Python LightGBM分类预测
柚子味的羊 人气:1一、Introduction
LightGBM是扩展机器学习系统。是一款基于GBDT(梯度提升决策树)算法的分布梯度提升框架。其设计思路主要集中在减少数据对内存与计算性能的使用上,以及减少多机器并行计算时的通讯代价
1 LightGBM的优点
- 简单易用。提供了主流的Python\C++\R语言接口,用户可以轻松使用LightGBM建模并获得相当不错的效果。
- 高效可扩展。在处理大规模数据集时高效迅速、高准确度,对内存等硬件资源要求不高。
- 鲁棒性强。相较于深度学习模型不需要精细调参便能取得近似的效果。
- LightGBM直接支持缺失值与类别特征,无需对数据额外进行特殊处理
2 LightGBM的缺点
- 相对于深度学习模型无法对时空位置建模,不能很好地捕获图像、语音、文本等高维数据。
- 在拥有海量训练数据,并能找到合适的深度学习模型时,深度学习的精度可以遥遥领先LightGBM。
二、实现过程
1 数据集介绍
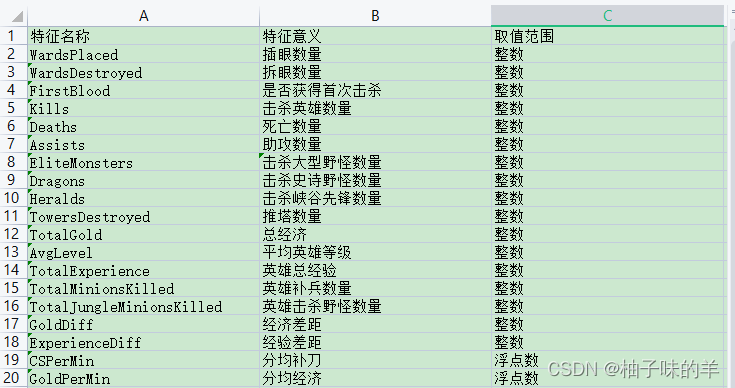
本数据用于LightGBM分类实战。该数据集共有9881场英雄联盟韩服钻石段位以上的排位赛数据,数据提供了在十分钟时的游戏状态,包括击杀数,金币数量,经验值,等级等信息。
2 Coding
#导入基本库
import numpy as np
import pandas as pd
## 绘图函数库
import matplotlib.pyplot as plt
import seaborn as sns
#%% 数据读入:利用Pandas自带的read_csv函数读取并转化为DataFrame格式
df = pd.read_csv('D:\Python\ML\data\high_diamond_ranked_10min.csv')
y = df.blueWins
#%%查看样本数据
#print(y.value_counts())
#标注特征列
drop_cols=['gameId','blueWins']
x=df.drop(drop_cols,axis=1)
#对数字特征进行统计描述
x_des=x.describe()

#%%去除冗余数据,因为红蓝为竞争关系,只需知道一方的情况,对方相反因此去除红方的数据信息
drop_cols = ['redFirstBlood','redKills','redDeaths'
,'redGoldDiff','redExperienceDiff', 'blueCSPerMin',
'blueGoldPerMin','redCSPerMin','redGoldPerMin']
x.drop(drop_cols, axis=1, inplace=True)
#%%可视化描述。为了有一个好的呈现方式,分两张小提琴图展示前九个特征和中间九个特征,后面的相同不再赘述
data = x
data_std = (data - data.mean()) / data.std()
data = pd.concat([y, data_std.iloc[:, 0:9]], axis=1)#将标签与前九列拼接此时的到的data是(9879*10)的metric
data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values')#将上面的数据melt成(88911*3)的metric
fig, ax = plt.subplots(1,2,figsize=(15,8))
# 绘制小提琴图
sns.violinplot(x='Features', y='Values', hue='blueWins', data=data, split=True,
inner='quart', ax=ax[0], palette='Blues')
fig.autofmt_xdate(rotation=45)#改变x轴坐标的现实方法,可以斜着表示(倾斜45度),不用平着挤成一堆
data = x
data_std = (data - data.mean()) / data.std()
data = pd.concat([y, data_std.iloc[:, 9:18]], axis=1)
data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values')
# 绘制小提琴图
sns.violinplot(x='Features', y='Values', hue='blueWins',
data=data, split=True, inner='quart', ax=ax[1], palette='Blues')
fig.autofmt_xdate(rotation=45)
plt.show()

#%%画出各个特征之间的相关性热力图 fig,ax=plt.subplots(figsize=(15,18)) sns.heatmap(round(x.corr(),2),cmap='Blues',annot=True) fig.autofmt_xdate(rotation=45) plt.show()

#%%根据上述特征图,剔除相关性较强的冗余特征(redAvgLevel,blueAvgLevel) # 去除冗余特征 drop_cols = ['redAvgLevel','blueAvgLevel'] x.drop(drop_cols, axis=1, inplace=True) sns.set(style='whitegrid', palette='muted') # 构造两个新特征 x['wardsPlacedDiff'] = x['blueWardsPlaced'] - x['redWardsPlaced'] x['wardsDestroyedDiff'] = x['blueWardsDestroyed'] - x['redWardsDestroyed'] data = x[['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff','wardsDestroyedDiff']].sample(1000) data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') plt.figure(figsize=(15,8)) sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data) plt.show()
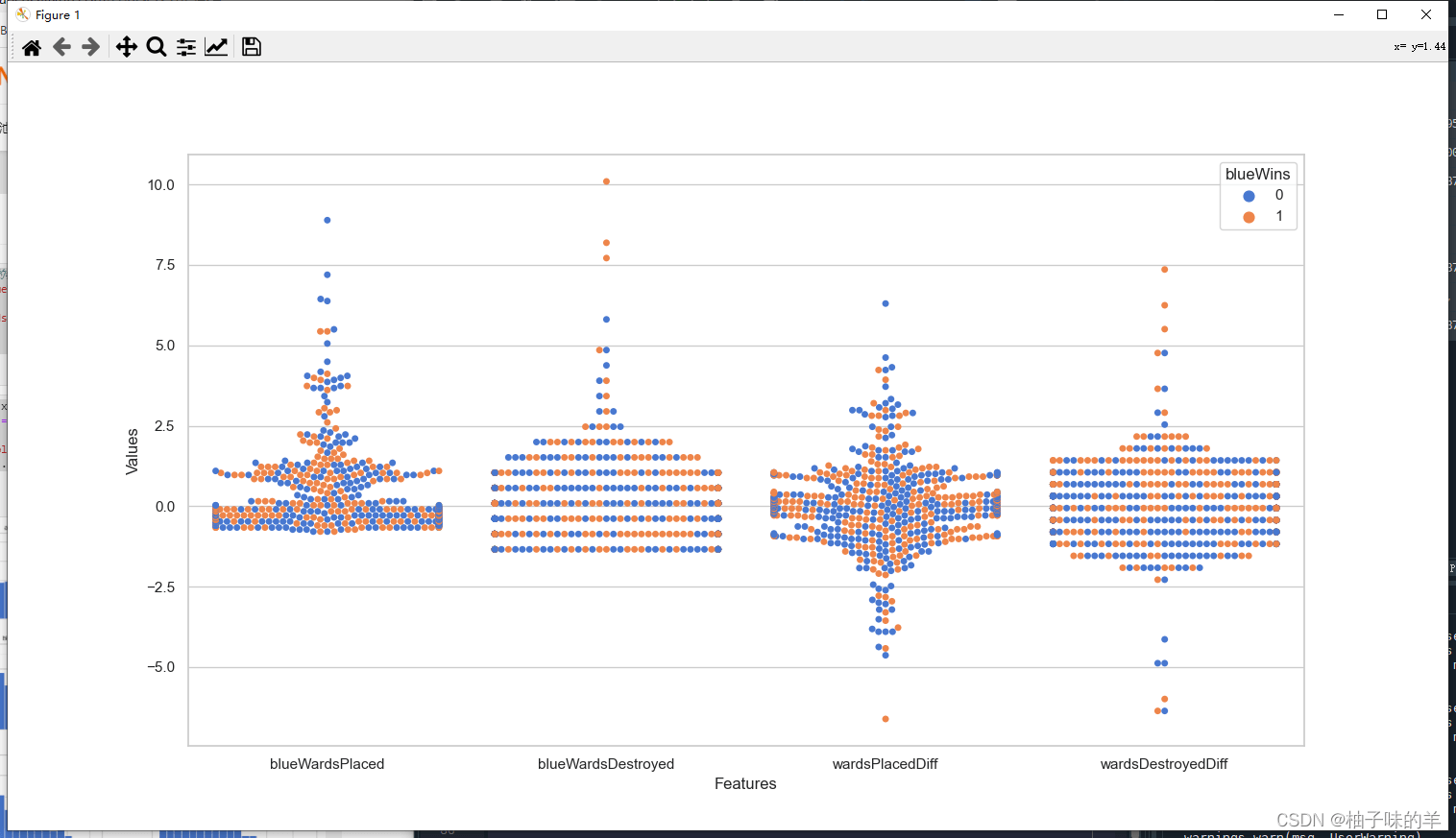
#%%由上图插眼数量的离散图,可以发现插眼数量与游戏胜负之间的显著规律,游戏前十分钟插眼与否对最终的胜负影响不大,故将这些特征去除
## 去除和眼位相关的特征
drop_cols = ['blueWardsPlaced','blueWardsDestroyed','wardsPlacedDiff',
'wardsDestroyedDiff','redWardsPlaced','redWardsDestroyed']
x.drop(drop_cols, axis=1, inplace=True)
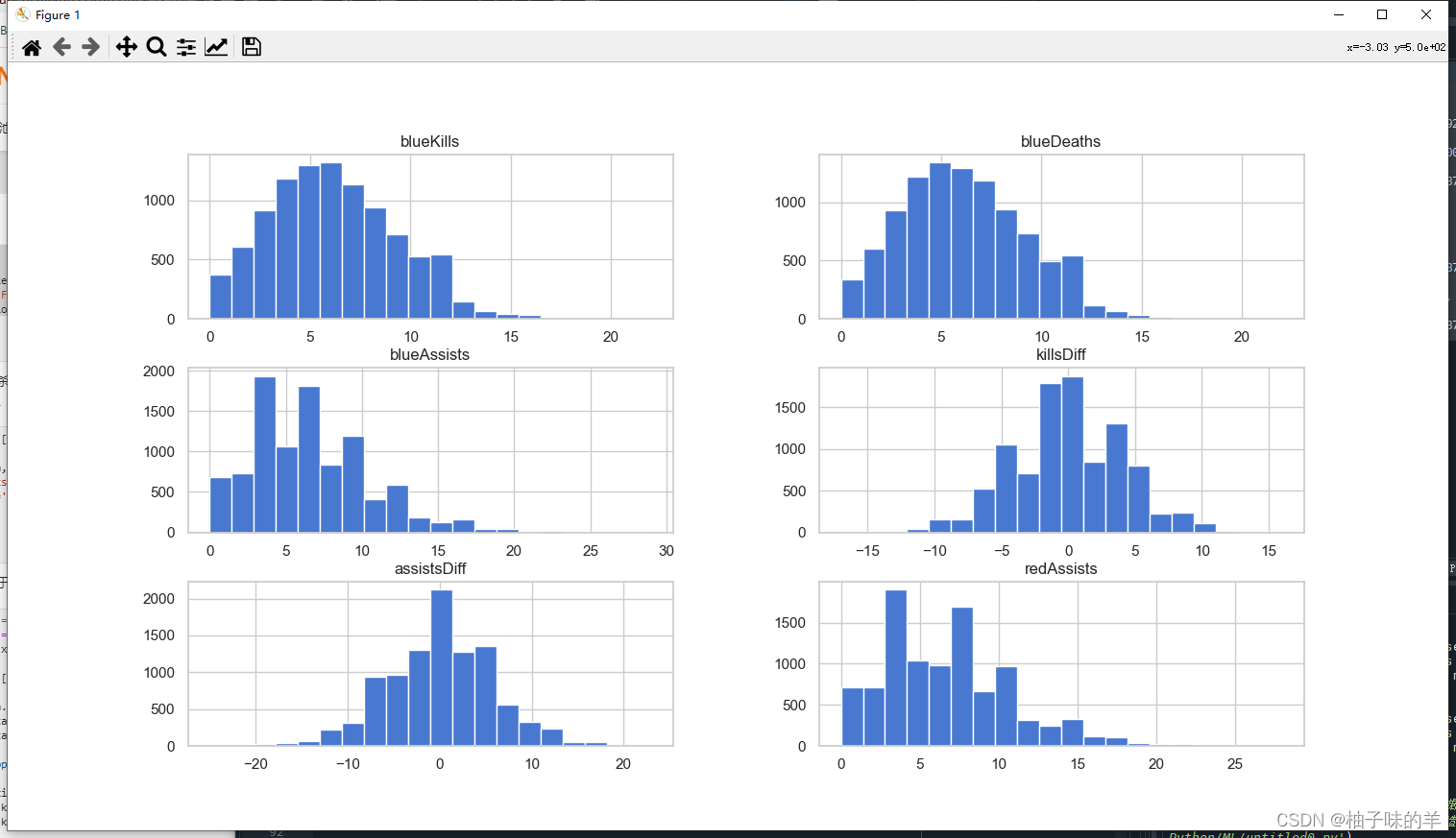
#%%击杀、死亡与助攻数的数据分布差别不大,但是击杀减去死亡、助攻减去死亡的分布与缘分不差别较大,构造两个新的特征
x['killsDiff'] = x['blueKills'] - x['blueDeaths']
x['assistsDiff'] = x['blueAssists'] - x['redAssists']
x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].hist(figsize=(15,8), bins=20)
plt.show()
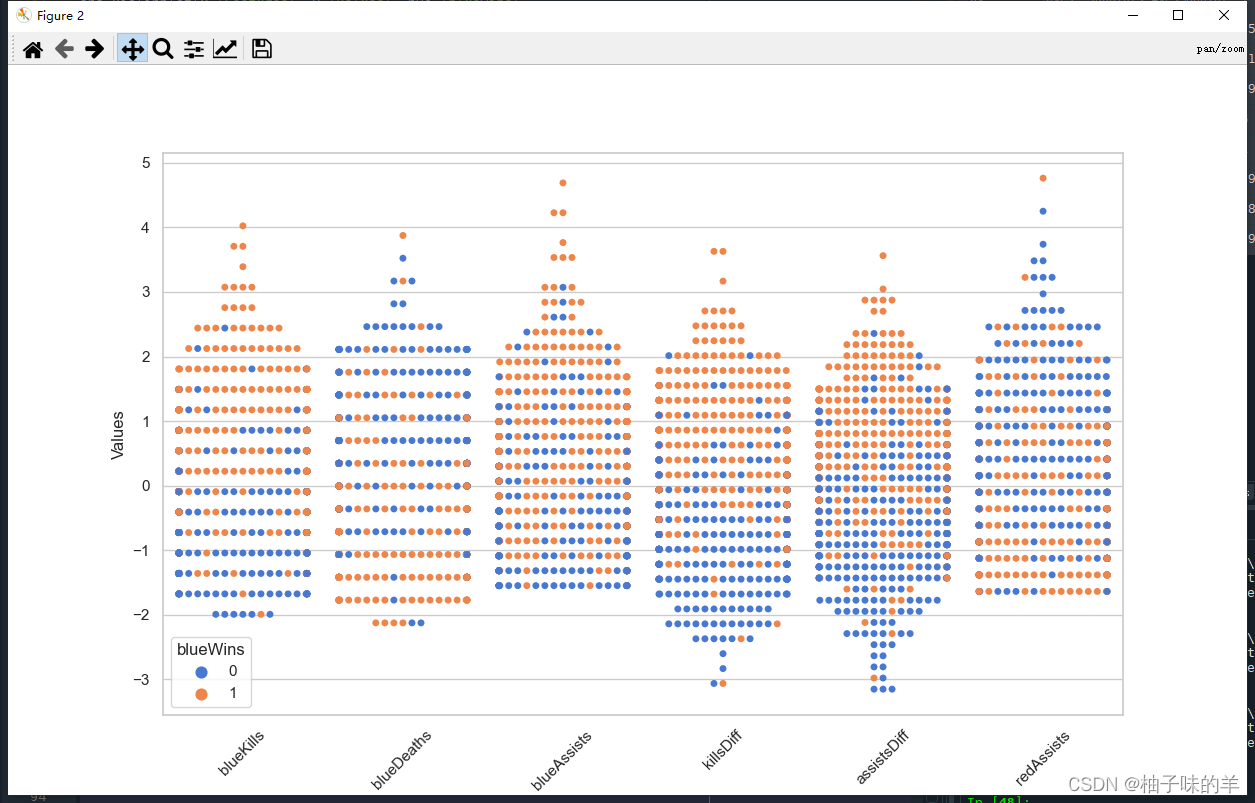
#%% data = x[['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists']].sample(1000) data_std = (data - data.mean()) / data.std() data = pd.concat([y, data_std], axis=1) data = pd.melt(data, id_vars='blueWins', var_name='Features', value_name='Values') plt.figure(figsize=(10,6)) sns.swarmplot(x='Features', y='Values', hue='blueWins', data=data) plt.xticks(rotation=45) plt.show()
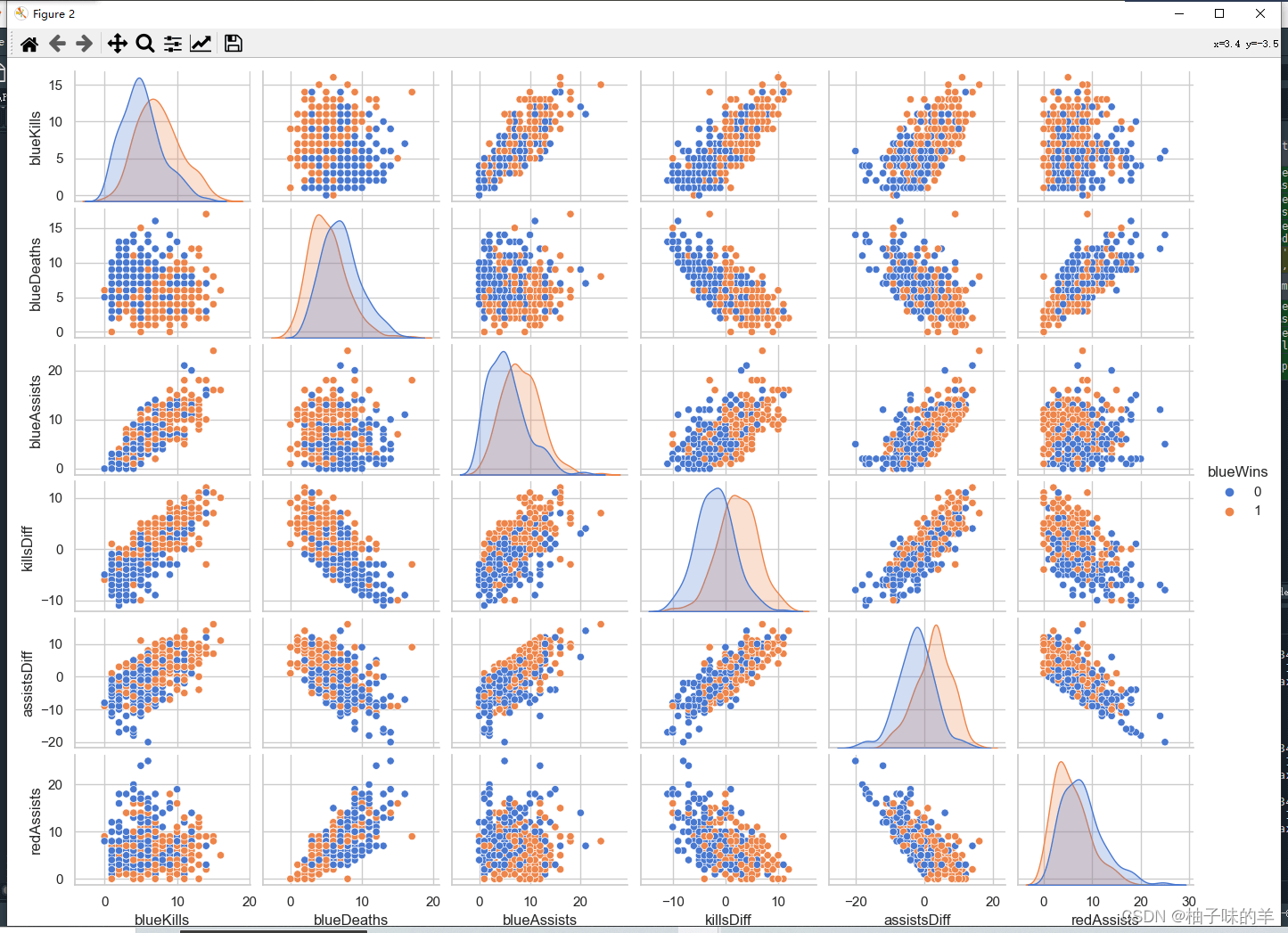
#%%
data = pd.concat([y, x], axis=1).sample(500)
sns.pairplot(data, vars=['blueKills','blueDeaths','blueAssists','killsDiff','assistsDiff','redAssists'],
hue='blueWins')
plt.show()
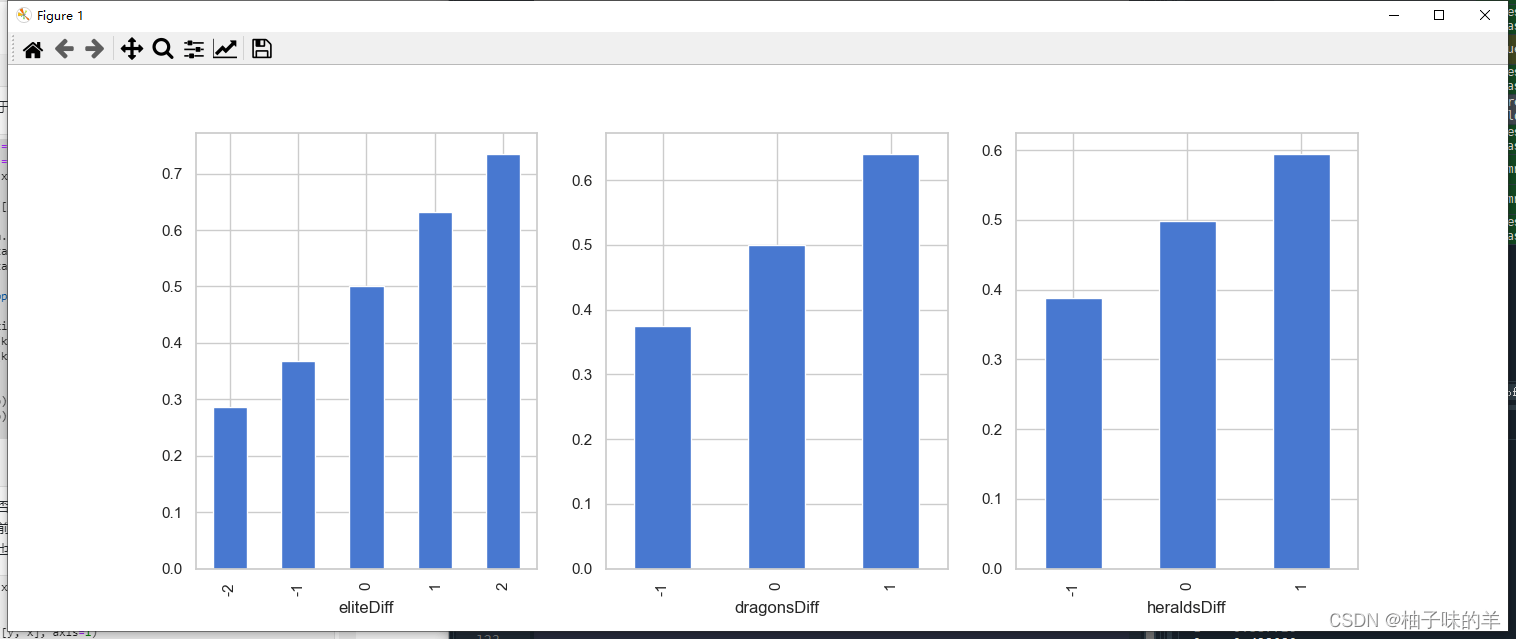
#%%一些特征两两组合后对于数据的划分有提升 x['dragonsDiff'] = x['blueDragons'] - x['redDragons']#拿到龙 x['heraldsDiff'] = x['blueHeralds'] - x['redHeralds']#拿到峡谷先锋 x['eliteDiff'] = x['blueEliteMonsters'] - x['redEliteMonsters']#击杀大型野怪 data = pd.concat([y, x], axis=1) eliteGroup = data.groupby(['eliteDiff'])['blueWins'].mean() dragonGroup = data.groupby(['dragonsDiff'])['blueWins'].mean() heraldGroup = data.groupby(['heraldsDiff'])['blueWins'].mean() fig, ax = plt.subplots(1,3, figsize=(15,4)) eliteGroup.plot(kind='bar', ax=ax[0]) dragonGroup.plot(kind='bar', ax=ax[1]) heraldGroup.plot(kind='bar', ax=ax[2]) print(eliteGroup) print(dragonGroup) print(heraldGroup) plt.show()
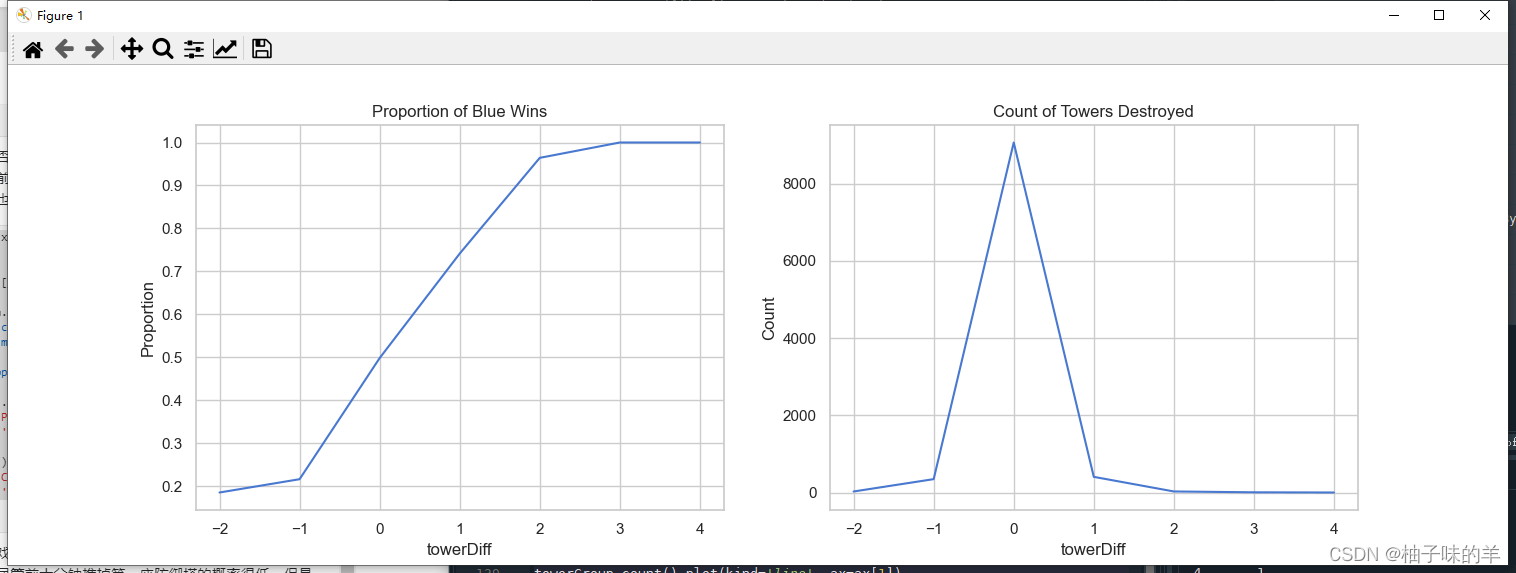
#%%推塔数量与游戏胜负
x['towerDiff'] = x['blueTowersDestroyed'] - x['redTowersDestroyed']
data = pd.concat([y, x], axis=1)
towerGroup = data.groupby(['towerDiff'])['blueWins']
print(towerGroup.count())
print(towerGroup.mean())
fig, ax = plt.subplots(1,2,figsize=(15,5))
towerGroup.mean().plot(kind='line', ax=ax[0])
ax[0].set_title('Proportion of Blue Wins')
ax[0].set_ylabel('Proportion')
towerGroup.count().plot(kind='line', ax=ax[1])
ax[1].set_title('Count of Towers Destroyed')
ax[1].set_ylabel('Count')
#%%利用LightGBM进行训练和预测
## 为了正确评估模型性能,将数据划分为训练集和测试集,并在训练集上训练模型,在测试集上验证模型性能。
from sklearn.model_selection import train_test_split
## 选择其类别为0和1的样本 (不包括类别为2的样本)
data_target_part = y
data_features_part = x
## 测试集大小为20%, 80%/20%分
x_train, x_test, y_train, y_test = train_test_split(data_features_part, data_target_part, test_size = 0.2, random_state = 2020)
#%%## 导入LightGBM模型
from lightgbm.sklearn import LGBMClassifier
## 定义 LightGBM 模型
clf = LGBMClassifier()
# 在训练集上训练LightGBM模型
clf.fit(x_train, y_train)
#%%在训练集和测试集上分别利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
from sklearn import metrics
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
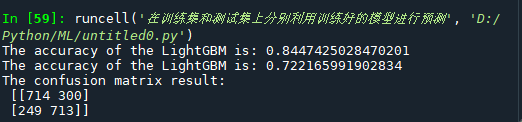
print('The accuracy of the LightGBM is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the LightGBM is:',metrics.accuracy_score(y_test,test_predict))
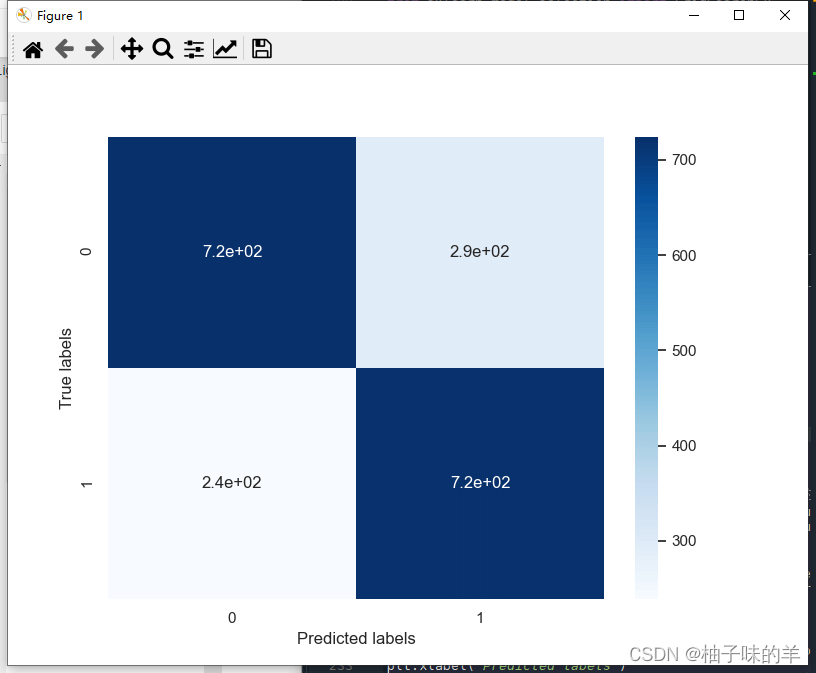
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
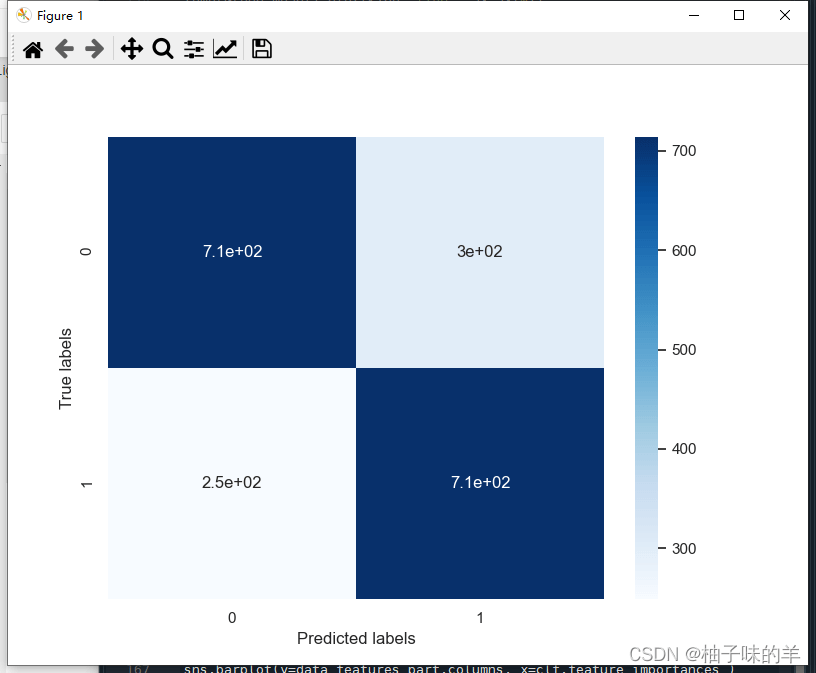
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
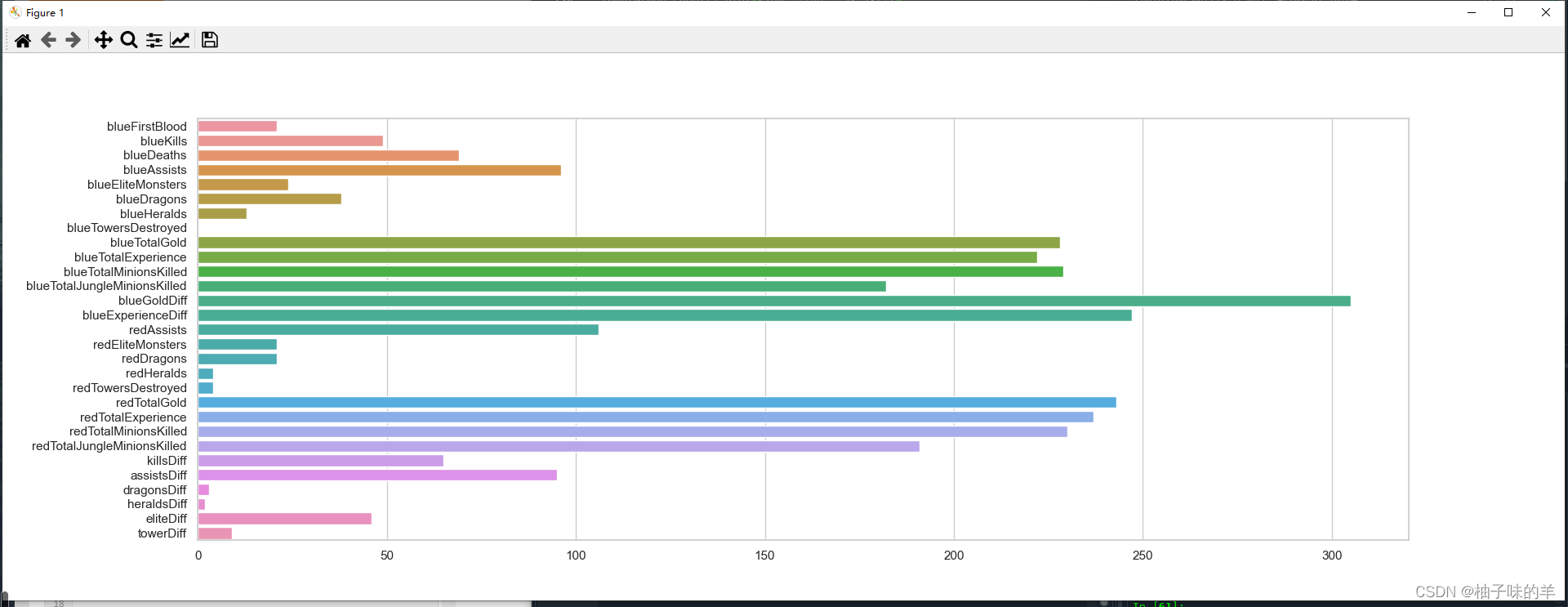
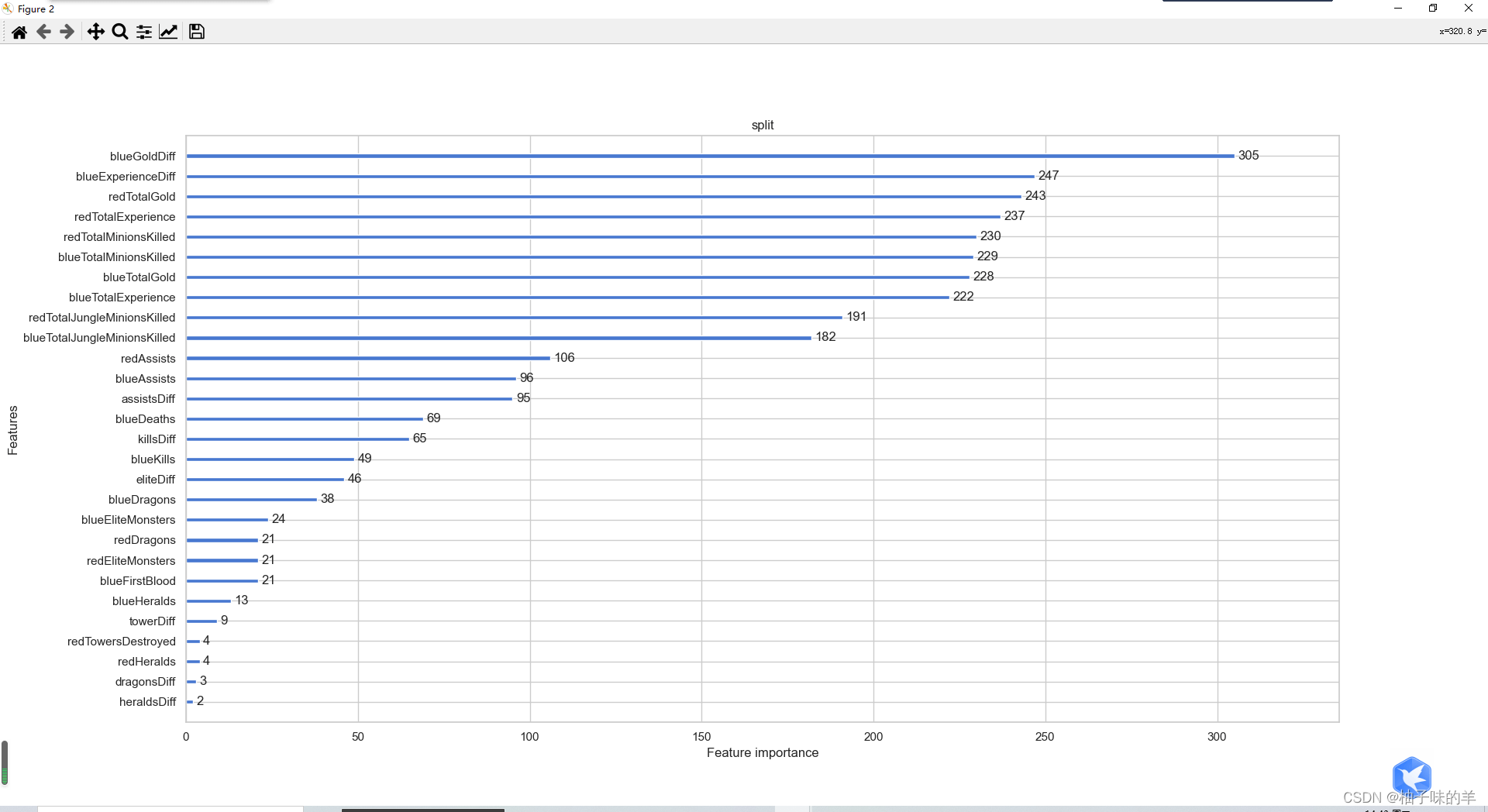
#%%利用lightgbm进行特征选择,同样可以用属性feature_importances_查看特征的重要度 sns.barplot(y=data_features_part.columns, x=clf.feature_importances_)
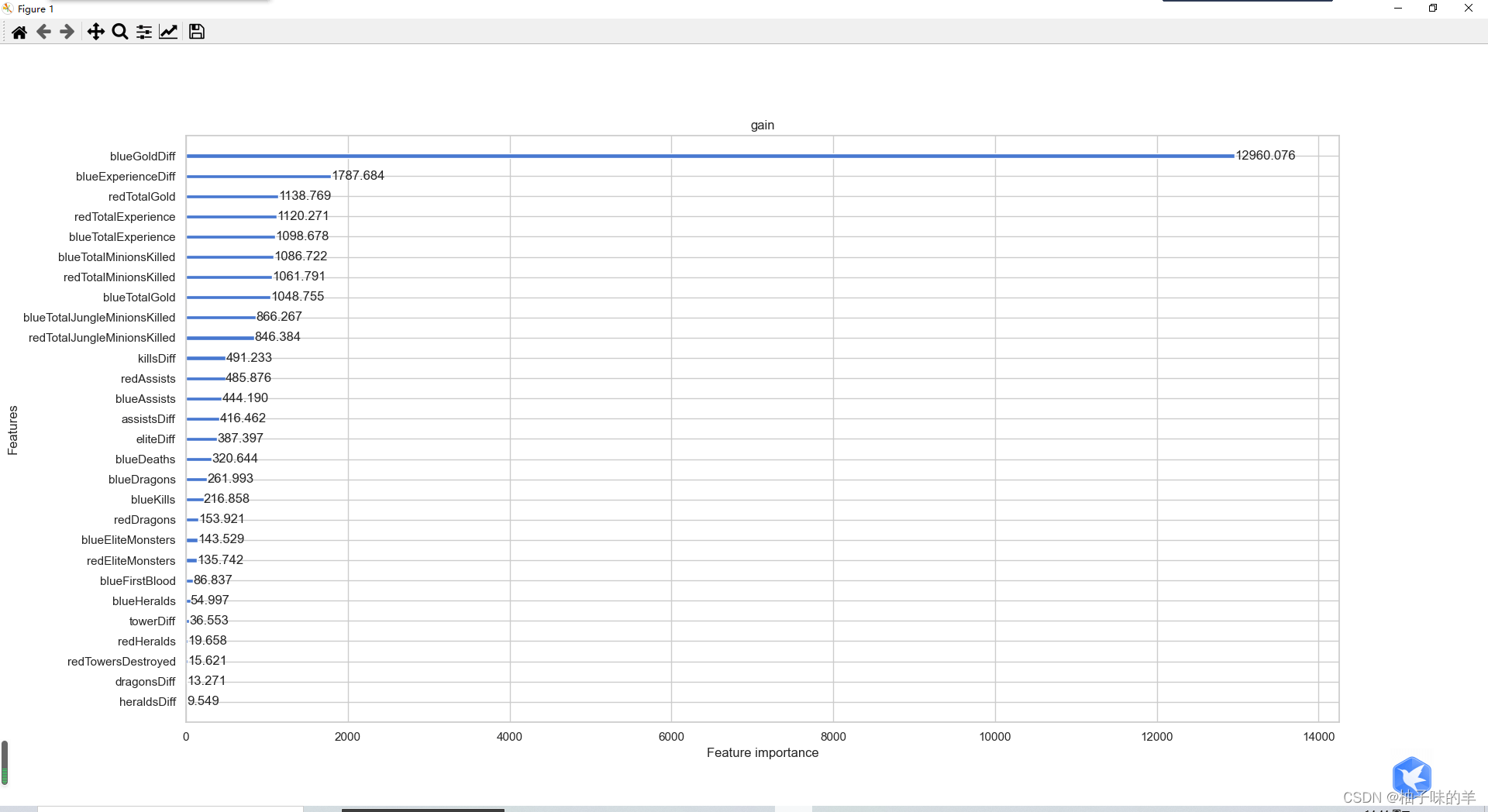
#%%除feature_importances_外,还可以使用LightGBM中的其他属性进行评估(gain,split)
from sklearn.metrics import accuracy_score
from lightgbm import plot_importance
def estimate(model,data):
ax1=plot_importance(model,importance_type="gain")
ax1.set_title('gain')
ax2=plot_importance(model, importance_type="split")
ax2.set_title('split')
plt.show()
def classes(data,label,test):
model=LGBMClassifier()
model.fit(data,label)
ans=model.predict(test)
estimate(model, data)
return ans
ans=classes(x_train,y_train,x_test)
pre=accuracy_score(y_test, ans)
print('acc=',accuracy_score(y_test,ans))
通过调整参数获得更好的效果: LightGBM中重要的参数
- learning_rate: 有时也叫作eta,系统默认值为0.3。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。
- num_leaves:系统默认为32。这个参数控制每棵树中最大叶子节点数量。
- feature_fraction:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。
- max_depth: 系统默认值为6,我们常用3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。
#%%调整参数,获得更好的效果
## 从sklearn库中导入网格调参函数
from sklearn.model_selection import GridSearchCV
## 定义参数取值范围
learning_rate = [0.1, 0.3, 0.6]
feature_fraction = [0.5, 0.8, 1]
num_leaves = [16, 32, 64]
max_depth = [-1,3,5,8]
parameters = { 'learning_rate': learning_rate,
'feature_fraction':feature_fraction,
'num_leaves': num_leaves,
'max_depth': max_depth}
model = LGBMClassifier(n_estimators = 50)
## 进行网格搜索
clf = GridSearchCV(model, parameters, cv=3, scoring='accuracy',verbose=3, n_jobs=-1)
clf = clf.fit(x_train, y_train)
#%%查看最好的参数值分别是多少
print(clf.best_params_)

#%%查看最好的参数值分别是多少
print(clf.best_params_)
#%% 在训练集和测试集上分布利用最好的模型参数进行预测
## 定义带参数的 LightGBM模型
clf = LGBMClassifier(feature_fraction = 1,
learning_rate = 0.1,
max_depth= 3,
num_leaves = 16)
# 在训练集上训练LightGBM模型
clf.fit(x_train, y_train)
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
## 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the LightGBM is:',metrics.accuracy_score(y_train,train_predict))
print('The accuracy of the LightGBM is:',metrics.accuracy_score(y_test,test_predict))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
print('The confusion matrix result:\n',confusion_matrix_result)
# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()

三、Keys
LightGBM的重要参数
基本参数调整
- num_leaves参数 这是控制树模型复杂度的主要参数,一般的我们会使num_leaves小于(2的max_depth次方),以防止过拟合。由于LightGBM是leaf-wise建树与XGBoost的depth-wise建树方法不同,num_leaves比depth有更大的作用。
- min_data_in_leaf 这是处理过拟合问题中一个非常重要的参数. 它的值取决于训练数据的样本个树和 num_leaves参数. 将其设置的较大可以避免生成一个过深的树, 但有可能导致欠拟合. 实际应用中, 对于大数据集, 设置其为几百或几千就足够了.
- max_depth 树的深度,depth 的概念在 leaf-wise 树中并没有多大作用, 因为并不存在一个从 leaves 到 depth 的合理映射
针对训练速度的参数调整
- 通过设置 bagging_fraction 和 bagging_freq 参数来使用 bagging 方法。
- 通过设置 feature_fraction 参数来使用特征的子抽样。
- 选择较小的 max_bin 参数。使用 save_binary 在未来的学习过程对数据加载进行加速。
针对准确率的参数调整
- 使用较大的 max_bin (学习速度可能变慢)
- 使用较小的 learning_rate 和较大的 num_iterations
- 使用较大的 num_leaves (可能导致过拟合)
- 使用更大的训练数据
- 尝试 dart 模式
针对过拟合的参数调整
- 使用较小的 max_bin
- 使用较小的 num_leaves
- 使用 min_data_in_leaf 和 min_sum_hessian_in_leaf
- 通过设置 bagging_fraction 和 bagging_freq 来使用 bagging
- 通过设置 feature_fraction 来使用特征子抽样
- 使用更大的训练数据
- 使用 lambda_l1, lambda_l2 和 min_gain_to_split 来使用正则
- 尝试 max_depth 来避免生成过深的树
最近越发觉得良好的coding habits的重要性!debug才是yyds,从刚学C语言的时候就被老师教育过,当时尝到了debug的甜头,到后来大部分写完即使没有bug的代码还是会debug一遍,现在依然是,希望大家也都养成debug的习惯,当然还有就是写注释,annotation是自己当时的思想,不写后期自己返回来看很大程度时间久了都不知道每个步骤的用意。 886~~~
加载全部内容