Vue3响应式原理
SunsetFeng 人气:0一、简介
本章内容主要通过具体的简单示例来分析Vue3是如何实现响应式的。理解本章需要了解Vue3的响应式对象。只注重原理设计层面,细节不做太多讲解。
二、响应核心
1.核心源码
export class ReactiveEffect<T = any> {
//是否激活
active = true
//依赖列表
deps: Dep[] = []
// can be attached after creation
computed?: boolean
//是否允许递归
allowRecurse?: boolean
onStop?: () => void
// dev only
onTrack?: (event: DebuggerEvent) => void
// dev only
onTrigger?: (event: DebuggerEvent) => void
constructor(
public fn: () => T,
public scheduler: EffectScheduler | null = null,
scope?: EffectScope | null
) {
//将自身添加到一个全局的EffectScope容器中
recordEffectScope(this, scope)
}
run() {
if (!this.active) {
//没有激活,直接调用回调方法
return this.fn()
}
//栈中不存在当前对象
if (!effectStack.includes(this)) {
try {
//推入栈顶,并且置为全局激活对象
effectStack.push((activeEffect = this))
//开启依赖收集开关
enableTracking()
//位操作符:用于优化
trackOpBit = 1 << ++effectTrackDepth
//源码中maxMarkerBits取30 猜测是因为整数位运算时是按照32位计算 当1<<31时为负值了,后续负值的位运算得不到预期结果 所以取的最大30
if (effectTrackDepth <= maxMarkerBits) {
//将当前依赖列表的所有依赖置为"已经收集"
initDepMarkers(this)
} else {
//不采用优化模式,使用老流程,直接移除依赖的全部状态
cleanupEffect(this)
}
//调用回调
return this.fn()
} finally {
if (effectTrackDepth <= maxMarkerBits) {
//断掉依赖关联
finalizeDepMarkers(this)
}
//重置位操作状态
trackOpBit = 1 << --effectTrackDepth
//重置依赖收集状态
resetTracking()
//栈顶出栈
effectStack.pop()
const n = effectStack.length
activeEffect = n > 0 ? effectStack[n - 1] : undefined
}
}
}
stop() {
if (this.active) {
cleanupEffect(this)
if (this.onStop) {
this.onStop()
}
this.active = false
}
}
}
上述ReactiveEffect对象,其实需要关注的就是一个run方法,这个方法设计得十分巧妙,所有动态响应的本质其实都是通过调用run方法实现的。
比如如下代码:
let dummy
const counter = reactive({ num: 0 })
let innerfunc = () => dummy = counter.num;
effect(innerfunc)
//下面的赋值,最终会执行innerfunc,所以dummy会变成7
counter.num = 7
可能会有疑惑,上述代码并没有出现ReactiveEffect类型的对象,它其实是在effect方法中创建的,我们接下来分析下effect方法。
export function effect<T = any>(
fn: () => T,
options?: ReactiveEffectOptions
): ReactiveEffectRunner {
if ((fn as ReactiveEffectRunner).effect) {
fn = (fn as ReactiveEffectRunner).effect.fn
}
//创建对象并传参
const _effect = new ReactiveEffect(fn)
if (options) {
extend(_effect, options)
if (options.scope) recordEffectScope(_effect, options.scope)
}
if (!options || !options.lazy) {
//执行
_effect.run()
}
const runner = _effect.run.bind(_effect) as ReactiveEffectRunner
runner.effect = _effect
return runner
}
这个方法的简单用法很简单,就是创建一个ReactiveEffect类型对象,然后执行run方法。
可能对于recordEffectScope方法有疑惑,其实这个方法和响应式无关,它的主要作用是将一个ReactiveEffect对象放入一个effectScope容器对象内,这个容器对象可以方便快捷的对容器内所有的ReactiveEffect对象和其子effectScope调用stop方法。只关注响应式的话可以不作考虑。
2.逐步分析上述示例代码
let dummy
//步骤1:创建一个响应式对象
const counter = reactive({ num: 0 })
let innerfunc = () => dummy = counter.num;
//步骤2:调用effect方法
effect(innerfunc)
//步骤3:修改响应式对象数据
counter.num = 7
上述的测试代码看似就3个步骤,其实内部做的东西非常多,我们来跟踪下运行流程。
步骤1:这一步很简单,就是单纯的创建一个Proxy对象,此时counter对象变成响应式的。
步骤2:effect方法里面最终调用的是run方法,而run方法主要是将自身挂载到全局激活并入栈,此时调用回调方法。回调方法此时为上面innerfunc方法,调用这个方法会读取counter.num属性,读取响应式对象的属性会调用代理拦截处理的get方法,在get方法里面,会收集依赖。此时将依赖存于栈顶的那个ReactiveEffect对象的deps属性中。
步骤3:当响应式对象的属性修改后,会触发依赖更新,由于触发更新的依赖列表里面存在effect方法里面创建的ReactiveEffect对象,所以会重新调用其run方法,在这儿也就会调用innerfunc方法。所以dummy属性就会跟随counter.num属性的变化而变化
备注:上述三步骤中,提及了收集依赖和触发依赖更新。接下来我们便看一下是如何收集依赖和触发依赖更新的。
3.收集依赖和触发依赖更新
(1).收集依赖
export function track(target: object, type: TrackOpTypes, key: unknown) {
//是否允许收集
if (!isTracking()) {
return
}
//对象map
let depsMap = targetMap.get(target)
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()))
}
//依赖map
let dep = depsMap.get(key)
if (!dep) {
depsMap.set(key, (dep = createDep()))
}
const eventInfo = __DEV__
? { effect: activeEffect, target, type, key }
: undefined
//收集依赖
trackEffects(dep, eventInfo)
}
export function trackEffects(
dep: Dep,
debuggerEventExtraInfo?: DebuggerEventExtraInfo
) {
let shouldTrack = false
if (effectTrackDepth <= maxMarkerBits) {
if (!newTracked(dep)) {
//本一轮调用新收集的依赖
dep.n |= trackOpBit // set newly tracked
//是否应该被收集
shouldTrack = !wasTracked(dep)
}
} else {
// Full cleanup mode.
shouldTrack = !dep.has(activeEffect!)
}
if (shouldTrack) {
//收集依赖
dep.add(activeEffect!)
activeEffect!.deps.push(dep)
if (__DEV__ && activeEffect!.onTrack) {
activeEffect!.onTrack(
Object.assign(
{
effect: activeEffect!
},
debuggerEventExtraInfo
)
)
}
}
}
上述代码是收集依赖的核心代码。看过我响应式对象文章的话,应该会注意到,在涉及“读”相关操作时,就会调用track方法来收集依赖。此时就是调用的上述track方法。track方法很简单,主要是找到对应的依赖列表,如果没有就创建一个依赖列表。
trackEffects里面先只需要关注收集依赖的逻辑,可以很明显的看到,里面就是一个依赖的双向添加。至于上面的那些逻辑,最主要的目的是防止重复添加依赖,我会在后面的优化环节详细讲。
依赖模型存储模型大致如下:
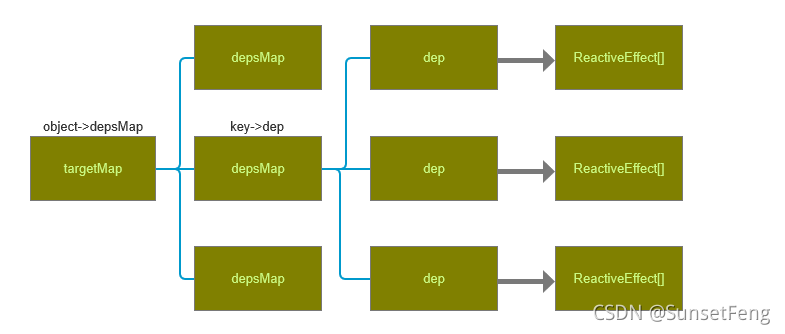
(2).触发依赖更新
export function trigger(
target: object,
type: TriggerOpTypes,
key?: unknown,
newValue?: unknown,
oldValue?: unknown,
oldTarget?: Map<unknown, unknown> | Set<unknown>
) {
//获取依赖map
const depsMap = targetMap.get(target)
if (!depsMap) {
// never been tracked
return
}
let deps: (Dep | undefined)[] = []
if (type === TriggerOpTypes.CLEAR) {
// collection being cleared
// trigger all effects for target
deps = [...depsMap.values()]
} else if (key === 'length' && isArray(target)) {
depsMap.forEach((dep, key) => {
if (key === 'length' || key >= (newValue as number)) {
deps.push(dep)
}
})
} else {
// schedule runs for SET | ADD | DELETE
if (key !== void 0) {
deps.push(depsMap.get(key))
}
// also run for iteration key on ADD | DELETE | Map.SET
switch (type) {
case TriggerOpTypes.ADD:
if (!isArray(target)) {
deps.push(depsMap.get(ITERATE_KEY))
if (isMap(target)) {
deps.push(depsMap.get(MAP_KEY_ITERATE_KEY))
}
} else if (isIntegerKey(key)) {
// new index added to array -> length changes
deps.push(depsMap.get('length'))
}
break
case TriggerOpTypes.DELETE:
if (!isArray(target)) {
deps.push(depsMap.get(ITERATE_KEY))
if (isMap(target)) {
deps.push(depsMap.get(MAP_KEY_ITERATE_KEY))
}
}
break
case TriggerOpTypes.SET:
if (isMap(target)) {
deps.push(depsMap.get(ITERATE_KEY))
}
break
}
}
const eventInfo = __DEV__
? { target, type, key, newValue, oldValue, oldTarget }
: undefined
if (deps.length === 1) {
if (deps[0]) {
if (__DEV__) {
triggerEffects(deps[0], eventInfo)
} else {
triggerEffects(deps[0])
}
}
} else {
const effects: ReactiveEffect[] = []
for (const dep of deps) {
if (dep) {
effects.push(...dep)
}
}
if (__DEV__) {
triggerEffects(createDep(effects), eventInfo)
} else {
triggerEffects(createDep(effects))
}
}
}
export function triggerEffects(
dep: Dep | ReactiveEffect[],
debuggerEventExtraInfo?: DebuggerEventExtraInfo
) {
// spread into array for stabilization
for (const effect of isArray(dep) ? dep : [...dep]) {
if (effect !== activeEffect || effect.allowRecurse) {
if (__DEV__ && effect.onTrigger) {
effect.onTrigger(extend({ effect }, debuggerEventExtraInfo))
}
if (effect.scheduler) {
effect.scheduler()
} else {
//只需要关注这儿
effect.run()
}
}
}
}
trigger方法在响应式对象的"写"操作中调用,这个方法整体上只是根据不同的依赖更新类型,将依赖添加进一个依赖数组里面,最终通过triggerEffects方法更新这个依赖数组里面的依赖。
在triggerEffects方法里面,暂时只需要关注effect.run即可,此时调用的是ReactiveEffect关联的那个回调方法,这时候也就正确的响应式变化了。
至于effect.scheduler,我会在后续的计算属性篇章中讲到,这个方法是给计算属性用的。
三、V3.2的响应式优化
上述篇幅只讲述了一个整体的响应式变化原理,接下来介绍一下V3.2带来的响应式性能优化。我们先看一下Dep类型的定义
export type Dep = Set<ReactiveEffect> & TrackedMarkers
/**
* wasTracked and newTracked maintain the status for several levels of effect
* tracking recursion. One bit per level is used to define whether the dependency
* was/is tracked.
*/
type TrackedMarkers = {
/**
* wasTracked
*/
w: number
/**
* newTracked
*/
n: number
}
可以看到,依赖列表不是一个简简单单的Set集合,它还存在2个用于辅助的属性。我们创建依赖也是通过createDep方法,实现如下:
export const createDep = (effects?: ReactiveEffect[]): Dep => {
const dep = new Set<ReactiveEffect>(effects) as Dep
dep.w = 0
dep.n = 0
return dep
}
我在这儿先说明一下这2个属性的作用。w属性用于判断依赖是否已经被收集,n属性用于判断依赖在本次调用中是否用到。可能现在还对此有疑惑,我用以下一个简单示例来解释。
let status = true;
let dummy
const depA = reactive({ num: 0 })
const depB = reactive({ num: 10 })
let innerfunc = () => {
dummy = depA.num
if(status){
dummy += depB.num
status = false
}
console.log(dummy);
}
effect(innerfunc)
depA.num = 7
depB.num = 20
//输出为 10 7
我们来分析以下上述代码的流程,首先调用effect方法,会执行一次关联的innerfunc,此时读取了depA和depB的num属性,所以此时ReactiveEffect对象里面的deps属性存在2个依赖,并且输出10。当修改depA.num属性时,会触发run方法,此时关注以下代码:
if (effectTrackDepth <= maxMarkerBits) {
//将当前依赖列表的所有依赖置为"已经收集"
initDepMarkers(this)
} else {
//不采用优化模式,使用老流程,直接移除依赖的全部状态
cleanupEffect(this)
}
因为调用effect方法时,收集过一次依赖,所以initDepMarkers方法将所有的依赖都标记为已经收集。在run方法最后,会调用innerfunc方法。在innerfunc方法中,这一次调用中又会去收集依赖,此时关注trackEffects中的以下代码:
if (effectTrackDepth <= maxMarkerBits) {
if (!newTracked(dep)) {
//本一轮调用新收集的依赖
dep.n |= trackOpBit // set newly tracked
//是否应该被收集
shouldTrack = !wasTracked(dep)
}
} else {
// Full cleanup mode.
shouldTrack = !dep.has(activeEffect!)
}
在run方法中,有一个同样的判断effectTrackDepth <= maxMarkerBits,这个判断是用于控制是否优化的,后面会讲为什么会存在这个判断以及为什么maxMarkerBits的取值为30。
在这个收集逻辑中,会将本次回调中第一次使用到的依赖置为"新增依赖",我们在看innerfunc,此时只会使用到depA,不会使用到depB,因此之前存在的关于depB对象的依赖在本次调用中没有用到。
shouldTrack属性表示依赖是否应该被收集,如果没有收集,则被收集。此时innerfunc里面输出的dummy为7。
接下来关注run里面的以下代码:
if (effectTrackDepth <= maxMarkerBits) {
//断掉依赖关联
finalizeDepMarkers(this)
}
//重置位操作状态
trackOpBit = 1 << --effectTrackDepth
//重置依赖收集状态
resetTracking()
//栈顶出栈
effectStack.pop()
const n = effectStack.length
activeEffect = n > 0 ? effectStack[n - 1] : undefined
上述代码存在于run方法里面的finally关键字内,当innerfunc执行完后,里面就会执行这里。首先便会根据判断通过finalizeDepMarkers方法去断掉依赖关联。
我们看以下方法的实现:
export const initDepMarkers = ({ deps }: ReactiveEffect) => {
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].w |= trackOpBit // set was tracked
}
}
}
export const finalizeDepMarkers = (effect: ReactiveEffect) => {
const { deps } = effect
if (deps.length) {
let ptr = 0
for (let i = 0; i < deps.length; i++) {
const dep = deps[i]
if (wasTracked(dep) && !newTracked(dep)) {
dep.delete(effect)
} else {
deps[ptr++] = dep
}
// clear bits
dep.w &= ~trackOpBit
dep.n &= ~trackOpBit
}
deps.length = ptr
}
}
这2个方法巧妙的通过位运算将调用分层。一开始将存在的依赖打上收集标签,如果在本层中没有使用到,则断掉依赖关联。当设置depB.num = 20时,首先会找到依赖列表,由于依赖列表中已经不存在ReactiveEffect对象了,所以不会触发依赖更新,此时不会有新的输出。
这儿是一个优化,断掉不必要的关联依赖,减少方法的调用。但我们在写类似代码时必须非常小心,由于断掉了依赖关联,有可能会因为写法不规范导致响应失效的情况。
接下来解释为什么要使用位运算,以及保留不走位运算的逻辑。
关注以下代码:
function cleanupEffect(effect: ReactiveEffect) {
const { deps } = effect
if (deps.length) {
for (let i = 0; i < deps.length; i++) {
deps[i].delete(effect)
}
deps.length = 0
}
}
当每次触发依赖更新时,如果都调用以上方法,会涉及大量的集合删减操作。
我没看过Set集合的实现,但无非就是数组或者链表。如果使用数组,增删操作会导致数组扩容或者移位,频繁操作会耗费大量性能,如果是链表,也要经过一次查找,大量的调用是会消耗性能的。
那么为什么又要保留这个方法呢,这是因为js引擎在进行整数位运算时几乎都是按32位运算的,1 << 31后为负值,得不到预期结果,因此保留原逻辑。但其实这个逻辑几乎不可能调到,如果真调用到这个原始逻辑,我只能说得检查一下代码是否规范了。
四、后话
关于响应式就介绍到这儿,个人理解,希望能给大家一个参考,也希望大家多多支持。
加载全部内容