.NET比较两个byte数组是否相等
InCerry 人气:0前言
之前在群里面有群友问过一个这样的问题,在.NET中如何快速的比较两个byte数组是否完全相等,听起来是一个比较两个byte数组是完全相等是一个简单的问题,但是深入研究以后,觉得还是有很多方案的,这里和大家一起分享下。
评测方案
这里为了评测不同方案的性能,我们用到了BenchmarkDotNet这个库,这个库目前已经被收入.NET基金会下,BenchmarkDotNet可以很方便的评测方法执行的性能,支持几乎所有的.NET运行环境,并且能输出详细的报表。使用起来也非常简单,你只需要安装BenchmakrDotNet的Nuget包,然后使用其提供的类和方法即可,这里是它的项目地址和帮助文档。
我们通过BenchmarkDotNet来构建一个这样的评测用例.
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using CompareByte;
// 需要引入BenchmarkDotNet的命名空间
// 运行Benchmark相当简单,只需要执行这个静态方法,泛型是需要评测的类
var summary = BenchmarkRunner.Run<BenchmarkCompareMethod>();
// 我们需要一些评测内存结果信息
// 并且生成HTML报表
[MemoryDiagnoser]
[HtmlExporter]
public class BenchmarkCompareMethod
{
// 准备两个数组,填充4MB大小的数据
private static readonly byte[] XBytes = Enumerable.Range(0, 4096000).Select(c => (byte) c).ToArray();
private static readonly byte[] YBytes = Enumerable.Range(0, 4096000).Select(c => (byte) c).ToArray();
public BenchmarkCompareMethod()
{
// 修改数组最后一个元素,使其不同
XBytes[4095999] = 1;
YBytes[4095999] = 2;
}
[Benchmark(Baseline = true)]
public void ForCompare()
{
.....
}
}
需要注意的是,为了保证评测的结果与生产环境一致,BenchmarkDotNet是要求使用Release模式运行程序,这样的话不仅代码编译成IL时优化,程序运行中JIT也会更加积极的参与生产机器码优化。需要在项目文件夹下面使用dotnet run -c Release来运行评测。
几种不同的方案
For循环
一开始看到这个需求,第一个想到的就是直接使用for循环对byte[]进行按下标比较,我觉得也是大家第一时间能想到的方案,那我们就上代码跑跑看速度。
public static bool ForCompare(byte[]? x, byte[]? y)
{
if (ReferenceEquals(x, y)) return true; // 引用相等,可以直接认为相等
if (x is null || y is null) return false; // 两者引用不相等情况下,一方为null那就不相等
if (x.Length != y.Length) return false; // 两者长度不等,那么肯定也不相等
for (var index = 0; index < x.Length; index++)
{
if (x[index] != y[index]) return false;
}
return true;
}
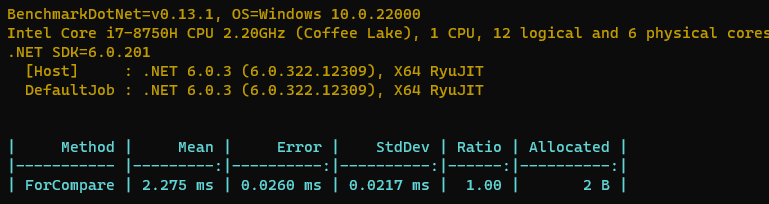
最终的结果如下所示,我们可以看到其实使用for循环进行比较是很快的,4MB大小的数组2ms左右就能比较完毕。
其实还有一个优化点,.NET的JIT对一些方法默认是不做inline内联优化的,这样每次还有一个方法调用的开销,我们让jit去积极的进行内联,再来试试。方法也很简单,只需要引入System.Runtime.CompilerServices命名空间,然后在方法上面打上头标记即可。
要搞清楚为什么方法内联有用,首先要知道当一个方法被调用的时候发生了什么
1、首先会有个执行栈,存储目前所有活跃的方法,以及它们的本地变量和参数2、当一个新的方法被调用了,一个新的栈帧会被加到栈顶,分配的本地变量和参数会存储在这个栈帧3、跳到目标方法代码执行4、方法返回的时候,本地方法和参数会被销毁,栈顶被移除5、返回原来地址执行
这就是通常说的方法调用的压栈和出栈过程,因此,方法调用需要有一定的时间开销和空间开销,当一个方法体不大,但又频繁被调用时,这个时间和空间开销会相对变得很大,变得非常不划算,同时降低了程序的性能。所以内联简单的说就是把目标方法里面代码复制到调用方法的地方,无需压栈、跳转和出栈。
不过并不是所有的方法内联都有益处,需要方法体比较小,如果方法体很大的话在每一个调用的地方都会发生替换,浪费内存。
using System.Runtime.CompilerServices; ..... [MethodImpl(MethodImplOptions.AggressiveInlining | MethodImplOptions.AggressiveOptimization)] public static bool ForCompare(byte[]? x, byte[]? y)
再来跑一下试试。
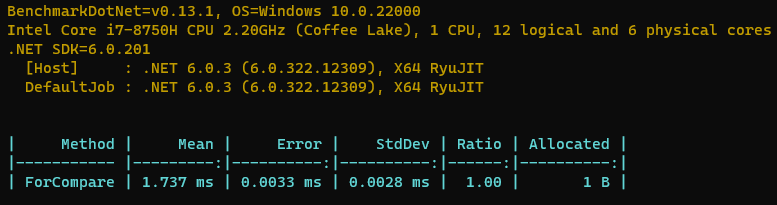
最后可以看到性能提升了30%呀,分配的字节数少了50% (虽然本来就只有2字节),讲道理就可以直接交差了。
Memcmp
但是群里面还有小伙伴就不满足了,有没有其它的方案?有个小伙伴就跳出来说,操作系统是不是提供了类似的功能?会不会使用C/C++代码运行起来会更加快速?
没错,操作系统确实提供了这样的函数,微软提供了一个名为mscrt(微软C运行时库)的库,里面就提到了memcmp这个函数就可以来比较两个buffer是否相等。MSDN链接.
函数签名是这样的,这个函数位于mscrt.dll内。
int memcmp( const void *buffer1, // 数组1指针 const void *buffer2, // 数组2指针 size_t count // 比较字节数 );
既然有现成的C语言代码,那么C#应该如何调用它呢?实际上C#经常被大家成为C++++是有一定道理的,它在设计之初就考虑了和C、C++等代码的交互。这里使用到了C#的Native Interop - P/Invoke技术,可以很方便的使用C风格的ABI(C++、Rust等等都提供C语言ABI生成),在.NET底层大量的代码都是通过这种方式和底层交互,有兴趣的可以戳链接了解更详细的信息。
那么如何使用它呢?以我们上面的函数为例,我们只需要引入System.Runtime.InteropServices命名空间,然后按照上面memcmp函数的签名转换为C#代码就行了,最终的代码如下所示。
using System;
using System.Runtime.InteropServices;
namespace CompareByte;
public static class BytesCompare
{
[DllImport("msvcrt.dll")] // 需要使用的dll名称
private static extern unsafe int memcmp(byte* b1, byte* b2, int count);
// 由于指针使用是内存不安全的操作,所以需要使用unsafe关键字
// 项目文件中也要加入<AllowUnsafeBlocks>true</AllowUnsafeBlocks>来允许unsafe代码
public static unsafe bool MemcmpCompare(byte[]? x,byte[]? y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
if (x.Length != y.Length) return false;
// 在.NET程序的运行中,垃圾回收器可能会整理和压缩内存,这样会导致数组地址变动
// 所以,我们需要使用fixed关键字,将x和y数组'固定'在内存中,让GC不移动它
// 更多详情请看 https://docs.microsoft.com/zh-cn/dotnet/csharp/language-reference/keywords/fixed-statement
fixed (byte* xPtr = x, yPtr = y)
{
return memcmp(xPtr, yPtr, x.Length) == 0;
}
}
}
那我们来跑个分吧,看看结果怎么样。
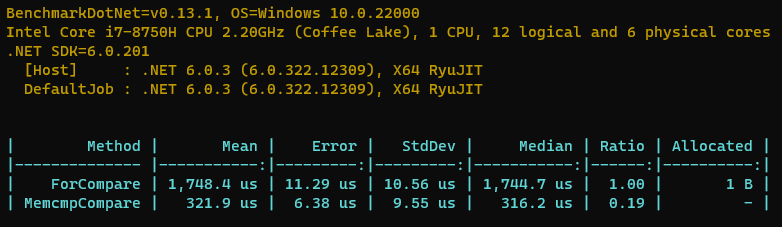
结果真的是Amazing呀,比我们使用的for循环方案足足快了80+%,从原来需要1.7ms左右到现在只需要300us。
64字长优化
那是不是证明C#就是没有C跑的那么快呢?C#那还有没有优化的空间呢?当然是有方法的,实际上memcmp使用的算法和我们现在用的不一样。
我们知道衡量算法的时间复杂度是使用大O来表示,而这个其实是代码执行时间随数据规模增长的变化趋势的一个体现。比如我输入的数据量大小为n,完成这个函数我近似需要执行n次,那么时间复杂度就是O(n)。
再来回到我们的问题中,在最坏的情况下(x和y引用不相等且的长度相等),我们上面写的ForCompare就会进入for循环来遍历x和y每一个元素进行比较,所以它的时间复杂度就是O(n),那么问题的关键就是如何降低它的时间复杂度。
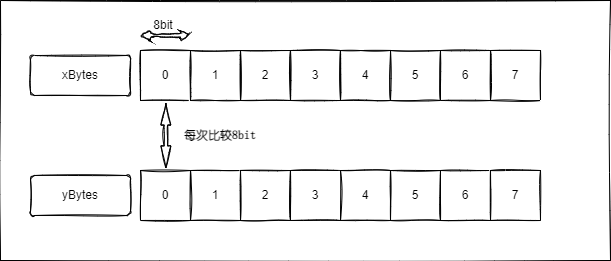
一个数组它的地址空间是连续的,另外byte类型的长度是8bit,默认比较方式就像下图一样,一个元素一个元素的比较,也就是每8bit每8bit进行比较。
那我们能让他一次比较更多的位数吗?比如一次16位、32位、64位?当然是可以的,毕竟我们现在基本都是64位的CPU,不严谨的说实际上CPU一次能处理64位数据,那么我们如何让它一次性能比较64位呢?
有小伙伴就说,很简单嘛,byte是8bit,我们直接用long不就有64bit了吗?没错,就是这么简单,我们可以把byte*指针强转为long*指针,然后一次性比较64位,如下图所示。
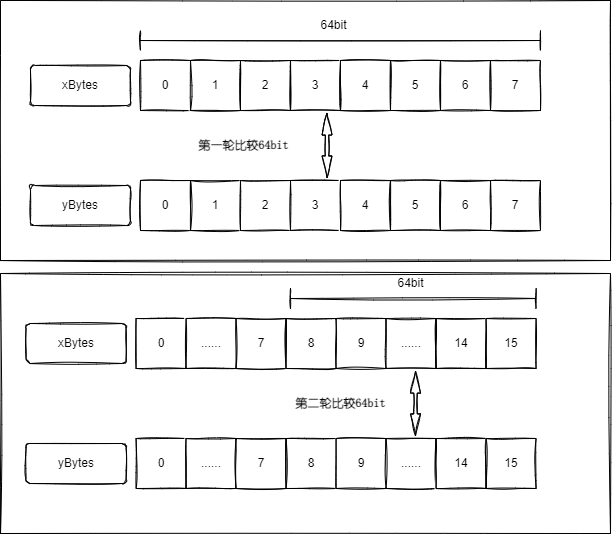
上代码(我这用的是UInt64包装的ulong,一样是64位,没有符号位会更快一点):
public static unsafe bool UlongCompare(byte[]? x, byte[]? y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
if (x.Length != y.Length) return false;
fixed (byte* xPtr = x, yPtr = y)
{
return UlongCompareInternal(xPtr, yPtr, x.Length);
}
}
private static unsafe bool UlongCompareInternal(byte* xPtr, byte* yPtr, int length)
{
// 指针+偏移量计算出数组最后一个元素地址
byte* lastAddr = xPtr + length;
byte* lastAddrMinus32 = lastAddr - 32;
while (xPtr < lastAddrMinus32) // 我们一次循环比较32字节,也就是256位
{
// 一次判断比较前64位
if (*(ulong*) xPtr != *(ulong*) yPtr) return false;
// 第二次从64为开始,比较接下来的64位,需要指针偏移64位,一个byte指针是8为,所以需要偏移8个位置才能到下一轮起始位置
// 所以代码就是xPtr+8
if (*(ulong*) (xPtr + 8) != *(ulong*) (yPtr + 8)) return false;
// 同上面一样,第三次从第128位开始比较64位
if (*(ulong*) (xPtr + 16) != *(ulong*) (yPtr + 16)) return false;
// 第四次从第192位开始比较64位
if (*(ulong*) (xPtr + 24) != *(ulong*) (yPtr + 24)) return false;
// 一轮总共比较了256位,让指针偏移256位
xPtr += 32;
yPtr += 32;
}
// 因为上面是一次性比较32字节(256位),可能数组不能为32整除,最后只留下比如30字节,20字节
// 最后的几个字节,我们用循环来逐字节比较
while (xPtr < lastAddr)
{
if (*xPtr != *yPtr) return false;
xPtr++;
yPtr++;
}
return true;
}
那我们来跑个分吧。
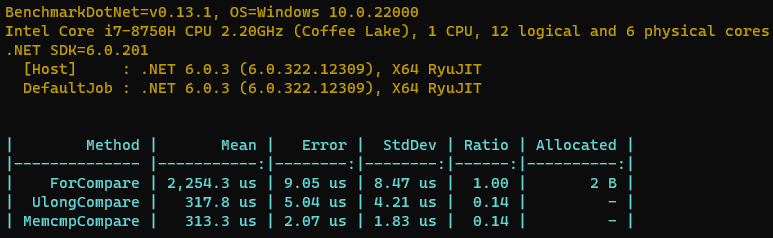
可以看到基本和memcmp打平了,几us的差别可以看做是误差。大佬们一直说,C#是一门下限低,上限高的语言,你开心的话写出来的代码完全媲美C++,代码里面还能嵌入汇编,只是有点麻烦,O(∩_∩)O哈哈~
SIMD
那么我们就这样满足了吗?
小伙伴又问了,既然我们可以一次性比较64位,那我们能比较更多的位数吗?比如128位,256位?答案是当然可以,这个是CPU的一个技术,叫Single Instruction Multiple Data,简称为SIMD,SIMD主要就是说CPU中可以单条指令实现数据的并行处理,这类指令在数字信号处理、图像处理、以及多媒体信息处理等领域非常有效。
我们打开CPU-Z,可以看到指令集有很多,这都是CPU为了特殊的程序单独做的优化。
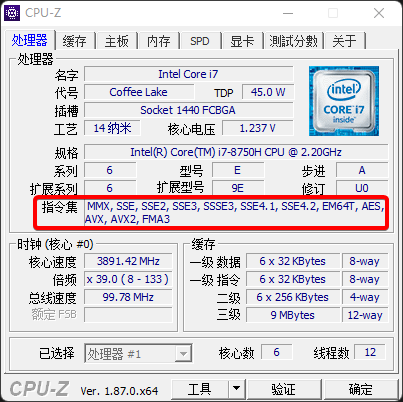
MMX:MMX 是MultiMedia eXtensions(多媒体扩展)的缩写,是第六代CPU芯片的重要特点。MMX技术是在CPU中加入了特地为视频信号(Video Signal),音频信号(Audio Signal)以及图像处理(Graphical Manipulation)而设计的57条指令,因此,MMX CPU极大地提高了电脑的多媒体(如立体声、视频、三维动画等)处理功能。
SSE:SSE是 “因特网数据流单指令序列扩展 ( Internet Streaming SIMD Extensions)的缩写。SSE除保持原有的MMX指令外,又新增了70条指令,在加快浮点运算的同时,改善了内存的使用效率,使内存速度更快,后面有一些增强版SSE2、SSE3等等。
EM64T:Intel的EM64T技术,EM64T技术官方全名是Extended Memory 64 Technology,中文解释就是扩展64bit内存技术。
AES:AES(Advanced Encryption Standard,高级加密标准)指令集,是专门为加密解密设计的,与此前相比AES加密/解密之性能高出3倍。
AVX:Advanced Vector eXtentions(AVX)在2008年由Intel与AMD提出,并于2011年分别在Sandy Bridge以及Bulldozer架构上提供⽀持。AVX的主要改进在于对寄存器长度的扩展以及提供了更灵活的指令集。 AVX对 XMM 寄存器做了扩展,从原来的128-bit扩展到了256-bit,256-bit的寄存器命名为 YMM 。YMM的低128-bit是与XMM混⽤ 的。
对于这些指令集,在.NET上提供了System.Runtime.Intrinsics.X86命名空间,其中支持了各种指令集原生的访问,想了解更多的东西,可以戳这个链接。由于SIMD在.NET上有着天然的支持,可以很方便的写出SIMD代码,而其它编程语言平台或多或少支持都不是很完美。
| 类名 | 作用 |
|---|---|
| Aes | 此类通过内部函数提供对 Intel AES 硬件指令的访问权限。 |
| Avx | 该类通过内联函数提供对 Intel AVX 硬件指令的访问权限。 |
| Avx2 | 此类通过内部函数提供对 Intel AVX2 硬件指令的访问。 |
| Bmi1 | 此类通过内部函数提供对 Intel BMI1 硬件指令的访问权限。 |
| Bmi2 | 此类通过内部函数提供对 Intel BMI2 硬件指令的访问权限。 |
| Fma | 此类通过内部函数提供对 Intel FMA 硬件指令的访问权限。 |
| Lzcnt | 此类通过内部函数提供对 Intel LZCNT 硬件指令的访问权限。 |
| Pclmulqdq | 此类通过内部函数提供对 Intel PCLMULQDQ 硬件指令的访问权限。 |
| Popcnt | 此类通过内部函数提供对 Intel POPCNT 硬件指令的访问权限。 |
| Sse | 此类通过内部函数提供对 Intel SSE 硬件指令的访问权限。 |
| Sse2 | 此类通过内部函数提供对 Intel SSE2 硬件指令的访问权限。 |
| Sse3 | 此类通过内部函数提供对 Intel SSE3 硬件指令的访问权限。 |
| Sse41 | 此类通过内部函数提供对 Intel SSE 4.1 硬件指令的访问。 |
| Sse42 | 此类通过内部函数提供对 Intel SSE4.2 硬件指令的访问权限。 |
| Ssse3 | 此类通过内部函数提供对 Intel SSSE3 硬件指令的访问权限。 |
| X86Base | 通过内部函数提供对 x86 基本硬件指令的访问。 |
Sse
我们看到SSE系列的指令集可以操作128位,那我们就来试试128位会不会更快一些,直接上代码。
using System.Runtime.Intrinsics.X86; // 需要引入这个命名空间
namespace CompareByte;
public static class BytesCompare
{
......
public static unsafe bool Sse2Compare(byte[]? x, byte[]? y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
if (x.Length != y.Length) return false;
fixed (byte* xPtr = x, yPtr = y)
{
return Sse2CompareInternal(xPtr, yPtr, x.Length);
}
}
private static unsafe bool Sse2CompareInternal(byte* xPtr, byte* yPtr, int length)
// 这里的算法与64位大体一样,只是位数变成了128位
byte* lastAddr = xPtr + length;
byte* lastAddrMinus64 = lastAddr - 64;
const int mask = 0xFFFF;
while (xPtr < lastAddrMinus64)
// 使用Sse2.LoadVector128()各加载x和y的128位数据
// 再使用Sse2.CompareEqual()比较是否相等,它的返回值是一个128位向量,如果相等,该位置返回0xffff,否则返回0x0
// CompareEqual的结果是128位的,我们可以通过Sse2.MoveMask()来重新排列成32位,最终看是否等于0xffff就好
if (Sse2.MoveMask(Sse2.CompareEqual(Sse2.LoadVector128(xPtr), Sse2.LoadVector128(yPtr))) != mask)
{
return false;
}
if (Sse2.MoveMask(Sse2.CompareEqual(Sse2.LoadVector128(xPtr + 16), Sse2.LoadVector128(yPtr + 16))) != mask)
if (Sse2.MoveMask(Sse2.CompareEqual(Sse2.LoadVector128(xPtr + 32), Sse2.LoadVector128(yPtr + 32))) != mask)
if (Sse2.MoveMask(Sse2.CompareEqual(Sse2.LoadVector128(xPtr + 48), Sse2.LoadVector128(yPtr + 48))) != mask)
xPtr += 64;
yPtr += 64;
while (xPtr < lastAddr)
if (*xPtr != *yPtr) return false;
xPtr++;
yPtr++;
return true;
}
放到JIT里面看看,有没有生成SIMD代码,可以明显的看到汇编代码里面已经有了SIMD代码。
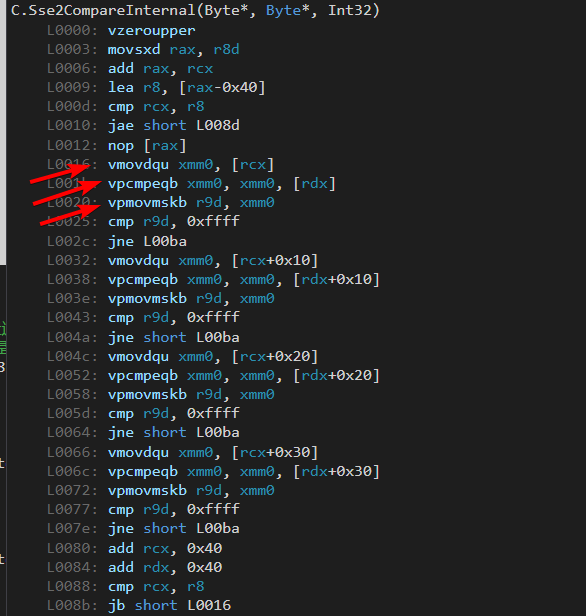
来看看跑分结果。
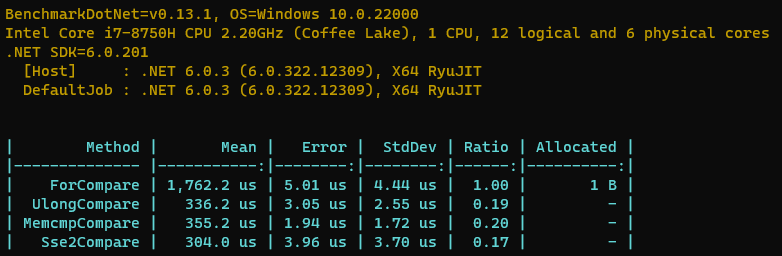
可以看到对比memcmp的方式快了2+%,那按道理来说从64位到128位应该快50%左右才对,为什么只快了2+%呢?
其实这是因为SIMD是单条指令多数据处理,其中运算还是CPU内部的64位单元处理,只是少了多条指令的开销。另外是因为原本64位是只比较了一次,而SIMD需要经历CompareEqual、MoveMask最后还需和mask掩码比较,总共次数多了2次。只能说明在我们的这个场景下,提升会比较有限。
需要注意目标平台需要能支持这些特殊的指令集,可以通过Sse2.IsSupported方法来判断。
Avx2
既然128位的SSE系列指令集能在原来的基础上提升2%,那我们来看看支持256位的Avx2指令集会提升多少。代码和SSE指令集几乎一样,只是调用的方法类名变动了。
using System.Runtime.Intrinsics.X86; // 需要引入这个命名空间
namespace CompareByte;
public static class BytesCompare
{
......
public static unsafe bool Avx2Compare(byte[]? x, byte[]? y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
if (x.Length != y.Length) return false;
fixed (byte* xPtr = x, yPtr = y)
{
return Avx2CompareInternal(xPtr, yPtr, x.Length);
}
}
private static unsafe bool Avx2CompareInternal(byte* xPtr, byte* yPtr, int length)
byte* lastAddr = xPtr + length;
byte* lastAddrMinus128 = lastAddr - 128;
const int mask = -1;
while (xPtr < lastAddrMinus128)
// 更换为Avx2指令集,一次加载256位
if (Avx2.MoveMask(Avx2.CompareEqual(Avx.LoadVector256(xPtr), Avx.LoadVector256(yPtr))) != mask)
{
return false;
}
if (Avx2.MoveMask(Avx2.CompareEqual(Avx.LoadVector256(xPtr + 32), Avx.LoadVector256(yPtr + 32))) != mask)
if (Avx2.MoveMask(Avx2.CompareEqual(Avx.LoadVector256(xPtr + 64), Avx.LoadVector256(yPtr + 64))) != mask)
if (Avx2.MoveMask(Avx2.CompareEqual(Avx.LoadVector256(xPtr + 96), Avx.LoadVector256(yPtr + 96))) != mask)
xPtr += 128;
yPtr += 128;
while (xPtr < lastAddr)
if (*xPtr != *yPtr) return false;
xPtr++;
yPtr++;
return true;
}
再来看看跑分结果。
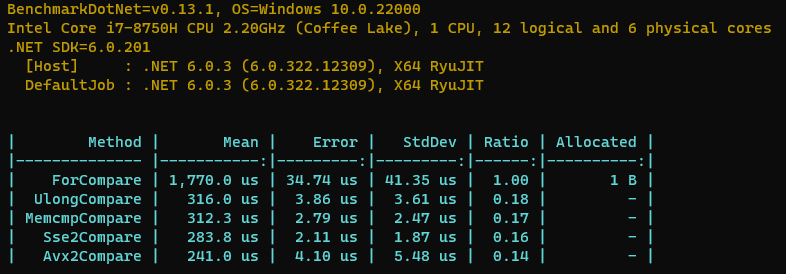
可以看到,Avx2指令集对于memcmp和Sse2是有一定的提升的,有2+%左右的速度提升,另外相较于原本的for循环比较提升了86%。
SequenceCompare
那么是不是以后我们写比较两个数组相等的代码都要写这一长串的unsafe代码呢?其实并不是,在.NET Core时代引入了Span这个特性,这个特性就是为了能安全的直接操作内存;与此同时,也提供了SequenceEquals方法,能快速的比较两个序列,使用也非常简单,那究竟性能怎么样呢?我们上代码,跑个分。
// 代码非常简单,只需要调用System.Linq.SequenceEqual方法即可
public static bool SequenceCompare(byte[]? x, byte[]? y)
{
if (ReferenceEquals(x, y)) return true;
if (x is null || y is null) return false;
if (x.Length != y.Length) return false;
return x.SequenceEqual(y);
}
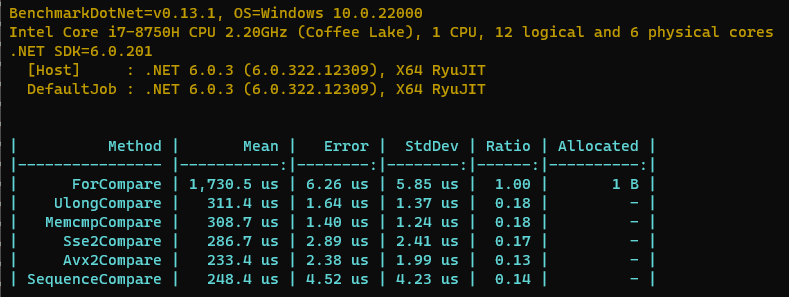
结果也是相当不错的,比memcmp和SSE2的方式都要快一点,略逊于Avx2,但是它用起来很简单,那么它是如何做到这么快的呢?让我们看看它的源码,
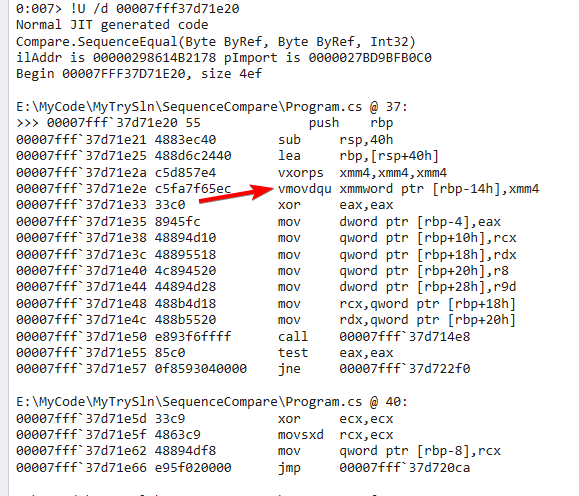
链接貌似也没有什么技巧,那是不是JIT编译的时候有优化,给自动向量化了呢?我们将代码复制出来,然后单独跑了一下,再用WinDBG打开,我们可以看到确实JIT优化引入了一些自动向量化(SIMD)的操作。
总结
通过这几种方案的对比,最推荐的用法当然就是直接使用.NET库提供的SequenceEquals方法来完成比较,如果是在.NET Framework中,由于没有这样的优化,所以大家也可以尝试上文中提到的SSE2等方法。
那么大家还有什么其它好的方式呢?欢迎在评论区留言!
笔者水平有限,如有错漏请批评指正 :)
本文源码链接
参考文献
加载全部内容