C语言无头单向非循环链表
风&646 人气:0链表引入
问:上次我们看了顺序表,那么顺序表有些什么优缺点呢?
优点:
顺序表是连续的物理空间,方便下标的随机访问。
缺点:
1.增容需要申请新空间,拷贝数据,释放旧的空间。会有一定消耗。
2.头部或者中间位置插入或者删除数据,需要挪动数据,效率较低。
3.可能存在一定空间占用,浪费空间,不能按需申请和释放空间。
为了解决上诉问题,我们引入了链表。首先我们先来看看单链表。
链表介绍
链表是一种物理存储结构上非连续、非顺序的存储结构、数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个节点包含两部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。

实际上,链表的结构多样,如下:
1.单向或者双向

2.带头或者不带头
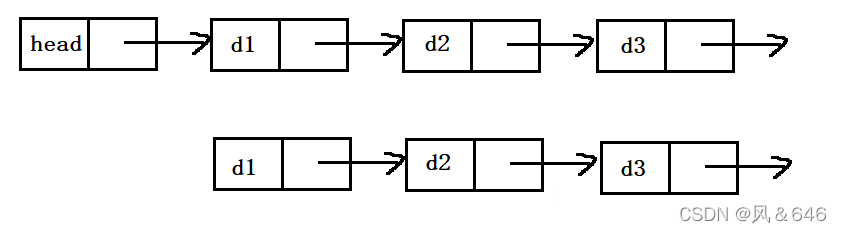
3.循环或者非循环

创建链表
链表是由结点链接而成的,所以创建链表需要创建一个结点类型。该类型由指针域和数据域组成。
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;//用来存放该结点的数据
struct SListNode* next;//用来存放下一个结点的地址
}SListNode;
打印链表
从头指针指向的位置开始,依次向后打印,知道cur访问到NULL就结束循环。
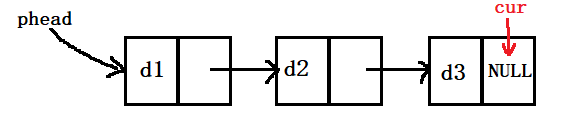
void SListPrint(SListNode* phead);
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;//我们一般不会改变头指针,所以我们把头指针赋值给cur
while (cur)//链表结束条件
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");//表示数据已经打印完毕
}创建结点
每当我们需要插入一个数据,我们就需要申请一个结点,如果每次都重新申请就会很麻烦,所以我们将创建一个新结点封装为一个函数。
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
printf("BuySListNode::%s\n", strerror(errno));//若申请失败,则打印错误信息
exit(-1);
}
else
{
newnode->data = x;//将数据赋值到新点的数据域
newnode->next = NULL;//新结点指针域置为空指针
}
return newnode;//返回新结点的地址
}单链表尾插
我们需要将尾插分为两种情况:
情况一: 链表为空,我们直接让头指针指向新的结点即可。
情况二: 链表已经有多个结点,我们需要找到链表的最后一个结点,然后让最后一个结点指向新的结点。
void SListPushBack(SListNode** pphead, SLTDataType x);
void SListPushBack(SListNode** pphead, SLTDataType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;//头指针指向新的结点
}
//链表不为空
else
{
SListNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}注意: 链表头插函数的参数我们应该传头指针的地址,而不是头指针本身。如果为传值调用,那么形参是实参的一份临时拷贝,对形参的改变不会影响实参。
单链表头插
单链表头插时,我们申请一个新的结点,然后让新结点的指针域指向之前的第一个结点,然后让头指针指向新结点。
注意:这两步操作的顺序不可以颠倒,如果先让头指针指向了新结点,那么将不可能找到第一个结点的位置了。也不可能在找到后面的数据了。
void SListPushFront(SListNode** pphead, SLTDataType x);
void SListPushFront(SListNode** pphead, SLTDataType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}单链表尾删
演示一种错误的写法:
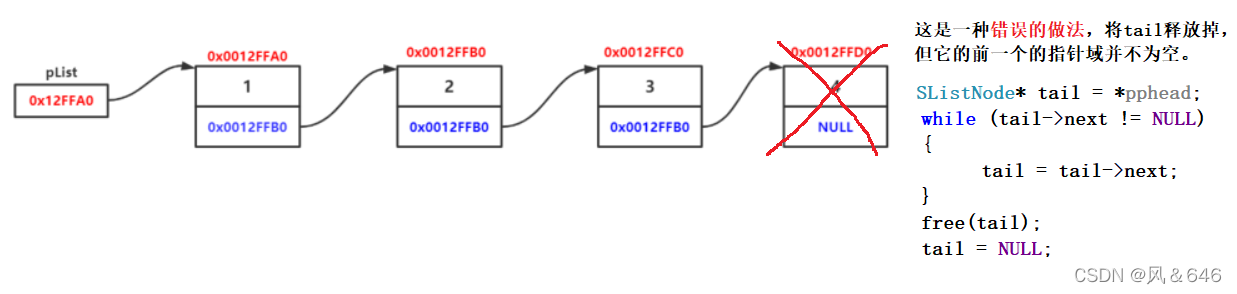
对于单链表的尾删,我们需要考虑三种情况:
1.链表为空时,不做任何处理。
2.链表只有一个结点时,释放该结点,然后将头指针置为空。
3.链表有多个结点时,有两种处理方法,详见一下代码。

代码一: 找到最后一个结点的前一个结点,释放最后一个结点。将前一个结点的指针域置为空指针。
void SListPopBack(SListNode** pphead);
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)
return;
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SListNode* prev = NULL;
SListNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
prev->next = NULL;
}
}代码二: 找到最后一个结点的前一个结点,将后一个结点释放掉,然后在置为空就可以了。
void SListPopBack(SListNode** pphead);
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)
return;
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SListNode* tail = *pphead;
while (tail->next->next != NULL)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}单链表头删
若链表为空,则不处理。若链表不为空,让头指针指向第二个结点,释放掉第一个结点。
void SListPopFront(SListNode** pphead);
void SListPopFront(SListNode** pphead)
{
assert(pphead);
if (*pphead == NULL)//链表为空
return;
else
{
SListNode* head = *pphead;
*pphead = head->next;//让头指针指针域中的地址指向头指针
free(head);//释放第一个结点
head = NULL;
}
}
在pos位置之前插入数据
若pos是第一个结点,我们直接调用之前写的头插。若pos不是第一个结点,我们找到pos位置的前一个结点,让新的结点指向地址为pos的结点,然后让前一个结点指向新结点。
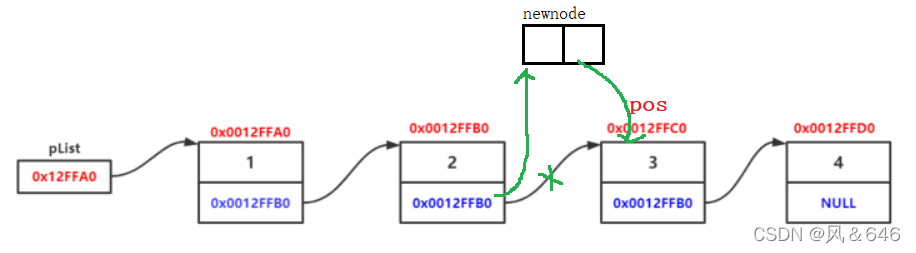
void SListInsertBefore(SListNode** pphead, SListNode* pos, SLTDataType x);
void SListInsertBefore(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(pphead);
assert(pos);
if (*pphead == pos)
{
SListPushFront(pphead,x);//头插函数
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)//找到pos的前一个结点
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
newnode->next = prev->next;//让新结点指向pos结点
prev->next = newnode;//让前一个结点指向新结点
}
}在pos位置之后插入数据
让新结点指向该位置的下一个位置,然后让该位置的结点指向新结点。
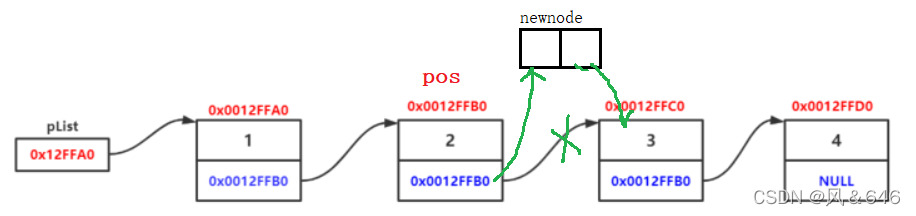
void SListInsertAfter(SListNode** pphead, SListNode* pos, SLTDataType x);
void SListInsertAfter(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}删除pos位置结点
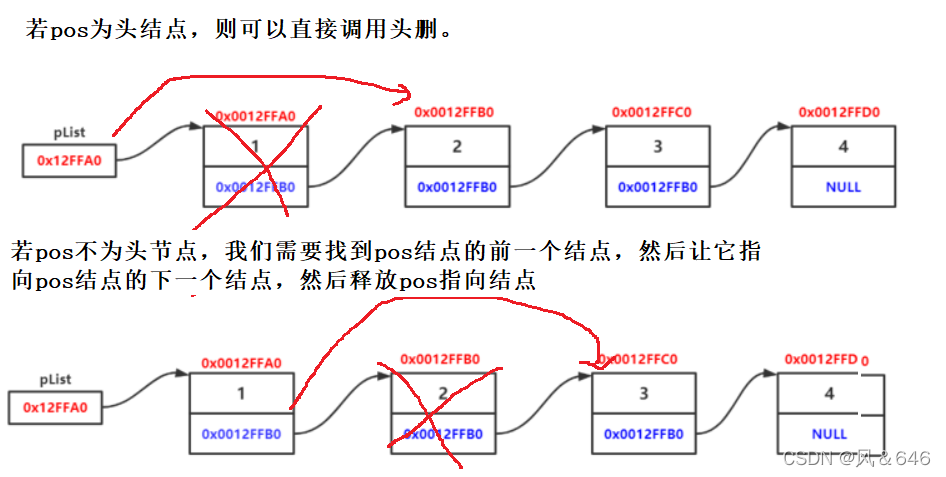
void SListErase(SListNode** pphead, SListNode* pos);
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (*pphead == pos)
{
SListPopFront(pphead);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}删除pos位置之后的结点

void SListEraseAfter(SListNode* pos);
void SListEraseAfter(SListNode* pos)
{
assert(pos);
SListNode* next = pos->next;
if (next)//如果next不为空,则条件为真
{
pos->next = next->next;//让pos指向要删除位置的后一个结点
free(next);//释放pos的下一个结点
next = NULL;
}
}销毁链表
在销毁链表时。首先我们将头指针赋值给一个新的指针,用该指针依次遍历链表,先把该结点的下一个结点的地址保存,然后在释放该结点,最后将头指针置为空。
注意: 一定要在释放该指针之前保存该指针的下一个结点的地址,否则就找不到下一个结点了。
void SListDestroy(SListNode** pphead);
void SListDestroy(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
while (cur)
{
SListNode* next = cur->next;//存放下一个结点地址
free(cur);//释放当前结点
cur = NULL;
}
*pphead = NULL;//将头指针置为空
}链表查找
SListNode* SListFind(SListNode* phead, SLTDataType x);
SListNode* SListFind(SListNode* phead, SLTDataType x)
{
SListNode* cur = phead;
while (cur != NULL)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}提示:我们在写链表的时候,尽量画图分析,帮助我们理清思路。
加载全部内容