Selenium标签定位
BGONE 人气:0背景
Selenium4使用find_element(by=By.**, value=*)来替换了原来的find_element_by_* 的方法,使用find_elements(by=By.*, value=*)来替换了原来的find_elements_by_* 的方法。
By类定义在 site-packages\selenium\webdriver\common\by.py中:
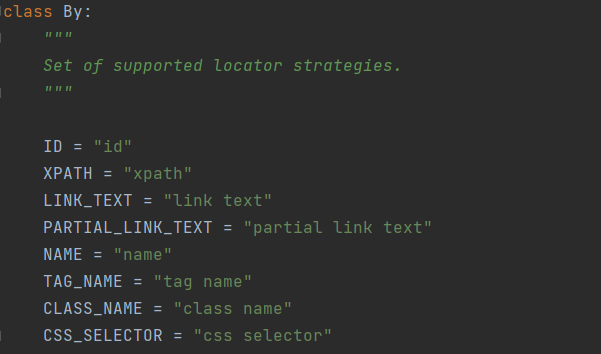
这就是Selenium4的8种定位方法
元素定位
元素本身是什么:HTML静态页面中的的一个标签
元素定位一般而言是基于元素自身所包含有的特点来进行定位的。
包括:标签的名称(决定元素是什么)、标签的属性(决定元素有什么特质),标签的文本
定位元素的方法
ID = “id”
XPATH = “xpath”
LINK_TEXT = “link text”
PARTIAL_LINK_TEXT = “partial link text”
NAME = “name”
TAG_NAME = “tag name”
CLASS_NAME = “class name”
CSS_SELECTOR = “css selector”
- id:有ID就用ID定位,基本不会重复
- name:有name可以考虑用,name类似于人的名字,虽然相对少见的值,但是容易重名
- link text:基于文本定位链接标签
- partial link text:类似于SQL中的like%,模糊查找
- tag name:基于标签名称来查找元素,大概率有多个结果,一般用于查找多个重复的内容的时候使用。
- class:基于class属性进行元素查找,非必要不推荐,重复率高
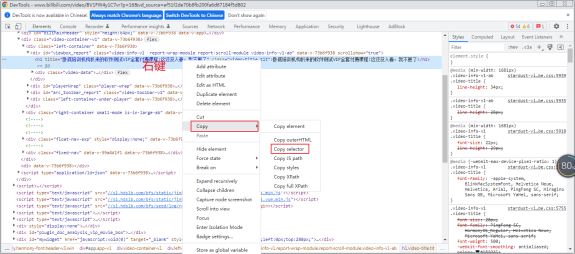
- css selector:定位界万金油,有自己的独特语法,定位语法麻烦,基于标签的class内容进行定位,使用copy
- selector确定位置
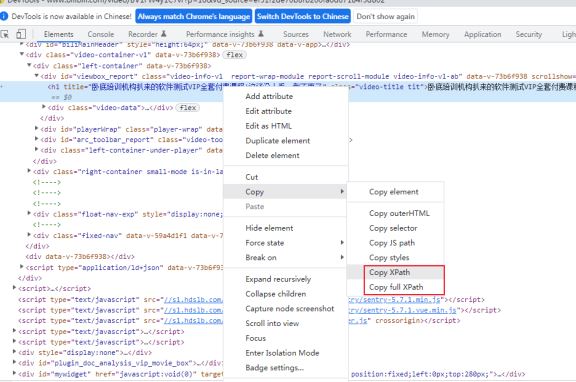
xpath:定位界万金油,有自己的独特语法,定位速度慢,基于树状结构形态定位,使用Copy XPath, Copy full
XPath来确定位置
总结:有id用id,没id用name,都不行用css/xpath,链接可以用link text。find_element元素定位如果同时有多个结果,默认返回定位的第一个结果;find_elements元素定位返回一个列表
实例
测试目的
测试Selenium4的8种元素定位方法
ID、CSS_SELECTOR
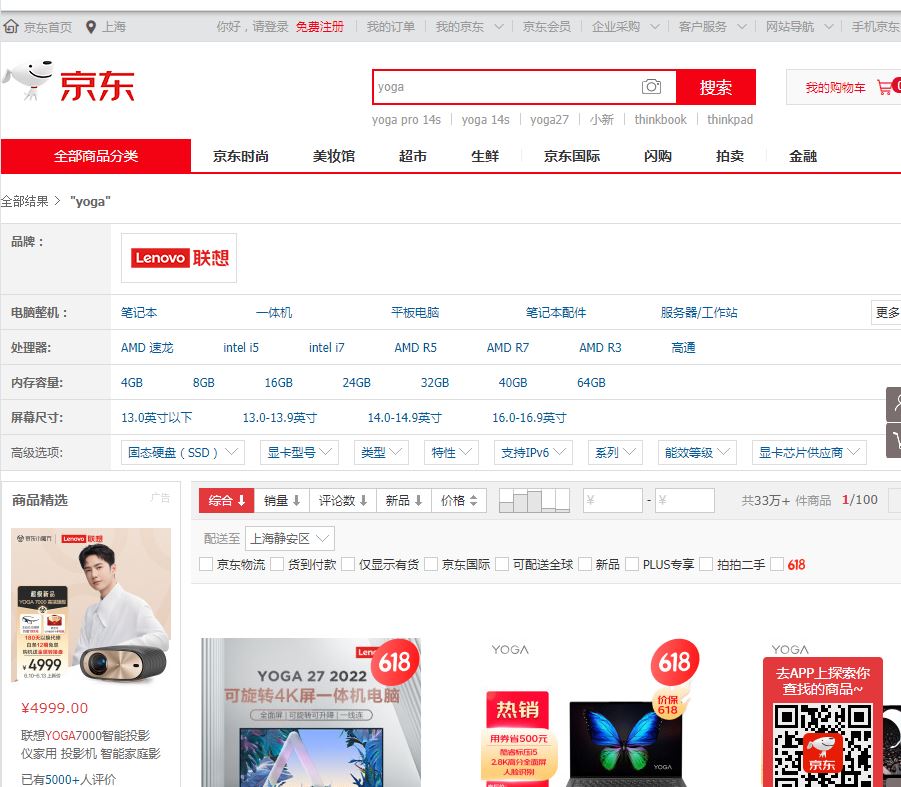
输入栏输入yoga,点击搜索
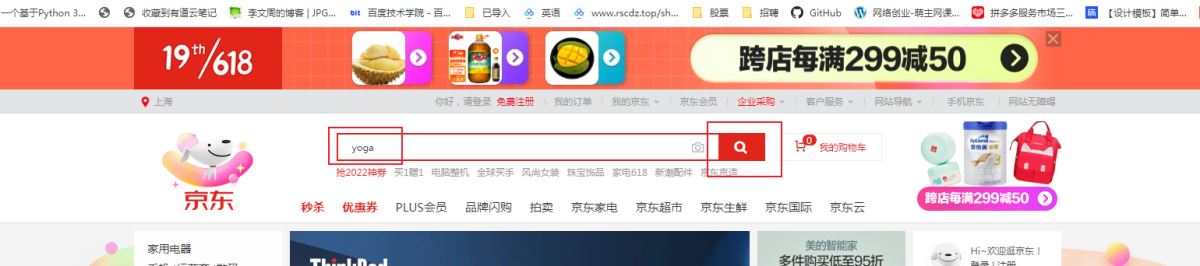
实例网站
京东

实例代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url="https://www.jd.com/")
# id
driver.find_element(by=By.ID,value="key").send_keys("yoga")
# css selector
driver.find_element(by=By.CSS_SELECTOR,value="#search > div > div.form > button").click()
time.sleep(3)
driver.quit()结果展示
NAME、LINK_TEXT、PARTIAL_LINK_TEXT
用NAME元素输入yoga,用LINK_TEXT定位how123,用PARTIAL_LINK_TEXT定位hao123

实例网站
可以自行百度
实例代码
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")
driver = webdriver.Chrome(service=service)
driver.get(url="https://www.baidu.com/")
# id
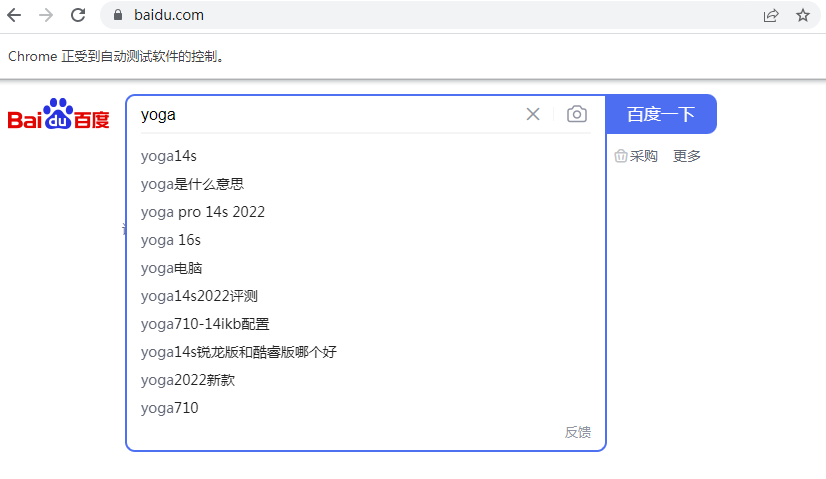
driver.find_element(by=By.NAME,value="wd").send_keys("yoga")
time.sleep(3)
driver.get(url="https://www.baidu.com/")
# link text
driver.find_element(by=By.LINK_TEXT,value="hao123").click()
time.sleep(3)
# css selector
driver.get(url="https://www.baidu.com/")
driver.find_element(by=By.PARTIAL_LINK_TEXT,value="1").click()
time.sleep(3)
driver.quit()结果展示
CSS、XPATH
点击热搜第一
实例网站
实例代码
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") driver = webdriver.Chrome(service=service) driver.get(url="https://weibo.com/newlogin?tabtype=search&openLoginLayer=0&url=") time.sleep(6) # Redirect # css selector driver.find_element(by=By.CSS_SELECTOR,value="#scroller > div.vue-recycle-scroller__item-wrapper > div:nth-child(2) > div > div > a > div > div > div.woo-box-item-flex").click() time.sleep(3) # xpath driver.get(url="https://weibo.com/newlogin?tabtype=search&openLoginLayer=0&url=") time.sleep(6) driver.find_element(by=By.XPATH,value='//*[@id="scroller"]/div[1]/div[2]/div/div/a/div/div/div[1]').click() time.sleep(3) driver.quit()
结果展示
CSDN判定图片违规,无法上传
TAG_NAME、CLASS
去除首页作弊通知弹窗
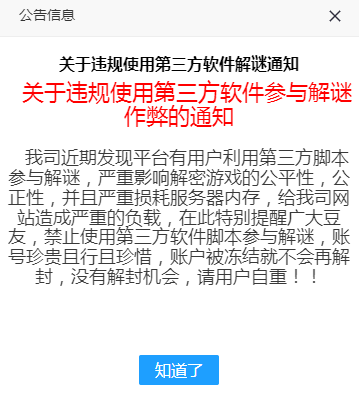
实例平台
实例代码
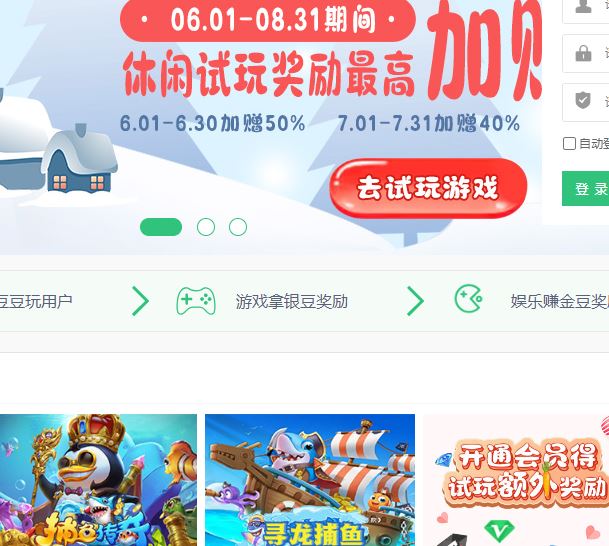
import time from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.chrome.service import Service service = Service(executable_path=r"C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe") driver = webdriver.Chrome(service=service) driver.get(url="http://doudouwan.com/") # tag name el = driver.find_elements(by=By.TAG_NAME,value="a")[83] # el2 = driver.find_elements(by=By.CLASS_NAME,value='layui-layer-btn0')[0] # for i in range(len(el)): # if el[i] == el2: # print(i) time.sleep(3) # delete all cookies in this website, and do not need to refresh driver driver.delete_all_cookies() # xpath driver.get(url="http://doudouwan.com/") time.sleep(6) driver.find_elements(by=By.CLASS_NAME,value='layui-layer-btn0')[0].click() time.sleep(3) driver.quit()
结果展示
加载全部内容