从5大挑战带你了解多模态机器学习
华为云开发者社区 人气:0摘要:多模态机器学习旨在从多种模态建立一种模型,能够处理和关联多种模态的信息。考虑到数据的异构性,MMML(Multimodal Machine Learning)领域带来了许多独特的挑战,总体而言五种:表示、转化、对齐、融合、协同学习。
本文分享自华为云社区《多模态学习综述》,原文作者:Finetune小能手。
前言
一种模态指事物发生或体验的方式,关于多模态研究的问题就是指包含多种模态。
多模态机器学习旨在从多种模态建立一种模型,能够处理和关联多种模态的信息
考虑到数据的异构性,MMML(Multimodal Machine Learning)领域带来了许多独特的挑战,总体而言五种:
- 表示:最为基础的挑战,学习利用多种模态的互补性和冗余性,来表示和概括模态数据的方法。模态的异构性为这种表示带来挑战。例如:语言通常是符号表示,而语音通常是信号表示。
- 转化:如何转换(映射)一种模态的数据到另一种模态。多模态不仅数据异构,而且模态间的关系通常是开放的或者说是主观的。例如,有许多种正确的方法来描述一张图片,其中可能并不存在最好的模态转译。
- 对齐:模态对齐主要是识别多种模态的要素(子要素)间的直接联系。例如,将菜谱的每一步和做菜的视频进行对应。解决这个问题需要衡量不同模态的间的相似性,而且要考虑可能的长距离依赖和歧义。
- 融合:将多种模态的信息进行连接,从而完成推理。例如,视听语音识别,视觉描述的嘴唇的运动与音频信号进行混合来完成所说的词的推理。当可能至少一种模态数据丢失的时候,来自不同模态的信息在推理中有不同的预测能力和噪声拓扑。
- 协同学习:在不同模态、表示、预测模型间进行知识迁移。协同训练、conceptual grounding和zero-shot learning中有典型应用。当某一种模态资源有限时(标注数据很少)有很大意义。
应用:应用很多,包括视听语音识别(AVSR),多媒体数据索引和搜索,社交互动行为理解,视频描述等
一、多模态表示
多模态表示需解决问题:异构数据如何结合,不同级别的噪声如何处理,丢失数据如何处理
Bengio指出,好的特征表示应该:
- 平滑
- 时空一致
- 稀疏
- 自然聚类
Srivastava et.al.补充三点
- 表征空间应该反映对应概念相似性
- 即便一些模态不存在,表征应该易于获得
- 使填充丢失的模态成为可能
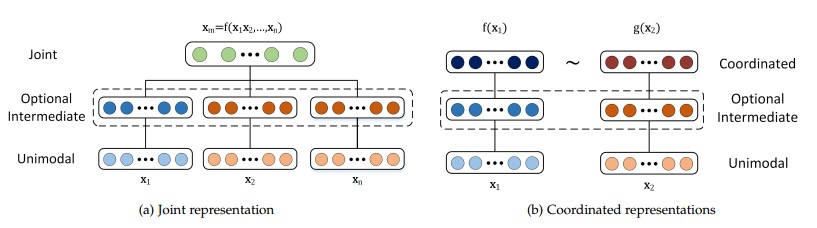
在之前的研究中(before 2019),大部分多模态表征简单的将单模态特征进行连接,两种多模态表征方法:联合表示(joint representation),协同表示(coordinated representation)
-
联合表示
每个模态为x_ixi,x_m = f(x_1, \dots, x_n)xm=f(x1,…,xn)
联合表示常用于训练推理均为多模态数据的任务中,最为简单的方法就是特征拼接
深度学习方法:深度学习特征后几层天然的包含高层语义信息,常用最后或倒数第二层特征
由于深度学习网络需要大量标注数据,常会利用无监督方法,例如自编码器,进行特征表示预训练,深度学习不能天然的解决数据丢失问题。
概率图模型:利用隐随机变量构建特征表示
最常见的基于图模型的特征表示方法,利用深度玻尔兹曼机(DBM)、受限玻尔兹曼机(RBM)作为模块构建,类似深度学习,特征分层,是无监督方法。也有用深度信念网络(DBN)表征每个模态然后进行联合表示的。
利用多模态深度玻尔兹曼机学习多模态特征表示,由于天然的生成特性,能够轻松处理丢失数据问题,整个模态数据丢失也可以自然解决;还可以用某种模态来生成另一种种模态的样本;DBM缺陷在于难训练,计算代价高,需要变分近似训练方法
-
序列表征
当数据的长度是变长序列时,例如句子、视频或者音频流,使用序列表征
RNN,LSTM当前主要用于表示单模态序列,而RNN的某个时刻的hidden state,可以看做在这个时刻前的所有序列的特征的整合,AVSR中Cosi等人使用RNN来表示多模态特征。
-
协同表示
每个模态为x_ixi,f(x_1) \sim g(x_2)f(x1)∼g(x2),每个模态有对应的映射函数,将它映射到多模态空间中,每个模态的投影过程是独立的,但是最终的多模态空间是通过某种限制来协同表示的。
两种协同表示方式:相似度模型,结构化模型,前者保证特征表示的相似性,后者加强在特征结果空间中的结构化。
相似度模型:相似度模型最小化不同模态在协同表示空间中的距离,例如狗和狗的图像的距离,小于狗和车的图像的距离。深度神经网络在协同表示中的优势在于能够以端到端的方式进行协同表示的联合学习。
结构化协同空间模型:结构化协同表示模型加强了不同模态表示的附加限制,具体的结构化限制根据应用而异。
结构化协同表示空间常用在跨模态哈希中,将高维的数据压缩到紧凑的二进制表示使得相似的object有相似的编码,常用于跨模态检索中。哈希的方法迫使最终多模态空间表示有如下限制:1) N维的汉明空间,可控位数的二进制表示;2) 不同模态的相同object有着相似的哈希编码;3) 多模态空间必须保持数据相似性。
另一种结构化协同表示的方法来源于图像和语言的“顺序嵌入”。
例如,Vendrov et al. 在多模态空间中强化了一种不相似度量,它是非对称的偏序关系。主要思想是在语言和图像的表示中抓住了一种偏序关系,强制了一种层级结构。对于一张图像,这种偏序关系为“a woman walking her dog” > “woman walking her dog” > “woman walking”。
一种特殊的结构化协同空间是基于典型相关分析(CCA)。CCA利用线性投影最大化两个随机变量相关性,增强了新空间的正交性。CCA模型多用于跨模态搜索,和语音视觉信号分析。
利用核方法,CCA可以扩展为KCCA,这种非参数的方法随着训练数据规模的增长可扩展性较差。深度典型相关分析DCCA作为KCCA的替代品被提出,解决了可扩展性问题,可以得到更好的相关表示空间。深度相关性RBM也可以作为跨模态搜索的方法。
KCCA,CCA,DCCA都是非监督的方法,仅能优化特征表示的相关性,能够获取到跨模态的共享特征。
其它的方法例如,深度典型相关自编码器,语义相关性最大化方法也用于结构化协同空间表示中
-
小结:
联合和协同表示方法是多模态特征表示的两种主要方法。
- 联合特征表示方法将多模态数据投影到一个共同的特征表示空间,最适用于推理时所有模态的数据都出现的场景。
- 协同特征表示方法将每个模态投影到分离但相关的空间,这种方法适用于推理时仅有一种模态出现的情况。
联合表示方法已经用在构建多于两种模态表示的场景,而协同空间表示常限定为两种模态。
二、多模态转化
从一种模态转化为另一种模态是很多多模态机器学习关注的内容。
多模态转化的任务是给定一个模态中的一个实体,生成另一种模态中的相同实体。例如,给定一张图像,我们可以生成一句话来描述这张图像,或者,给定一个文字描述,我们能够生成与之匹配的图像。多模态转化已经研究了很长时间,早期的语音合成、视听语音生成,视频描述,跨模态检索。近来,NLP和CV领域的结合,以及大规模多模态数据都推动这方面发展。
热门应用:视觉场景描述(图像、视频描述),除了识别主体部分、理解视觉场景,还需要生成语法正确,理解精确的描述语句。
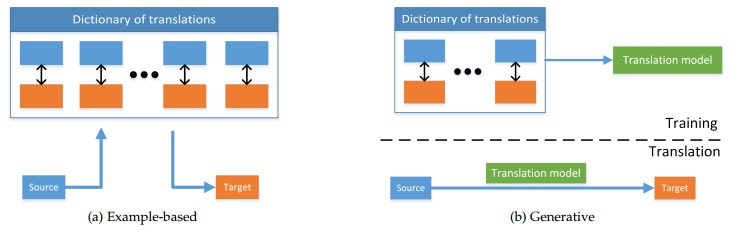
多模态转化可以分为两类,基于实例的方法和生成式方法,前者使用字典实现模态转化,后者使用模型生成转化结果
考虑到生成式模型需要生成信号或者符号序列(句子),生成式模型方法挑战更大。所以早期很多方法都倾向于基于实例的方法进行模态转化。然而随着深度学习的发展,生成式模型也具备了生成图像、声音、文本的能力。
-
基于实例的方法
基于实例的方法受限于训练数据——字典(源模态、目标模态构成的实例对)
两种算法:基于检索的方法,基于组合的方法,前者直接使用搜索到的转化结果,不会修改它们,后者依赖于更复杂的规则,基于大量搜索到的实例建立模态转化结果
基于检索的方法:基于检索的方法是多模态转化最简单的方法,它依赖字典中搜索到的最近的样本,利用它作为转化的结果,检索在单模态空间中完成,也可以在中间语义空间中完成。
给定一个待转化的源模态的实例,单模态检索通过在字典中查找最近的源模态实例实现模态转化,本质上就是通过KNN找到源模态到目标模态的映射。一些典型应用场景比如TTS,图像描述等。这种方法的好处是仅需要单一模态的表示,就可以通过检索实现。但也是由于采用搜索的方法,所以需要考虑搜索结果的重排序问题。这种方法的问题在于,在单模态空间中相似度高实例的并不一定就是好的模态转化。
另一种方法是利用中间语义空间来实现相似性比较。这种方法一般会搭配协同表示使用,应该是由于协同表示空间本身就对向量表示进行了相似性限制。在语义空间中进行模态检索的方法比单模态检索的方法效果更好,因为它的搜索空间同时反映了两种模态,更具有含义。同时,它支持双向的转化,这在单模态检索中不是很直接。然而,中间语义空间检索的方法需要学习一个语义空间,这需要大量的训练字典(源模态、目标模态样本对)。
基于组合的方法:通过将检索结果进行有意义的组合来得到更好的模态转化结果,基于组合的媒体描述(media description)主要是基于图像的描述语句都有着相同的简单结构这一特点。通常组合的规则都是人工指定的或者启发式生成的。
基于实例的方法面临的最大问题在于它的模型就是整个字典,模型会随着数据集的增加而不断增大,而且推理会变慢;另一个问题就是除非整个字典非常大,否则不能覆盖所有可能的源模态查询。这个问题可以通过多种模型组合解决。基于实例的方法进行多模态转化是单方向的,基于语义空间的方法可以在源模态和目标模态间双向转化。
-
生成式方法
生成式方法在多模态转化中构建的模型能够对给定单一模态实例进行多模态转化,挑战在于需要理解源模态来生成目标序列、信号,可能正确的转化结果非常多,因此这类方法较难评估。
三种生成式方法:基于语法,编码器-解码器,连续生成模型,第一种方法利用语法来限定目标域,例如生成基于<主语,宾语,动词>这种模板限定的句子;编码器解码器模型先将原模态编码到一个隐空间表示,然后解码器生成目标模态;第三种方法基于源模态的一个流式输入连续生成目标模态,特别适用于时序句子翻译如TTS。
基于语法规则的模型:依赖于为了生成特定模式而预先定义的语法。这种方法先从源模态中检测高层含义,例如图像中的实体、视频中的行为;然后将这些检测结果送入一个机遇预定义语法的生成过程来得到目标模态。
一些基于语法的方法依赖于图模型生成目标模式
基于语法的方法有事在于更倾向于生成语句结构上或者逻辑上正确的实例,因为他们是基于预先定义模板的、限定的语法。缺点在于生成语法化的结果而不是创新式的转化,没有生成新的内容;而且基于语法的方法依赖于复杂的概念,这些概念的detection的pipeline很复杂,每个概念的提取可能需要单独的模型和独立的训练集
编码器解码器模型:基于端到端神经网络训练,是最近最流行的多模态转化技术,核心思想是受限将源模态编码一种向量表示,然后利用解码器模块生成目标模态。起初用于机器翻译,当前已经成功用于图片解说,视频描述;当前主要用于生成文本,也可以用于生成图像和连续的语音、声音。
编码:首先将源实例进行特定模态编码。对声音信号比较流行的编码方法是RNN和DBN;对词、句子编码常用distributional semantics和RNN的变种;对于图像用CNN;视频编码仍然常用人工特征。也可以使用单一的模态表示方法,例如利用协同表示,能够得到更好的结果。
解码:通常利用RNN或者LSTM,将编码后的特征表示作为初始隐藏状态。Venugopalan et al.验证了利用预训练的LSTM解码器用于图像解说对于视频描述任务是有益的。利用RNN面临的问题在于模型需要从单一的图像、句子或者视频向量表示来生成一种描述。当需要生成长序列时,模型会忘记初始输入。这个问题可以通过注意力机制解决,让网络在生成过程中更关注与图像、句子、视频的部分内容。基于注意力的生成式RNN也被用于从句子生成图像的任务,不真实但是有潜质。
基于编码器解码器的网络虽然成功但是仍面临很多问题。Devlin et al.指出网络可能记住了训练数据,而不是学习到了如何理解和生成视觉场景。他观察到kNN模型生成的结果和编解码网络的生成结果非常相似。编解码模型需要的训练数据规模非常大。
连续生成模型:连续生成模型用于序列翻译和在线的方式在每个时间戳生成输出,当sequence到sequence转化时,这种方法很有效,例如文本转语音,语音转文本,视频转文本。
许多其它的方法也被提出用于这种建模:图模型,连续编解码方法,各种其它的回归分类方法。这些模型需要额外解决的问题是模态间的时序一致性问题。近来,Encoder-Decoder模型常用于序列转化建模。
-
小结和讨论
多模态转化所面临的一大挑战是很难进行评估,有些任务(例如语音识别)有一个正确的translation,而像语音合成和媒体描述则没有。有时就像在语言翻译场景中一样,多种答案都是正确的,哪种翻译更好通常非常主观。当前,大量近似自动化评价的标准也在辅助模态转化结果评估。
人的评价标准是最理想的。一些自动化评价指标例如在媒体描述中常用的:BLEU、ROUGE、Meteor、CIDEr也被提出,但是褒贬不一。
解决评估问题非常重要,不但能够用于比较不同的方法,而且能够提供更好的优化目标。
三、多模态对齐
多模态对齐是指找到两种或多种模态的instances中sub-components之间的对应关系,例如:给定一张图片和一个描述,找到词或者短语对应图片中的区域;另一个例子是给定一个电影,将它和字幕或者书中的章节对齐。
多模态对齐分成两类:隐式对齐和显示对齐,显示对齐显示的关注模态间sub-components的对应关系,例如将视频和菜谱中对应的步骤对齐;隐式对齐常作为其它任务的一个环节,例如基于文本的图像搜索中,将关键词和图片的区域进行对齐
-
显示对齐
sub-components间的相似性衡量是显示对齐的基础,两类算法无监督方法和(弱)监督方法
无监督方法:无监督方法不需要模态间对齐的标注,Dynamic time warping衡量两个序列的相似性,找到一个optimal的match,是一种dynamic programming的方法。由于DTW需要预定义的相似性度量,可以利用CCA(典型相关性分析)将模态映射到一个协同表达空间。DTW和CCA都是线性变换,不能找到模态间的非线性关系。图模型也可以用于无监督多模态序列的对齐。
DTW和图模型的方法用于多模态对齐需要遵循一些限制条件,例如时序一致性、时间上没有很大的跳跃、单调性。DTW能够同时学习相似性度量和模态对齐,图模型方法在建模过程中需要专家知识。
(弱)监督方法:监督方法需要标注好的模态对齐实例,用于训练模态对齐中的相似性度量,许多监督式序列对齐方法收到非监督方法的启发,当前深度学习方法用于模态对齐更加常见。
-
隐式对齐
常用作其它任务的中间步骤,使得例如语音识别、机器翻译、多媒体描述和视觉问答达到更好的性能。早期工作基于图模型,当前更多基于神经网络。
图模型:需要人工构建模态间的映射关系
神经网络:模态转换如果能够使用模态对齐,任务的性能可以得到提升
单纯的使用encoder只能通过调整权重来总结整张图片、句子、视频,作为单一的向量表示;注意力机制的引入,使得decoder能够关注到sub-components。注意力机制会让decoder更多的关注sub-components
注意力机制可以认为是深度学习模态对齐的一种惯用方法。
-
小结
模态对齐面临着许多困难:少有显示标注模态对齐的数据集;很难设计模态间的相似性度量;存在多种可能的模态对齐,而且一个模态中的elements可能在另一个模态中没有对应。
四、多模态融合
多模态融合就是整合多种模态的信息进行分类或者回归任务,多模态融合研究可以追溯到25年前。多模态融合带来的好处有:(1)同一个现象的不同模态表示能够产生更robust的推理结果;(2)从多种规模中能够得到辅助的信息,这些信息在单一模态中是不可见的;(3)对于一个多模态系统而言,模态融合能够在某一种模态消失时仍正常运行。
当前多模态表示和融合的界限愈发模糊,因为在深度学习中,表示学习和分类/回归任务交织在一起。
两种多模态混合方法:模型无关和基于模型的方法,前者不直接依赖于一种特定的机器学习方法,后者显示的在构建过程中进行融合(核方法、图模型、神经网络)。
-
模型无关方法
模型无关的方法有三种:前期融合、后期融合和混合融合。前期融合是特征级别的融合,后期融合是推理结果的融合,混合融合同时包括两种融合方法。
模型无关的融合方法好处是:可以兼容任何一种分类器或者回归器
前期融合可以看做是多模态表示的一种前期尝试
后期融合利用单一模态的预测结果,通过投票机制、加权、signal variance或者一个模型进行融合。后期融合忽略了模态底层特征之间的关系
-
基于模型的方法
多核学习(MKL):kernel SVM的扩展,对于不同模态使用不同的kernel
MKL方法是深度学习之前最常用的方法,优势在于loss function是凸的,模型训练可以使用标准的优化package和全局优化方法,劣势在于测试时对于数据集的依赖推理速度慢。
-
图模型
在本篇综述中仅考虑浅层的图模型,深度图模型例如DBN可以参考前面章节内容,大多数图模型可以分成两类:生成式(联合概率)和判别式(条件概率)
图模型能够很容易的发掘数据中的空间和时序结构,同时可以将专家知识嵌入到模型中,模型也可解释
-
神经网络
神经网络用于模态融合所使用的模态、优化方法可能不同,通过joint hidden layers进行信息融合的思路是一致的。神经网络也用于时序多模态融合,通常采用RNN和LSTM,典型的应用是audio-visual情感分类,图片解说
深度神经网络用于模态融合优点:(1)可以从大量数据学习;(2)端到端学习多模态特征表示和融合;(3)和非深度学习方法相比性能好,能学习复杂的decision boundary
缺点:可解释性差,不知道网络根据什么进行推理,也不知道每个模态起的作用;需要大量训练数据才能得到好的效果
-
小结
多模态融合任务中有如下挑战:1)signal可能不是时序对齐的,例如密集的连续信号vs稀疏的事件;2)很难建立一个模型来发掘补充信息而非辅助信息;3)每个模态在不同时间点可能展现出不同类型、不同级别的噪声。
五、多模态共同学习
多模态共同学习旨在通过发掘另一种模态的信息来帮助当前模态建模
相关场景:一种模态的资源有限,缺乏标注数据或者输入噪声大,标签可靠性低
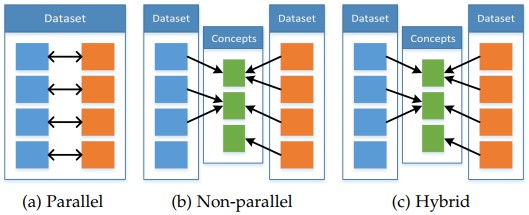
三种co-learning的方法:并行,非并行,混合;第一种方法需要一种模态的observation和另一种模态的observation直接连接,例如在audio-visual speech数据及上,video和speech sample来自同一个speaker;非并行数据方法不需要两种observation的直接连接,通常利用类别间的交集,例如在zero shot learning中利用Wiki的文本数据扩展传统的视觉目标识别数据集提升目标识别的性能;混合数据的方法通过一种共享模态或者数据连接起来。
-
并行数据
模态之间共享一个实例集合,两种方法:协同训练和表征学习
协同训练:当某一个模态的标记数据非常少时,可以利用协同训练生成更多的标注训练数据,或者利用模态间的不一致性过滤不可靠标注样本
协同训练方法能够生成更多的标注数据,但也可能会导致overfitting
迁移学习:多模态玻尔兹曼机或者多模态自编码器将一种模态特征表示转化为另一种,这样不仅能得到多模态表征,而且对于单模态而言推理过程中也能得到更好的性能。
-
非并行数据
不需要依赖模态间共享的实例,有共享的类别或者概念(concept)即可
迁移学习:迁移学习能够从一个数据充分、干净的模态学习特征表示迁移到另一个数据稀缺、噪声大的模态,这种迁移学习常用多模态协同特征表示实现。
Conceptual grounding:通过语言以及其他附加模态,例如视觉、声音、甚至味觉,学习语义含义,单纯的利用文本信息不能很好的学习到语义含义,例如人学习一个概念的时候利用的是所有的感知信息而非单纯的符号。
grounding通常通过寻找特征表征间的共同隐空间或者分别学习每个模态的特征表示然后进行拼接,conceptual grounding和多模态特征对齐之间有很高的重合部分,因为视觉场景和对应描述对齐本身能够带来更好的文本或者视觉特征表示。
需要注意的是,grounding并不能在所有情况下带来性能的提升,仅当grounding与具体任务相关时有效,例如在视觉相关任务中利用图像进行grounding
Zero-shot learning:ZSL任务是指在没有显示的见过任何sample的情况下识别一种概念,例如不提供任何猫的图片对图片中的猫进行分类。
两种方法:单模态方法和多模态方法
单模态方法:关注待识别类别的组成部分和属性,例如视觉方面通过颜色、大小、形状等属性去预测为见过的类别
多模态方法:利用另一个模态的信息,在另一个模态中该类别出现过
混合数据:通过共享的模态或者数据集连接两种非数据并行的模态,典型的任务例如多种语言进行图像描述,图片会与至少一种语言之间建立联系,语言之间的可以利用机器翻译任务建立起联系。
目标任务如果仅有少量标注数据,也可利用类似或相关任务去提升性能,例如利用大量文本语料指导图像分割任务。
-
小结
多模态协同学习通过寻找模态之间的互补信息,使一种模态影响另一种模态的训练过程。
多模态协同学习是与任务无关的,可以用于更好的多模态特征融合、转换和对齐。
点击关注,第一时间了解华为云新鲜技术~
加载全部内容