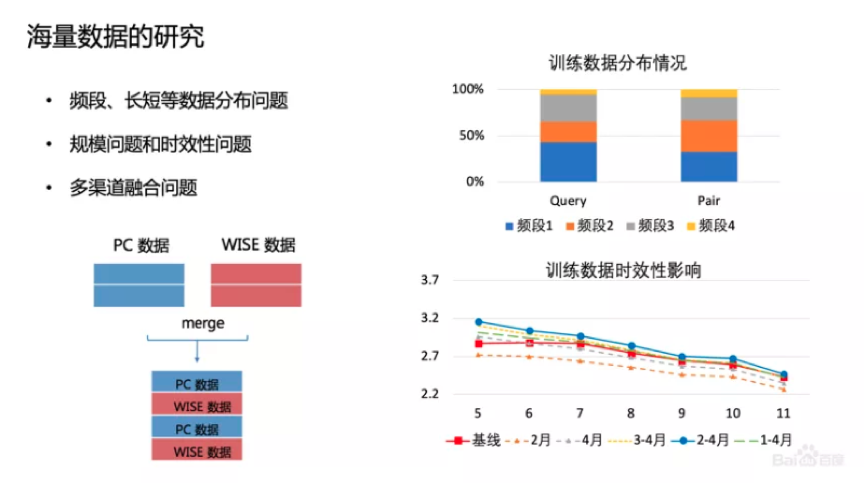
在搜索中,SimNet是用超大规模用户反馈数据训练。那么如何依靠海量数据来提升效果?频次如何选?我们发现模型应用效果并不是静态的,而是动态变化的,特别是搜索反馈的数据,随着时间的推移,网民在搜索的时候,Term的分布、主题的分布会发生变化,所以数据的时效性影响还是非常大的。
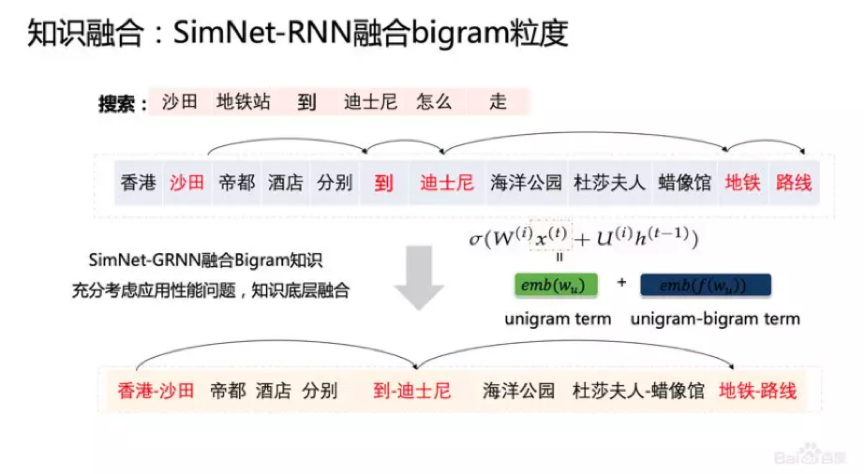
除了模型上的融合,我们把Bigram知识也融入了进去。尽管RNN已经很厉害了,但加入知识、模型还是会有很大地提升。
4、新模型:SimNet-QC-MM
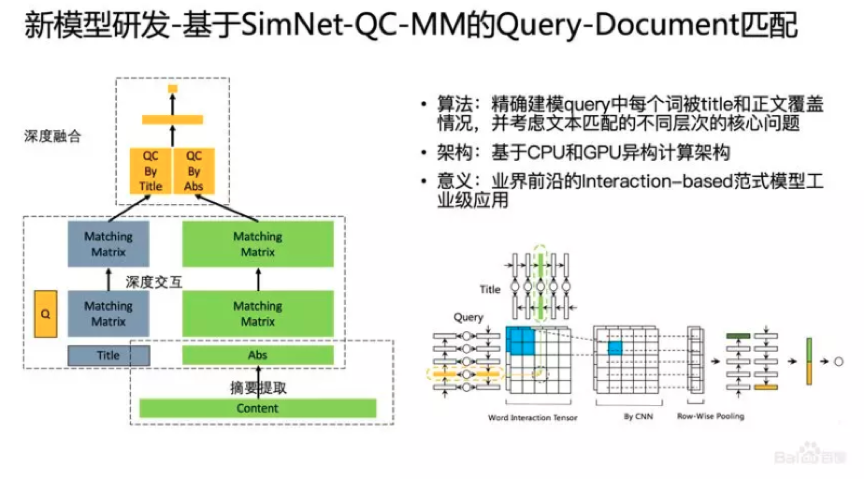
另外,我们还做了Query和网页正文的建模,由于Query中每个词都有一定的用户意图,所以在模型建模时,会考虑Query中每个词被Title和正文覆盖的情况,并基于Matching Matrix匹配方法计算。此外,搜索架构也做了配合改进,搜索也上线了基于GPU和CPU的异构计算架构。

上图是一个案例,“芈殊出嫁途中遇到危险”,我们后来做了一些分析,发现“危险”和“投毒”有很强的语义关联,就把这个结果排了上去。
5、语义模型压缩技术
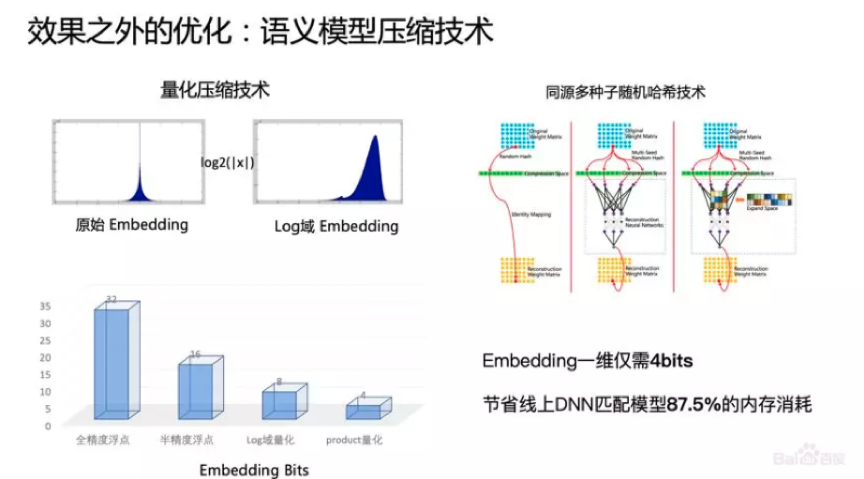
在模型裁减压缩上,我们也做了很多工作,包括量化的压缩和哈希技术的压缩。整个语义的模型基本上已经从依靠一个Embedding 32bits来存,到现在达到Embedding一维仅需4bits,节省线上DNN匹配模型87.5%的内存消耗。这项技术,除了搜索的使用,移动端的使用也有非常大的价值。
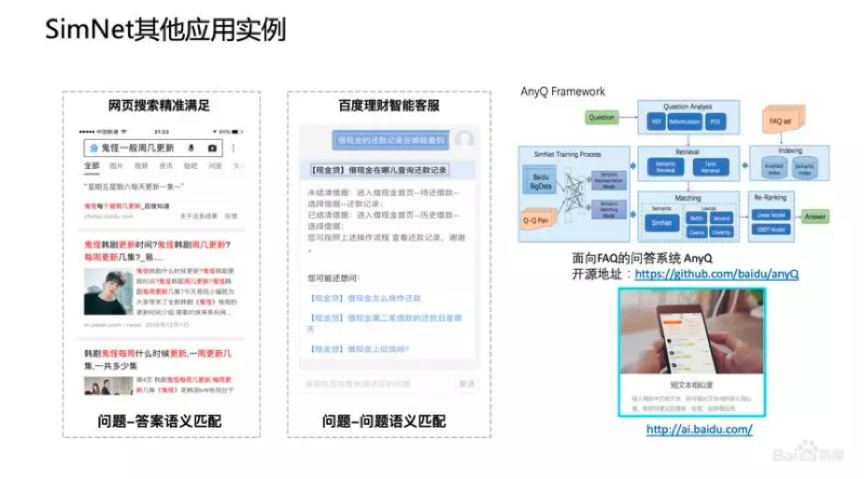
SimNet技术除了百度搜索,包括Q&A,Query和Answer的匹配等方面都有一些尝试。
三、未来重点工作
接下来我们会在通用语义表示方面进一步研究与突破,除了如何充分地利用先验知识,利用一些弱监督信号外,模型方面也会进一步探索创新。技术拓展上,跨语言、多语言表示,面向生成、匹配等任务的表示,面向医疗、法律等领域的表示,多模态表示等都是我们的一些重点方向。
RLTM论文地址:
https://arxiv.org/abs/1906.09404
至此,“2019自然语言处理前沿论坛”语义计算主题《百度语义计算技术及其应用》的分享结束。如果大家想更深入地了解百度持续学习语义理解框架艾尼(ERNIE),欢迎加入ERNIE官方交流群(QQ群号:760439550)。
-------------------
划重点!!!
扫码关注百度NLP官方公众号,获取百度NLP技术的第一手资讯!
加入ERNIE官方技术交流群(760439550),百度工程师实时为您答疑解惑!
立即前往GitHub( github.com/PaddlePaddle/ERNIE )为ERNIE点亮Star,马上学习和使用起来吧! 
最强预告!!!
11月23日,艾尼(ERNIE)的巡回沙龙将在上海加场,干货满满的现场,行业A级的导师,还有一群志同道合的小伙伴,还在等什么?感兴趣的开发者们赶紧扫描下方“二维码”或点击“链接”报名参加吧!

报名链接:https://iwenjuan.baidu.com/?code=vc78lp
加载全部内容