MySQL Order By排序 filesort排序
刘Java 人气:01.Order By原理
MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的。
假设有一个表,建表的sql如下:
CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR ( 100 ) NOT NULL, PRIMARY KEY ( `id` ), UNIQUE KEY `a` ( `a` ), KEY `b` ( `b` ) ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
存储过程插入10000条数据:
CREATE PROCEDURE `obtest`( ) BEGIN DECLARE i INT DEFAULT 0; DECLARE j VARCHAR ( 100 ) DEFAULT 'a'; DECLARE k VARCHAR ( 100 ) DEFAULT 'b'; DECLARE l VARCHAR ( 100 ) DEFAULT 'c'; SET i = 0; START TRANSACTION; WHILE i < 10000 DO IF MOD ( i, 10 ) = 0 THEN SET k = CONCAT( 'b', i ); END IF; IF MOD ( i, 15 ) = 0 THEN SET l = CONCAT( 'c', i ); END IF; INSERT INTO obtest ( a, b, c ) VALUES ( CONCAT( j, i ), k, l ); SET i = i + 1; END WHILE; COMMIT; END
如果不能使用索引消除排序,那么EXPLAIN展示的执行计划的Extra这个字段中的“Using filesort”表示的就是需要额外的排序操作,MySQL会给每个线程分配一块内存用于排序,称为sort_buffer。
这里的filesort有可能是内存排序,也有可能是文件排序,但它们都统称filessort。在内存中对数据进行排序,这个我相信大家都是不陌生的,如果sort_buffer_size超过了需要排序的数据量的大小,表示排序可以直接在内存中完成。
那么文件排序又是什么意思呢?实际上如果需要排序的数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。文件排序就是所谓的外部排序。所以说,MySQL的Order By的实现,就有可能利用到外部排序这种排序算法!
外部文件排序一般使用归并排序算法。MySQL将需要排序的数据分成N份,每一份单独排序后存在这些临时文件中,然后把这N个有序文件再一步步的合并成一个有序的大文件。
怎么看一个排序是否使用到了临时文件呢?我们执行下面的SQL:
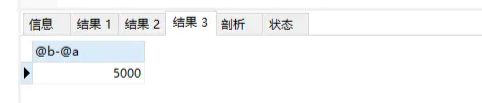
/* 打开optimizer_trace,只对本线程有效 */ SET optimizer_trace='enabled=on'; /* @a保存Innodb_rows_read的初始值 */ select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 执行语句 */ select * from obtest ORDER BY a LIMIT 1000; /* 查看 OPTIMIZER_TRACE 输出 */ select * FROM `information_schema`.`OPTIMIZER_TRACE`; /* @b保存Innodb_rows_read的当前值 */ select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read'; /* 计算Innodb_rows_read差值 */ select @b-@a;
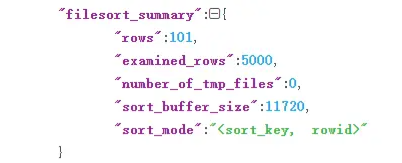
通过查看 OPTIMIZER_TRACE 的结果来确认的,你可以从 number_of_tmp_files中看到是否使用了临时文件。

number_of_tmp_files表示排序过程中使用的临时辅助文件数。可以这么简单理解,MySQL将需要排序的数据分成12份,每一份单独排序后存在这些临时文件中。然后把这12个有序文件再合并成一个有序的大文件。
examined_rows表示参与排序的行数,一共5000行,即所有数据都参与了排序。
sort_mode 里面的packed_additional_fields的意思是,排序过程对字符串做了“紧凑”处理。即使a、b、c字段的定义是varchar(50),在排序过程中还是要按照实际长度来分配空间的。
同时,最后一个查询语句select @b-@a 的返回结果是5000,表示整个执行过程只扫描了5000行。实际可能显示为5001,这是InnoDB的干扰,为了避免对结论造成干扰,可以把internal_tmp_disk_storage_engine参数设置成MyISAM。
SET GLOBAL internal_tmp_disk_storage_engine=MyISAM;
这是因为查询OPTIMIZER_TRACE这个表时,需要用到临时表,而internal_tmp_disk_storage_engine的默认值是InnoDB。如果使用的是InnoDB引擎的话,把数据从临时表取出来的时候,会让Innodb_rows_read的值加1。临时表默认大小为16M。
2.filesort排序算法
实际上文件辅助排序同样有两种算法,一种是全字段排序,另一种是rowid排序,也称为"原始排序模式(MySQL 4.1之前的)"。
全字段排序是将要查询的一行的所有字段都放入sort_buffer中,并按照指定的字段进行过排序,排序完毕之后,直接取出排序好的数据返回给客户端,因为排序后的数据包括了需要返回的所有数据,这种方法称为全字段排序。
全字段排序步骤可以归纳为:
- 读取<固定长度的排序列, 需要返回的列> 组成元组,放入sort buffer。
- 如果sort buffer满, 根据排序列执行一次quicksort, 将其写入临时文件。
- 重复1 2 步骤直到文件结束。
- 对临时文件执行归并排序。
- 从排好序的临时文件中读取需要返回的列返回给客户端即可。
上面的查询语句就是使用的全字段排序,这种排序方法只对原表的数据读了一遍,剩下的操作都是在sort_buffer和临时文件中执行的。但这个算法有一个问题,就是如果查询要返回的字段很多的话,那么sort_buffer里面要放的字段数太多,这样内存里能够同时放下的行数很少,要分成很多个临时文件,排序的性能会很差。
max_length_for_sort_data,是MySQL中专门控制用于排序的行数据的长度的一个参数,默认值是1024字节。它的意思是,如果单行的长度超过这个值,MySQL就认为单行太大,要换一个另一个rowid算法。
我们知道,上面的sql中两个字段b和d加起来长度是不会超过1024字节的,因此就会使用全字段排序。如果我们将查询返回字段改为:*,即全部返回,这些字段的总长度肯定大于1024了,此时MySQL将会使用rowid排序算法。
rowid排序算法的大概流程为:
- 读取 固定长度的排序列 + rowid组成元组,放入sort buffer。
- 如果sort buffer满, 根据排序列执行一次quicksort, 将其写入临时文件。
- 重复1 2 步骤直到文件结束。
- 对临时文件执行归并排序。
- 从排好序的临时文件中读取需要返回的列的rowid。
- 然后再根据这些id进行回表操作,查询出需要的字段值直接返回给客户端。
对比全字段排序流程会发现,rowid排序多访问了一次表的主键索引,就是步骤6,返回的结果也有变化:

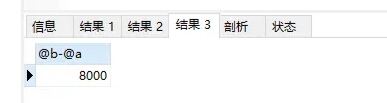
可以看到examined_rows的值还是5000,表示用于排序的数据是5000行。但是select @b-@a这个语句的值变成8000了。因为这时候除了排序过程外,在排序完成后,还要根据id去原表取值。由于语句是limit 3000,因此会多读3000行。
sort_mode变成了<sort_key, rowid>,表示参与排序的只有a和id这两个字段,即rowid排序。
number_of_tmp_files变成3了,是因为这时候参与排序的行数虽然仍然是5000行,但是每一行的数据量都变小了,因此需要排序的总数据量就变小了,需要的临时文件也相应地变少了。
总结:
如果MySQL认为内存足够大,会优先选择全字段排序,把需要的字段都放到sort_buffer中,这样排序后就会直接从内存里面返回查询结果了,不用再回到原表去取数据,但这会导致它需要多次向临时文件写入内容,增加IO操作,当需要返回的列的总长度很长时尤其明显。而如果一行的数据大小超过max_length_for_sort_data这个限制值时,才会采用rowid排序算法,这样排序过程中一次可以排序更多行,但是需要再回到原表去取数据,即需要读两次表,并且第二次读取是随机的。
3.优化排序
这也就体现了MySQL的一个设计思想:如果内存够,就要多利用内存,尽量减少磁盘访问。
从上面也能看出来,MySQL的排序操作的成本还是很高的,MySQL之所以需要生成临时表,并且在临时表上做排序操作,其原因是原来的数据都是无序的。
如果能够保证从b这个索引上取出来的行,天然就是递增排序的话,那就可以不用再排序了,这是就可以用到索引。
比如我们有如下查询:
select id,a,b from obtest ORDER BY a LIMIT 3000;
此时如果我们建立(a,b)的联合索引,则不但可以利用索引消除排序,还能够避免回表查询,一举两得!如果没有采用额外的排序手段,则没有filesort_summary的一系列数据。
另外,如果需要取出的排序数据较少,则可能使用additional_fields排序,这种方式同样不需要回表查询,但是相比于packed_additional_fields,没有进行紧密打包操作。比如:
select * from obtest ORDER BY a LIMIT 100;
如果number_of_tmp_files值为0,则可能是用到了优先队列排序算法,如果filesort_priority_queue_optimization部分的chosen=true,就表示使用了优先队列排序算法,这个过程不需要临时文件,因此对应的number_of_tmp_files是0。

因为limit所要取的数据量比较少,采用文件归并排序的话,就需要对全部数据进行排序,内存时间复杂度为O(nlogn),但由于有文件IO实际需要更多时间。而如果使用优先队列排序,实际上就是堆排序,这样的排序是一种偏序排序,能够计算出所需的最大或者最小的几个值,但是其他的数据的顺序是不确定的,实际上如果使用堆排序对所有数据排序,那么时间复杂度也是O(nlogn),但这里只需要在大量数据中取出少量有序数据,并且是内存中操作的,这样耗费的时间远小于文件归并排序。
如果limit取出的数据量小于sort_buffer_size,则采用优先队列排序。
加载全部内容