Python读取excel文件数据
Famiglistimott 人气:0一、导包
import pandas as pd import matplotlib.pyplot as plt
二、绘制简单折线
数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student。
Python的表单数据如下所示:

student的表单数据如下所示:

1、在利用pandas模块进行操作前,可以先引入这个模块,如下:
import pandas as pd
2、读取Excel文件的两种方式:
#方法一:默认读取第一个表单
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出得到的结果是一个二维矩阵,如下所示:

#方法二:通过指定表单名的方式来读取
df=pd.read_excel('lemon.xlsx',sheet_name='student')#可以通过sheet_name来指定读取的表单
data=df.head()#默认读取前5行的数据
print("获取到所有的值:\n{0}".format(data))#格式化输出得到的结果如下所示,也是一个二维矩阵:

#方法三:通过表单索引来指定要访问的表单,0表示第一个表单
#也可以采用表单名和索引的双重方式来定位表单
#也可以同时定位多个表单,方式都罗列如下所示
df=pd.read_excel('lemon.xlsx',sheet_name=['python','student'])#可以通过表单名同时指定多个
# df=pd.read_excel('lemon.xlsx',sheet_name=0)#可以通过表单索引来指定读取的表单
# df=pd.read_excel('lemon.xlsx',sheet_name=['python',1])#可以混合的方式来指定
# df=pd.read_excel('lemon.xlsx',sheet_name=[1,2])#可以通过索引 同时指定多个
data=df.values#获取所有的数据,注意这里不能用head()方法哦~
print("获取到所有的值:\n{0}".format(data))#格式化输出三、pandas操作Excel的行列
1、读取指定的单行,数据会存在列表里面
#1:读取指定行
df=pd.read_excel('lemon.xlsx')#这个会直接默认读取到这个Excel的第一个表单
data=df.ix[0].values#0表示第一行 这里读取数据并不包含表头,要注意哦!
print("读取指定行的数据:\n{0}".format(data))得到的结果如下所示:

2、读取指定的多行,数据会存在嵌套的列表里面
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2]].values#读取指定多行的话,就要在ix[]里面嵌套列表指定行数
print("读取指定行的数据:\n{0}".format(data))3、读取指定的行列
df=pd.read_excel('lemon.xlsx')
data=df.ix[1,2]#读取第一行第二列的值,这里不需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))4、读取指定的多行多列值
df=pd.read_excel('lemon.xlsx')
data=df.ix[[1,2],['title','data']].values#读取第一行第二行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))5、获取所有行的指定列
df=pd.read_excel('lemon.xlsx')
data=df.ix[:,['title','data']].values#读所有行的title以及data列的值,这里需要嵌套列表
print("读取指定行的数据:\n{0}".format(data))6、获取行号并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出行号列表",df.index.values)
输出结果是:
输出行号列表 [0 1 2 3]7、获取列名并打印输出
df=pd.read_excel('lemon.xlsx')
print("输出列标题",df.columns.values)
运行结果如下所示:
输出列标题 ['case_id' 'title' 'data']8、获取指定行数的值
df=pd.read_excel('lemon.xlsx')
print("输出值",df.sample(3).values)#这个方法类似于head()方法以及df.values方法
输出值
[[2 '输入错误的密码' '{"mobilephone":"18688773467","pwd":"12345678"}']
[3 '正常充值' '{"mobilephone":"18688773467","amount":"1000"}']
[1 '正常登录' '{"mobilephone":"18688773467","pwd":"123456"}']]9、获取指定列的值
df=pd.read_excel('lemon.xlsx')
print("输出值\n",df['data'].values)四、pandas处理Excel数据成为字典
我们有这样的数据
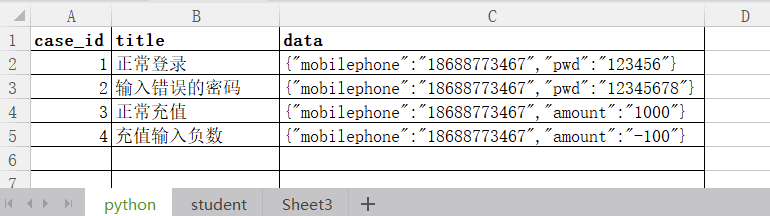
处理成列表嵌套字典,且字典的key为表头名。
实现的代码如下所示:
df=pd.read_excel('lemon.xlsx')
test_data=[]
for i in df.index.values:#获取行号的索引,并对其进行遍历:
#根据i来获取每一行指定的数据 并利用to_dict转成字典
row_data=df.ix[i,['case_id','module','title','http_method','url','data','expected']].to_dict()
test_data.append(row_data)
print("最终获取到的数据是:{0}".format(test_data))最后得到的结果是:
最终获取到的数据是:
[{'title': '正常登录', 'case_id': 1, 'data': '{"mobilephone":"18688773467","pwd":"123456"}'},
{'title': '输入错误的密码', 'case_id': 2, 'data': '{"mobilephone":"18688773467","pwd":"12345678"}'},
{'title': '正常充值', 'case_id': 3, 'data': '{"mobilephone":"18688773467","amount":"1000"}'},
{'title': '充值输入负数', 'case_id': 4, 'data': '{"mobilephone":"18688773467","amount":"-100"}'}]五、绘制简单折线图
所用数据:

# -*- coding: utf-8 -*-
"""
Created on Tue Sep 29 18:24:14 2020
@author: chenj
"""
# 导入 pandas 和 matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# 读取文件
# =============================================================================
# 可能遇到的问题 路径分隔符 建议用“/”或“\\” 读取桌面文件时 用“\”可能会失败
# =============================================================================
data_source = pd.read_excel('F:/南师2020作业/人工智能/datas.xlsx')
# 函数plot()尝试根据数字绘制出有意义的图形
print(data_source['datas'])
plt.plot(data_source['datas'])
六、绘制简单散点图
使用scatter绘制散点图并设置其样式 1、绘制单个点,使用函数scatter,并向它传递x,y坐标,并可使用参数s指定点的大小
plt.scatter(2,4,s=20)
2、绘制一系列点,向scatter传递两个分别包含x值和y值的列表
x_values=[1,2,3,4,5] y_values=[1,4,9,16,25] plt.scatter(x_values,y_values,s=20)
3、设置坐标轴的取值范围:函数axis()要求提供四个值,x,y坐标轴的最大值和最小值
plt.axis([0,1100,0,1100000])
4、使用参数edgecolor在函数scatter中设置数据点的轮廓
plt.scatter(x_values,y_values,edgecolor='black',s=20)
当参数值为'none'时不使用轮廓
5、向scatter传递参数c,指定要使用的颜色
可使用颜色名称,或者使用RGB颜色模式自定义颜色,元组中包含三个0~1之间的小数值,分别表示红绿蓝颜色分量。
plt.scatter(x_values,y_values,c=(0,0,0.8),edgecolor='none',s=20)为由浅蓝色组成的散点图
6、使用颜色映射
颜色映射是一系列颜色,它们从起始颜色渐变到结束颜色,在可视化中颜色映射用于突出数据的规律。
例如,可用较浅的颜色表示较小的数值,较深的颜色表示较大的数值。
模块pyplot内置了一组颜色映射,要使用颜色映射,需要告诉pyplot如何设置数据集中每个点的颜色。
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,s=40)
plt.title("Square numbers",fontsize=24)我们将参数c设置成了一个y值列表,并使用参数cmap告诉pyplot使用哪个颜色映射。这些代
码将y值较小的点显示为浅蓝色,并将y值较大的点显示为深蓝色。
7、自动保存图表:使用函数plt.savefig()
plt.savefig('D:/www/figure.png',bbox_inches='tight')第一个参数是文件名,第二个参数指定将图表多余的空白区域减掉,如果要保留图表周围多余的空白区域,可省略这个实参。
8、设置绘图窗口尺寸
函数figure用于指定图表的宽度、高度、分辨率和背景色。
形参figsize指定一个元组,向matplotlib指出绘图窗口的尺寸,单位为英寸。
形参dpi向figure传递分辨率,默认为80
plt.figure(dpi=128,figsize=(10,6))
9、实例程序
#a.py
import matplotlib.pyplot as plt
x_values=list(range(1,1001))
y_values=[x**2 for x in x_values]
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,s=40)
plt.title("Square numbers",fontsize=24)
plt.xlabel("value",fontsize=24)
plt.ylabel("Square of Value",fontsize=24)
plt.tick_params(axis='both',labelsize=14)
plt.axis([0,1100,0,1100000])
plt.savefig('D:/www/figure.png',bbox_inches='tight')
plt.show()# 导入 pandas 和 matplotlib
import pandas as pd
import matplotlib.pyplot as plt
# 导入中文显示库函数
from matplotlib.font_manager import FontProperties
font_set = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=15)
# 读取文件
df = pd.read_excel("F:/南师2020作业/人工智能/datas.xlsx")
# 输出数据行数
print("数据行数:" , len(df))
'''
由于只有一列数据我们使用 excel 行号作为 x 值的列表
用range()函数来创建一个列表 [1,24)
range()函数 遍历数字序列
'''
x = list(range(1,len(df)+1)) #[1,24)
# 读取指定的单列也就是 datas列,数据会存在列表里面
y = df['datas']
# for 循环输出数据行数
for a in (list(range(1,len(df)+1))):
print('行号:'+str(a)) #将int类型的a 转换为字符串
#设置 x值 和y值的列表
plt.scatter(x,y)
# 图表名称
plt.title('散点图',fontproperties=font_set)
# 设置x轴名称
plt.xlabel("X")
# 设置y轴名称
plt.ylabel("Y")
plt.show()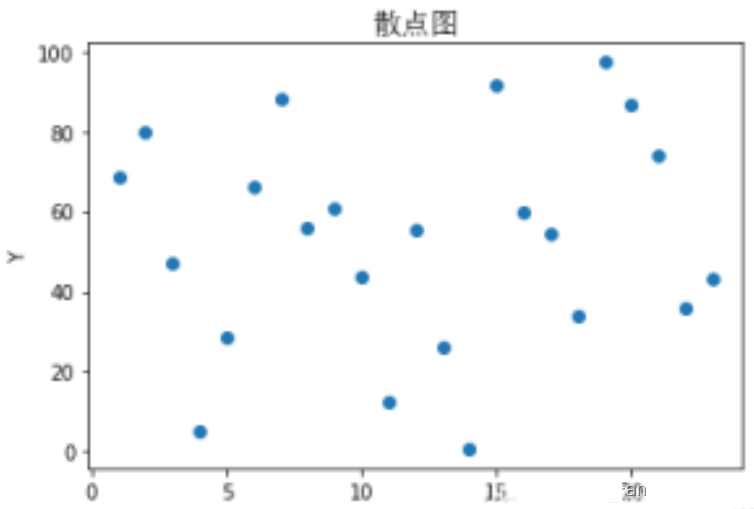
加载全部内容