Python的pandas数据处理
Joy_joye 人气:0前言
工作中经常会使用到将宽表变成窄表,例如这样的形式
| 编号 | 编码 | 单位1 | 单位2 | 单位3 | 单位4 | ... | ... | ... | ... | ... | ... |
| 1 | 编码1... | 数量... | 数量... | 数量... | 数量... | ... | ... | ... | ... | ... | ... |
| 2 | 编码2... | 数量... | 数量... | 数量... | 数量... | ... | ... | ... | ... | ... | ... |
然而工作中,这样查看数据不够方便,往往需要窄表的形式,如下:
| 编码 | 单位 | 数量 |
| 编码1 | 单位1 | 数量1 |
| 编码2 | 单位2 | 数量2 |
| 编码3 | 单位3 | 数量3 |
| ...... | ...... | ...... |
尝试使用Excel中的lookup函数进行填充,较为麻烦还不能直接实现功能,刚好在自学Python,就查阅了资料,看看能不能使用Python强大的数据处理功能来实现这个需求。
pandas简介:pandas=pannel data+ data analysis;最初被作为金融数据分析工具而开发出来的,pandas为时间序列分析提供了很好的支持。同是也能够灵活处理缺失数据,为数据分析操作提供了更为便捷的手段。
话不多说,直接上jupyter代码。
1.引入包
供处理分析使用,这步so easy!
import pandas as pd import numpy as np import os
2.加载数据并显示。常规操作。
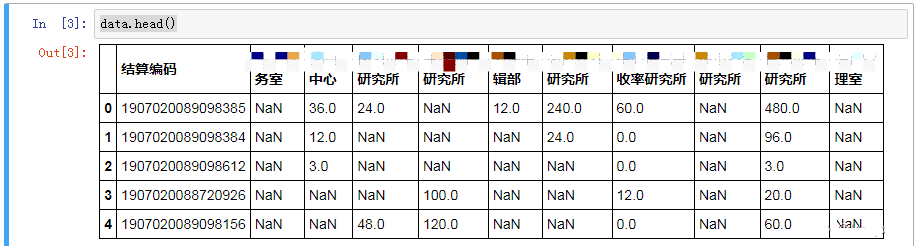
data=pd.read_excel('test.xls')
data.head()自己的测试数据存在test.xls中,这个文件存储在路径不必考虑,直接将原始存储的文件在jupyter中点upload上传到里根目录里就可以。
显示出来的,结果如图所示:
3.关键操作,将宽表转换为窄表
pd.set_option('display.max_rows', None)
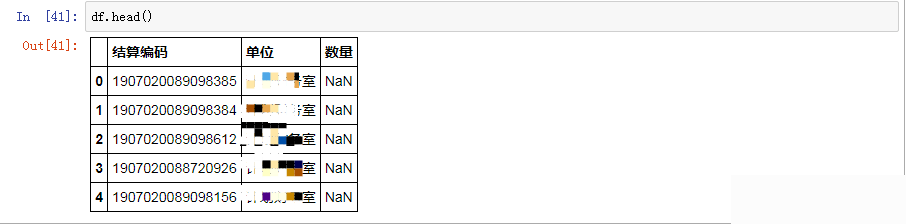
df=pd.melt(data,id_vars="结算编码",var_name="单位",value_name="数量")
df.head()显示结果如下, 可以看到数据显示不全,还有空值,需要进一步进行处理操作。
4.对空值进行处理
pd.set_option('display.max_rows', None)
#删除所有值为空的行
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
#how字段可选有any和all,any表示只要有空值出现就删除,all表示全部为空值才删除;inplace字段表示是否替换掉原本的数据
#删除所有值为空的列
df.dropna(axis="columns",how="all",inplace=False)
df.dropna()处理后的结果可以看到,数据显示齐全,并已过滤处理掉了空值。

5.导出存储到Excel中
file_dir = 'D:/program/write/'
exists = os.path.exists(file_dir)
if not exists:
os.makedirs(file_dir)
df["结算编码"] = df["结算编码"].astype(str) #设置单元格格式
df.dropna().to_excel(os.path.join(file_dir,"result3.xlsx"), sheet_name="处理结果")处理后的存储结果:

结论:Python对数据处理分析真的操作简单高效,后续可以多多尝试使用Python来简化办公繁杂的程序,提升工作效率。
加载全部内容